Downloaded 83 times

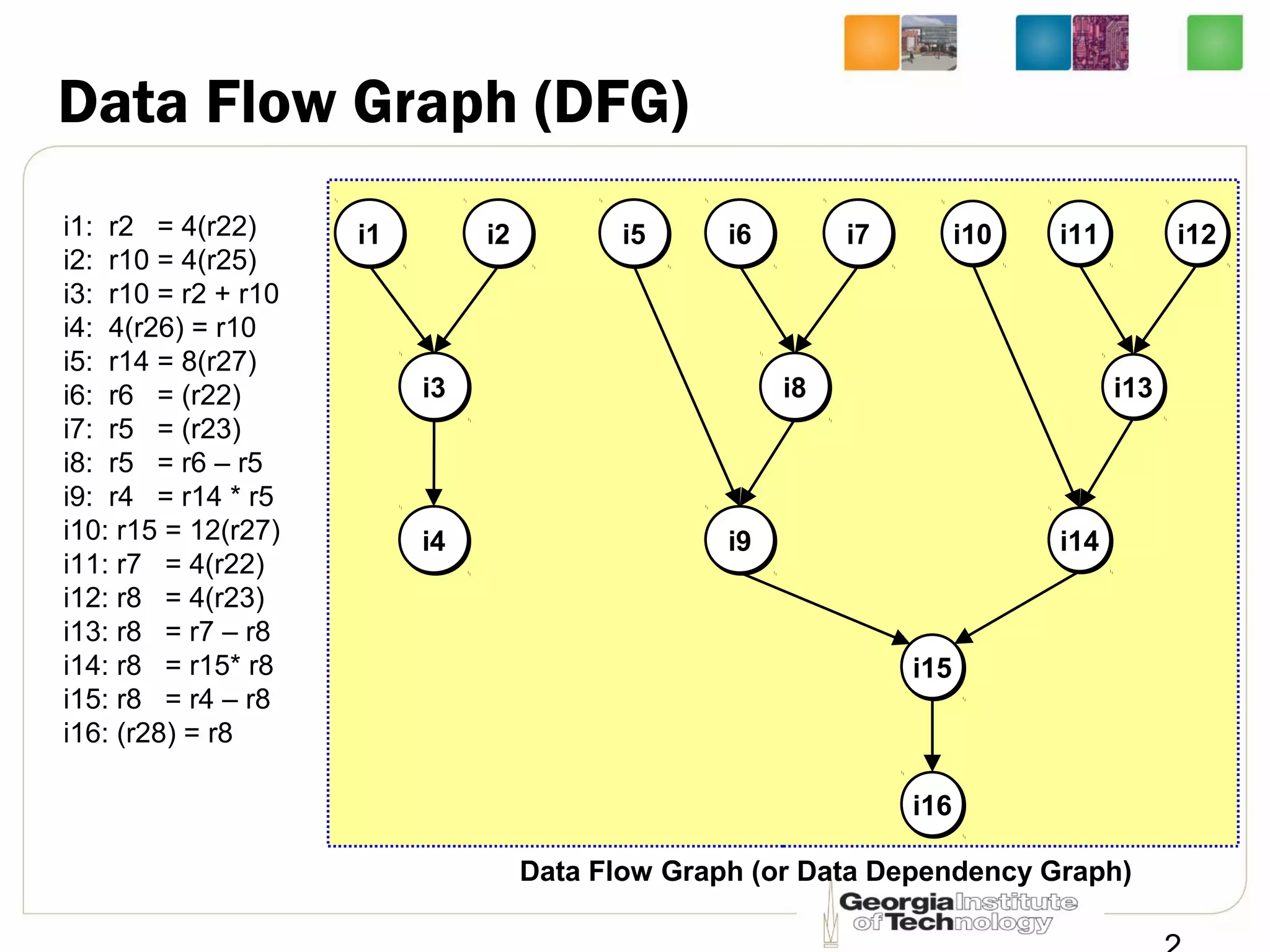


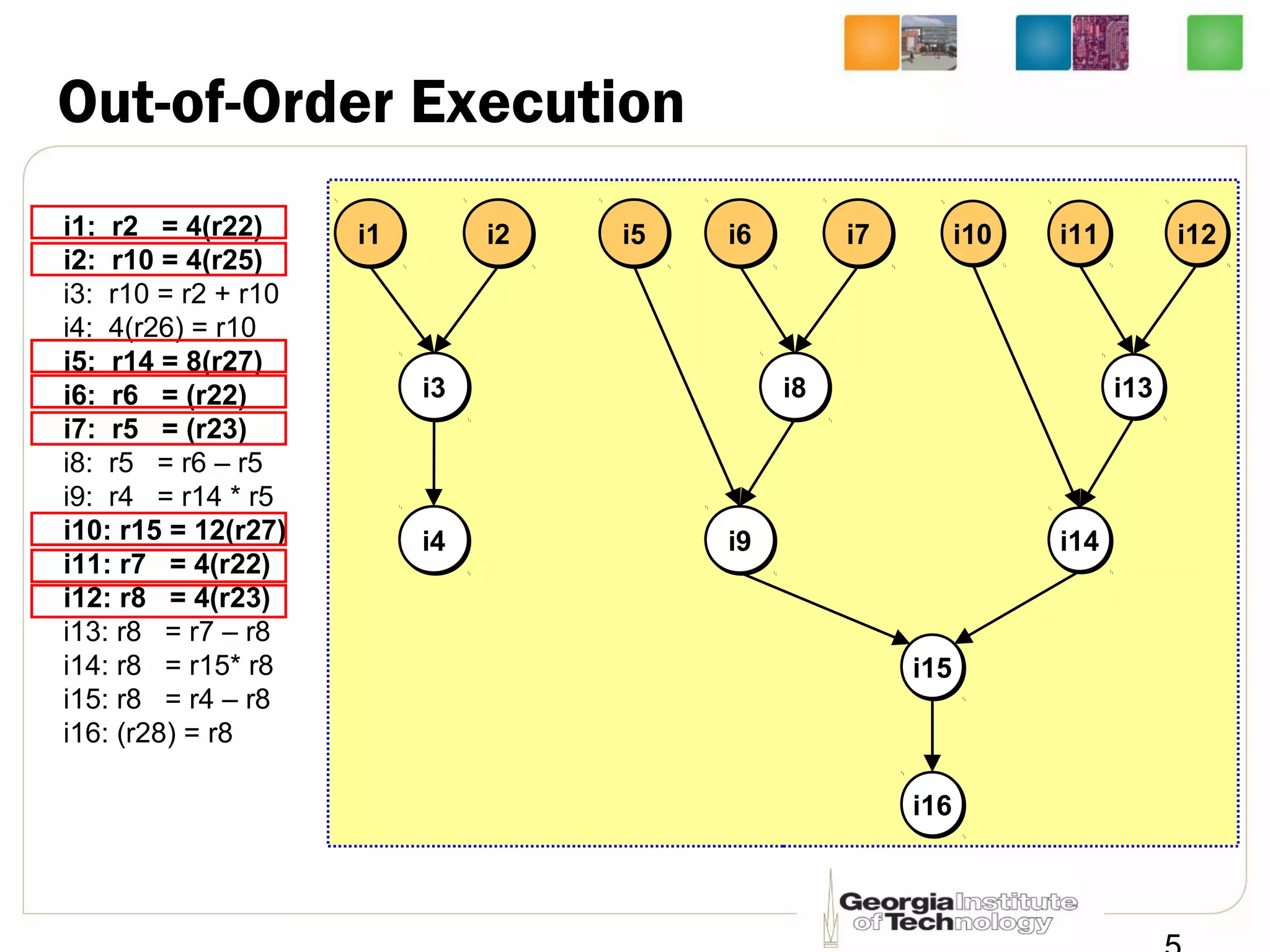


