This document summarizes a research paper on learning convolutional neural networks for graphs. It proposes a framework called PATCHY-SAN that applies CNNs to graphs by (1) selecting a node sequence and (2) generating normalized neighborhood representations for each node. Experimental results show PATCHY-SAN achieves accuracy competitive with graph kernels while being 2-8 times more efficient on benchmark graph classification tasks. The document concludes CNNs may be especially beneficial for learning graph representations when used with this proposed framework.











![Outline Absract Introduction Learning Procedure Experiments Conclusion and Future Work
Graph Classification
Learning Convolutional Neural Networks for Graphs
Data set MUTAG PCT NCI1 PROTEIN D & D
Max 28 109 111 620 5748
Avg 17.93 25.56 29.87 39.06 284.32
Graphs 188 344 4110 1113 1178
SP [7] 85.79 ± 2.51 58.53 ± 2.55 73.00 ± 0.51 75.07 ± 0.54 > 3 days
RW [17] 83.68 ± 1.66 57.26 ± 1.30 > 3 days 74.22 ± 0.42 > 3 days
GK [38] 81.58 ± 2.11 57.32 ± 1.13 62.28 ± 0.29 71.67 ± 0.55 78.45 ± 0.26
WL [39] 80.72 ± 3.00 (5s) 56.97 ± 2.01 (30s) 80.22 ± 0.51 (375s) 72.92 ± 0.56 (143s) 77.95 ± 0.70 (609s)
PSCN k=5 91.58 ± 5.86 (2s) 59.43 ± 3.14 (4s) 72.80 ± 2.06 (59s) 74.10 ± 1.72 (22s) 74.58 ± 2.85 (121s)
PSCN k=10 88.95 ± 4.37 (3s) 62.29 ± 5.68 (6s) 76.34 ± 1.68 (76s) 75.00 ± 2.51 (30s) 76.27 ± 2.64 (154s)
PSCN k=10E
92.63 ± 4.21 (3s) 60.00 ± 4.82 (6s) 78.59 ± 1.89 (76s) 75.89 ± 2.76 (30s) 77.12 ± 2.41 (154s)
PSLR k=10 87.37 ± 7.88 58.57 ± 5.46 70.00 ± 1.98 71.79 ± 3.71 68.39 ± 5.56
Table 1. Properties of the data sets and accuracy and timing results (in seconds) for PATCHY-SAN and 4 state of the art graph kernels.
Data set GK [38] DGK [45] PSCN k=10
COLLAB 72.84 ± 0.28 73.09 ± 0.25 72.60 ± 2.15
IMDB-B 65.87 ± 0.98 66.96 ± 0.56 71.00 ± 2.29
IMDB-M 43.89 ± 0.38 44.55 ± 0.52 45.23 ± 2.84
RE-B 77.34 ± 0.18 78.04 ± 0.39 86.30 ± 1.58
RE-M5k 41.01 ± 0.17 41.27 ± 0.18 49.10 ± 0.70
RE-M10k 31.82 ± 0.08 32.22 ± 0.10 41.32 ± 0.42
Table 2. Comparison of accuracy results on social graphs [45].