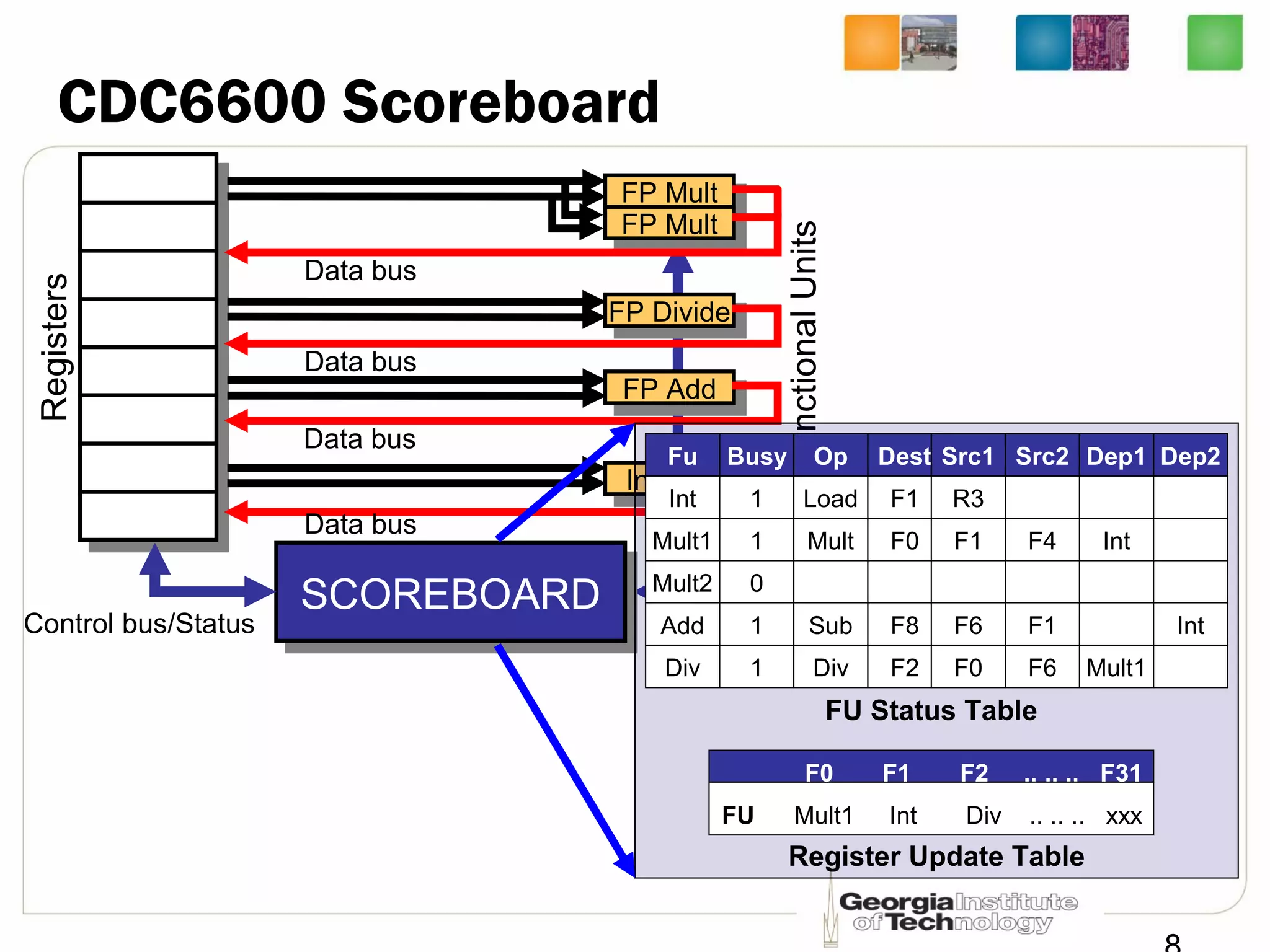





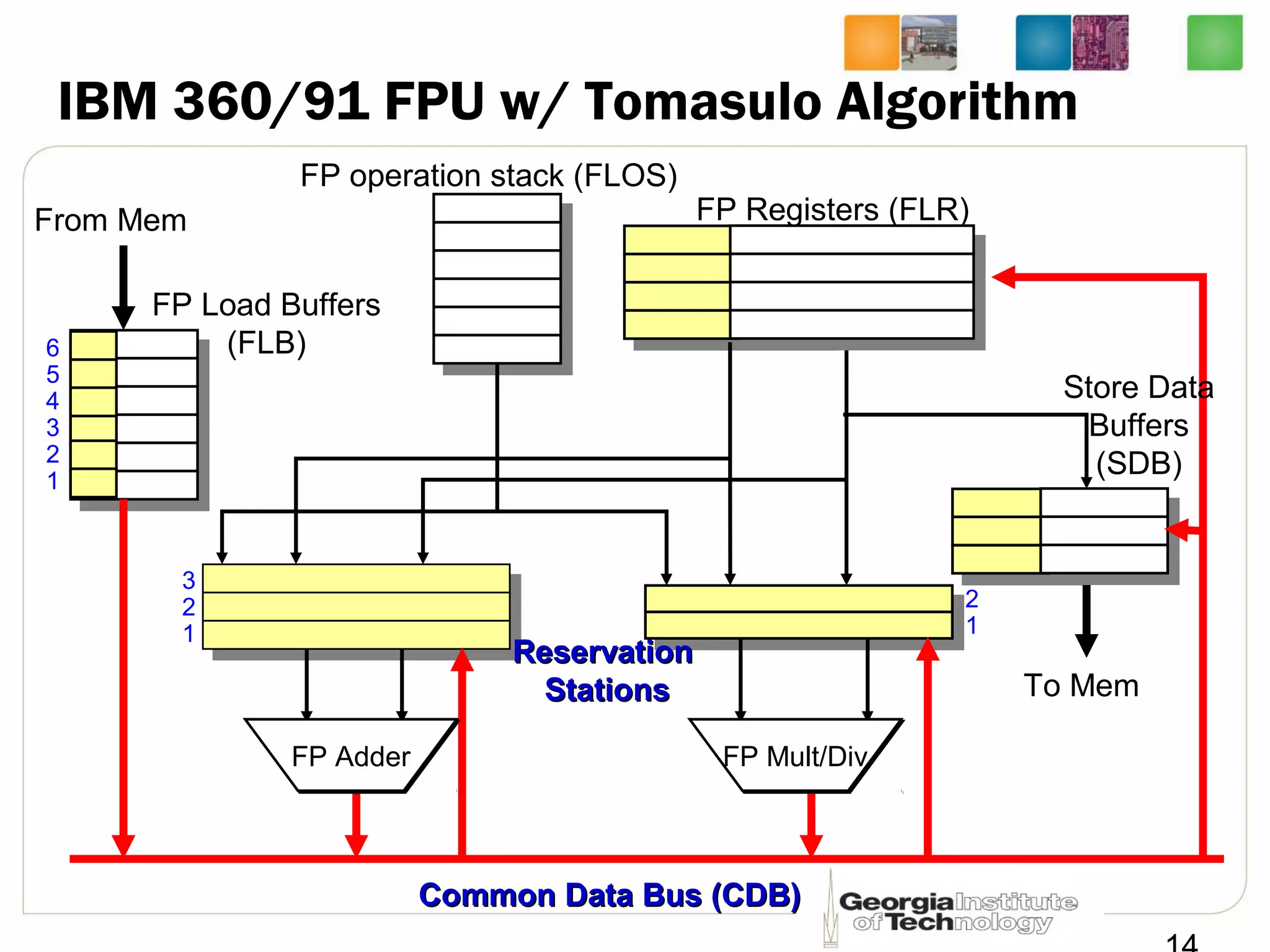
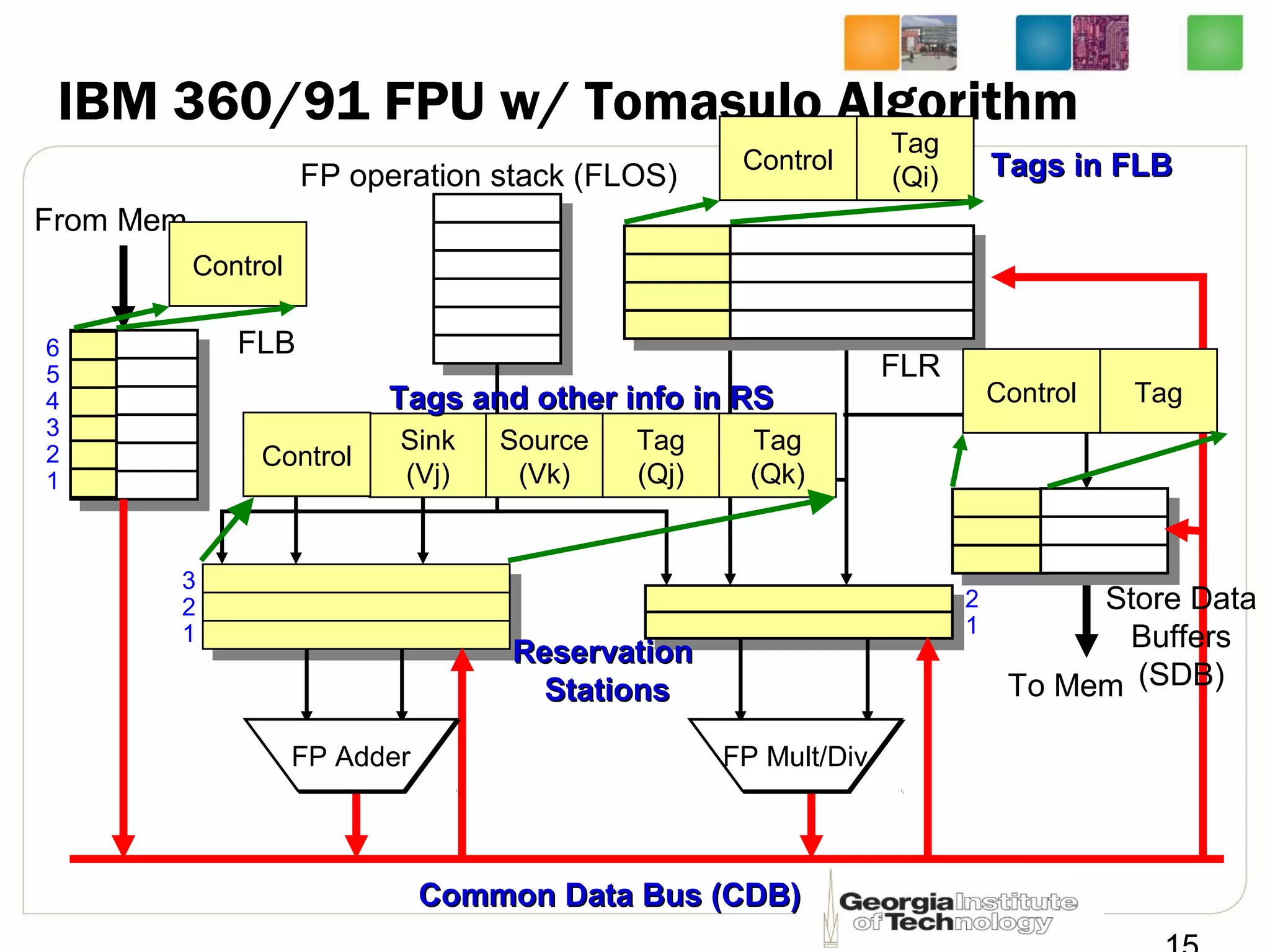