parison, we used a single network architecture with two
kernels. In most cases, a receptive field size of 10 results
in the best classification accuracy. The relatively high vari-
ance can be explained with the small size of the bench-
mark data sets and the fact that the CNNs hyperparame-
ters (with the exception of epochs and batch size) were not
tuned to individual data sets. Similar to the experience on
image and text data, we expect PATCHY-SAN to perform
even better for large data sets. Moreover, PATCHY-SAN is
between 2 and 8 times more efficient than the most effi-
cient graph kernel (WL). We expect the performance ad-
vantage to be much more pronounced for data sets with a
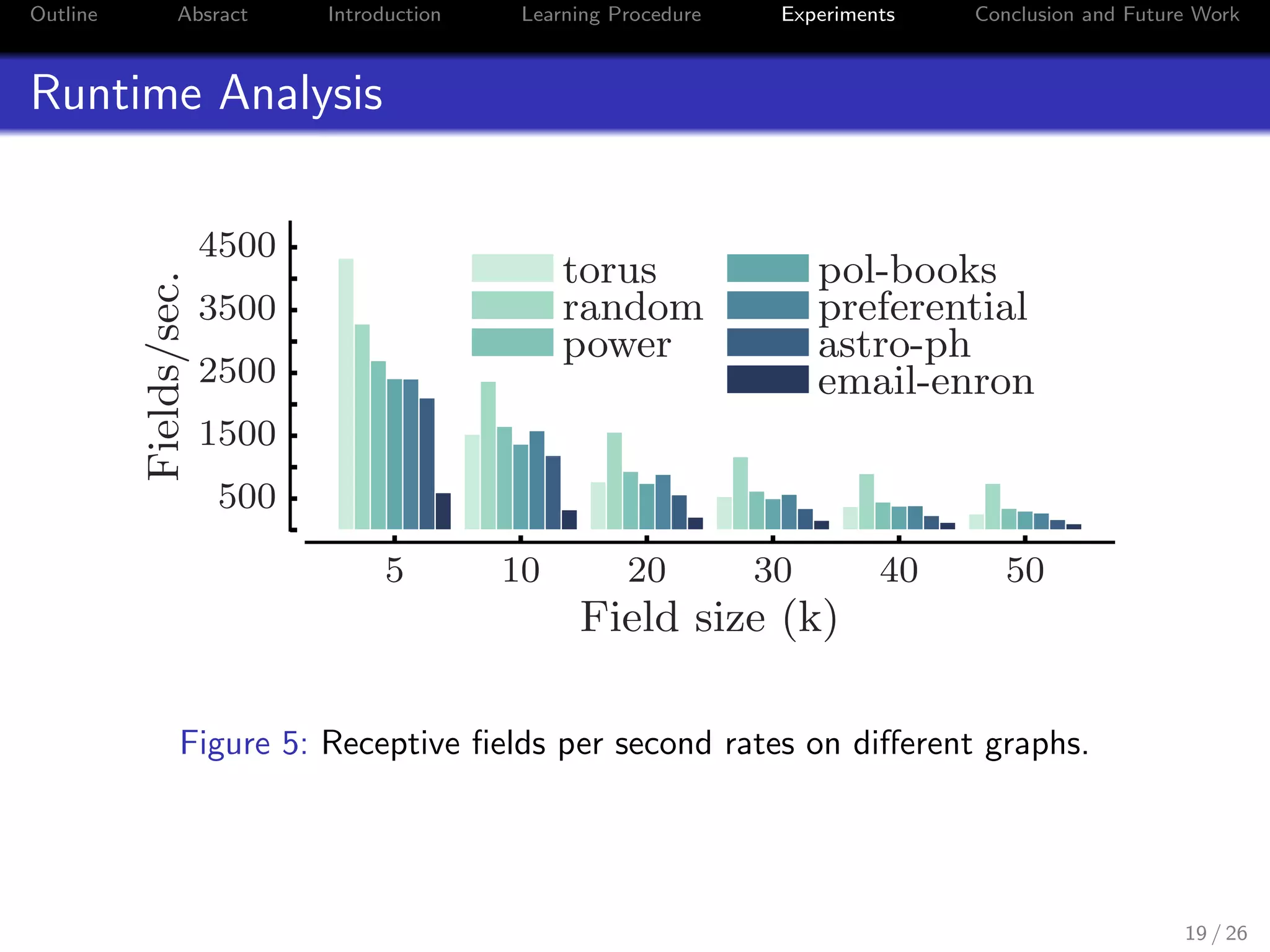
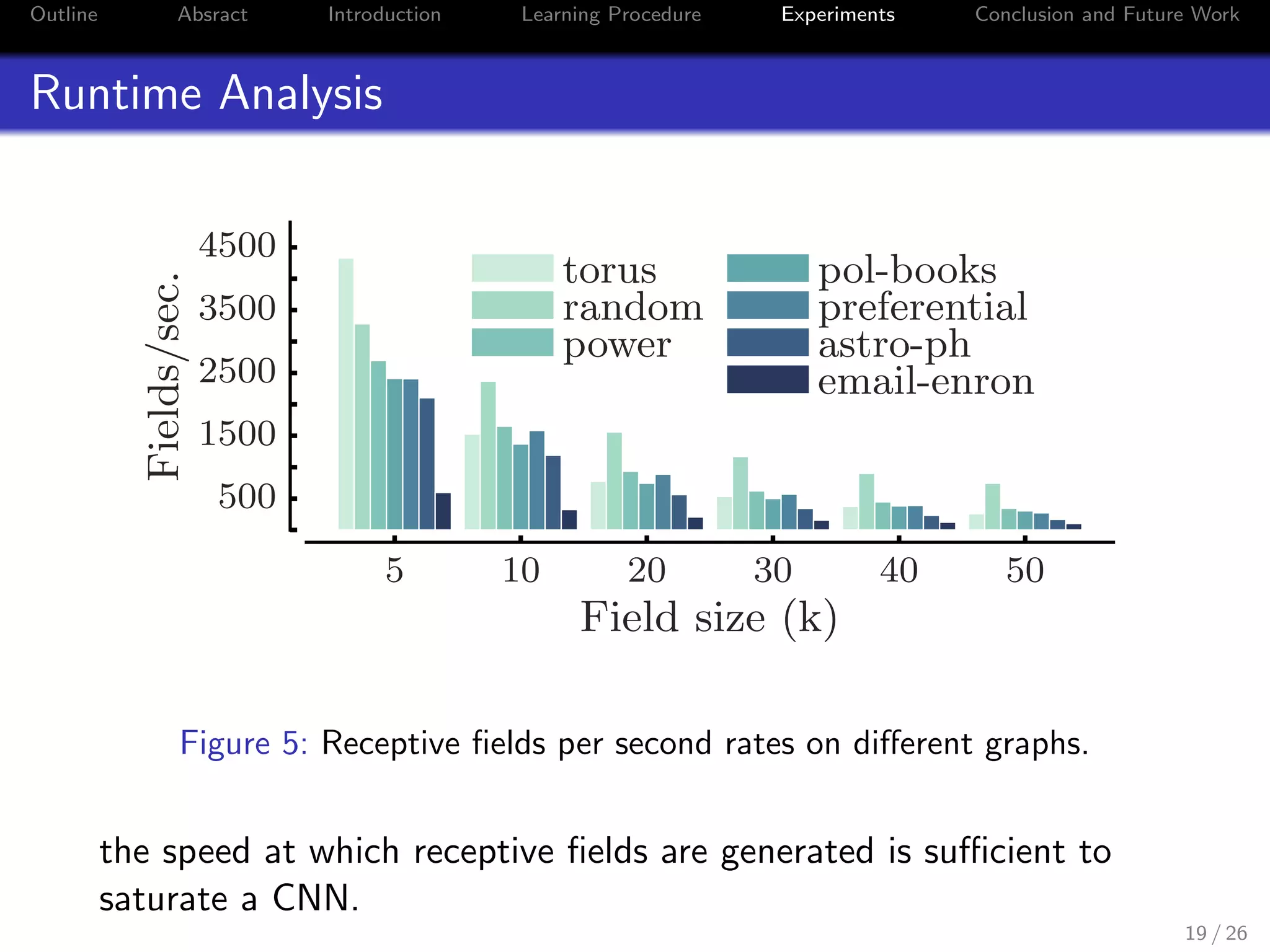
Figure 6: Properties of the data sets and accuracy and timing results (in
seconds) where k is the size of the field.
22 / 26](https://image.slidesharecdn.com/icml2016-v48-niepert16-180329105503/75/Learning-Convolutional-Neural-Networks-for-Graphs-24-2048.jpg)











































![[NS][Lab_Seminar_240617]A Survey on Graph Neural Networks and Graph Transform...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240617asurvey-240624082546-9e44d3fd-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NS][Lab_Seminar_241111]Patch-Wise Graph Contrastive Learning for Image Trans...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241111patch-wisegraphcontrastivelearningforimagetranslation-241118111607-5d2d1621-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_240610]Graph Representation Learning Meets Computer Vision: ...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240610asurvey-240624082635-332965ce-thumbnail.jpg?width=640&height=640&fit=bounds)





