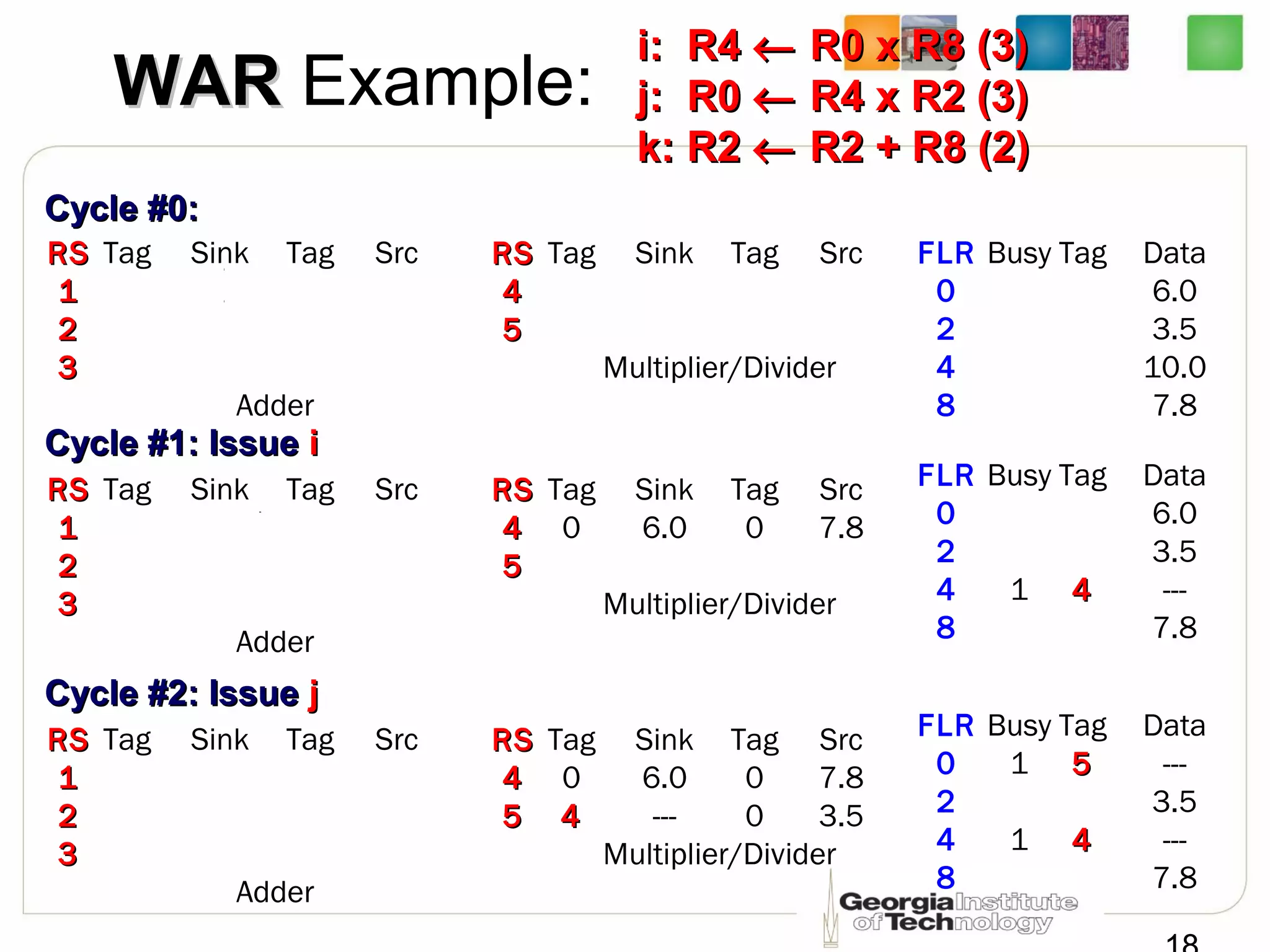


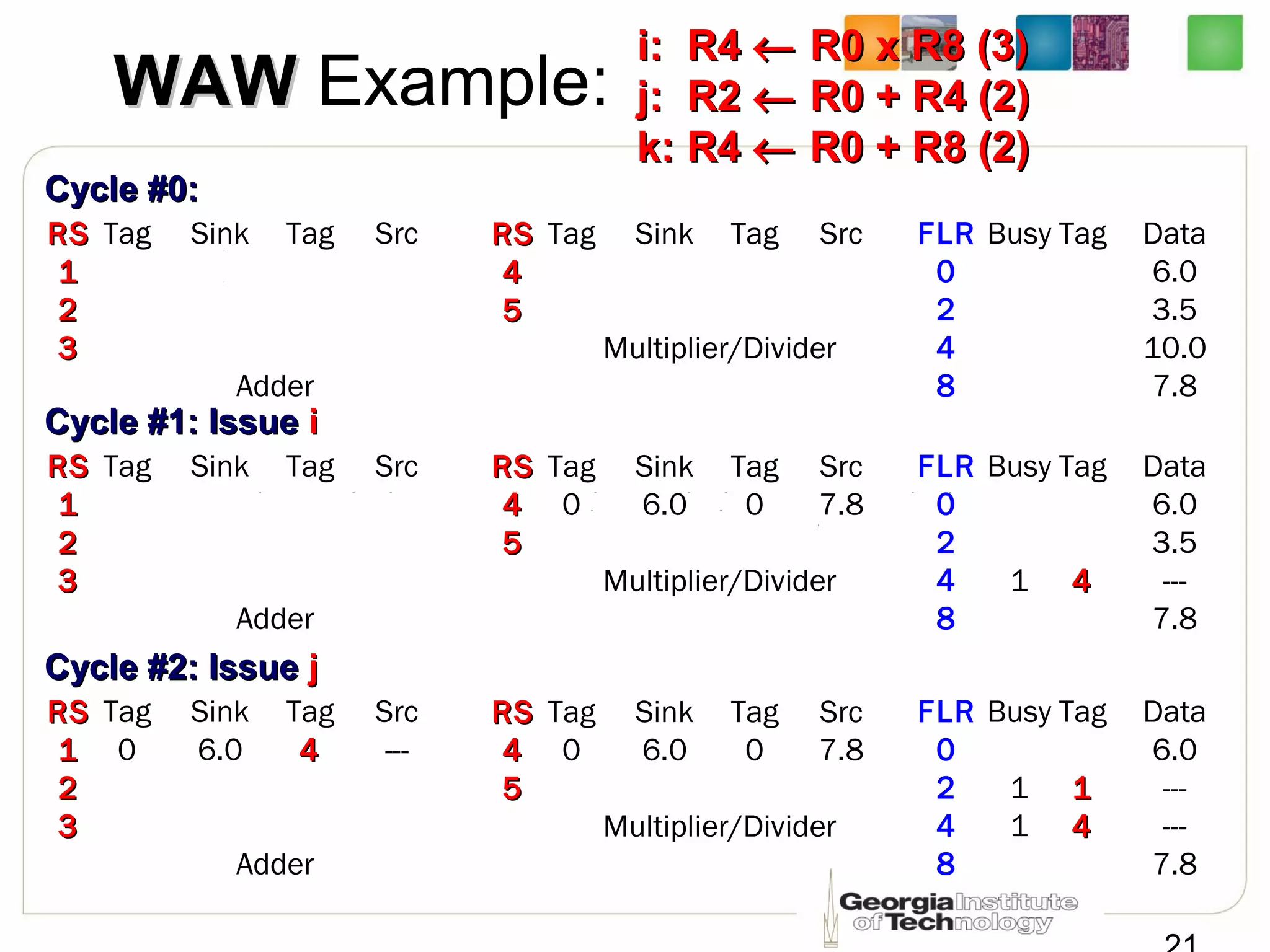





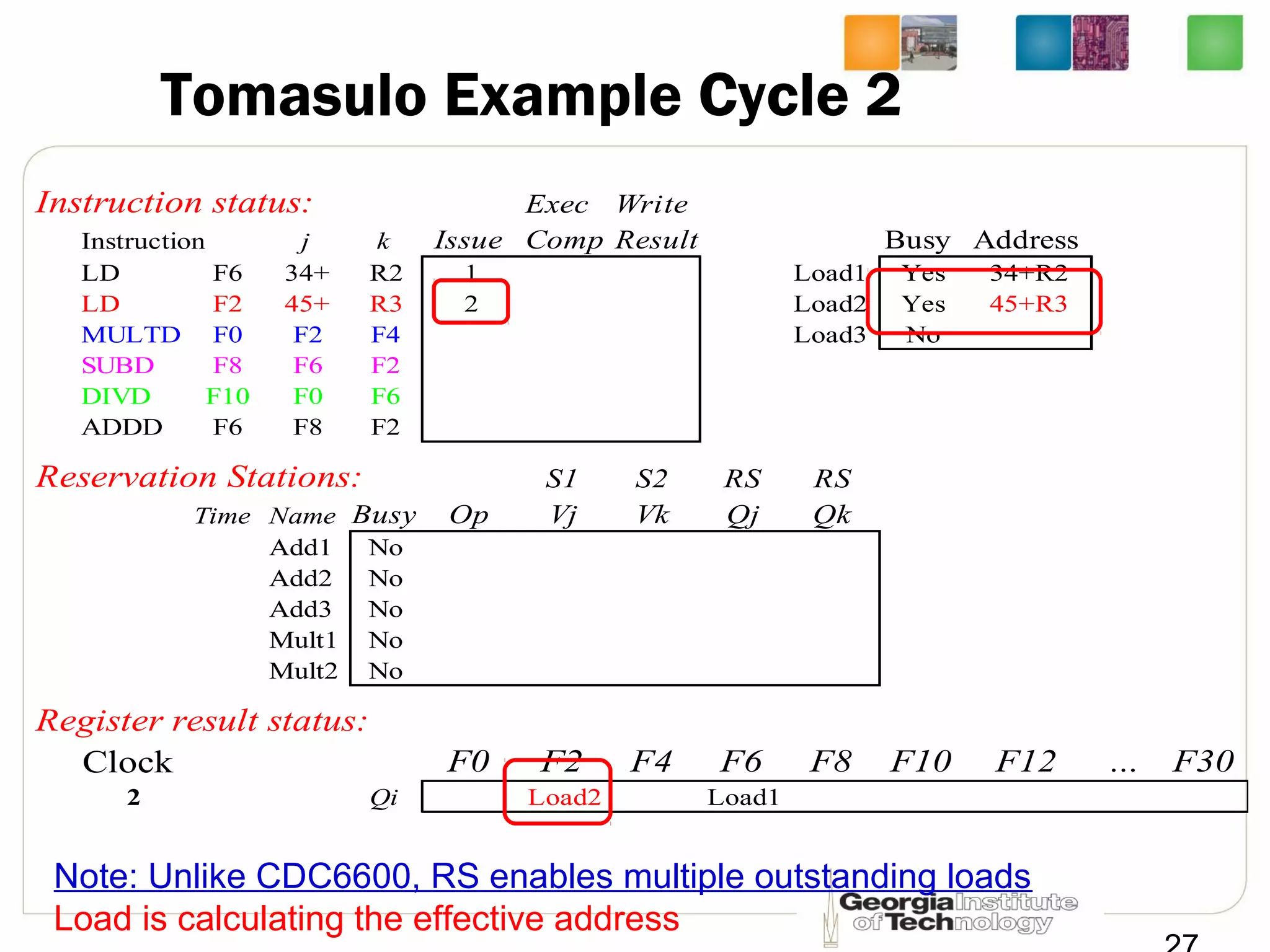

















This document summarizes a lecture on dynamic scheduling and the Tomasulo algorithm. It begins with an overview of dynamic scheduling and out-of-order execution. It then describes the Tomasulo algorithm used in IBM's 360/91 floating point unit, which introduced reservation stations, register renaming, and a common data bus to enable out-of-order execution while maintaining in-order retirement. Examples are provided to illustrate how the algorithm handles register dependencies like RAW, WAR, and WAW.











































































