Download as PDF, PPTX


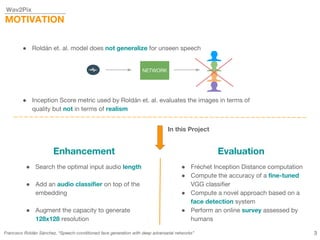

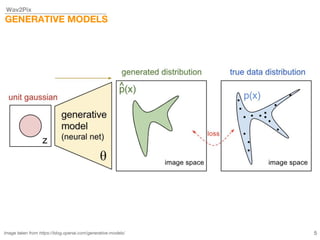
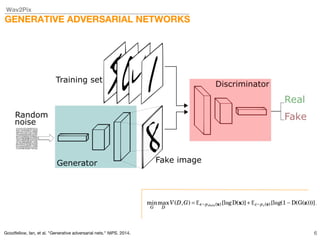



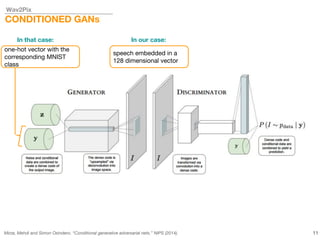
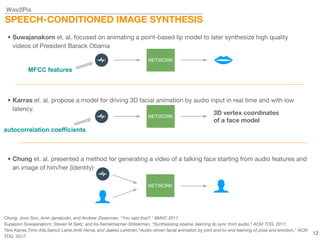

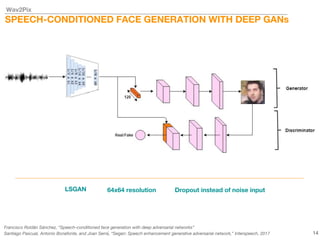



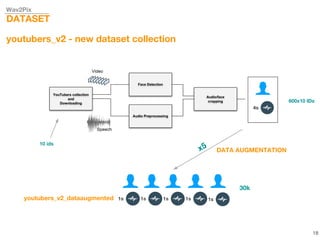
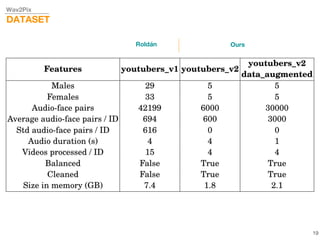

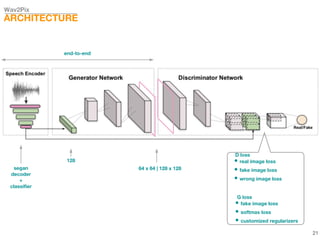
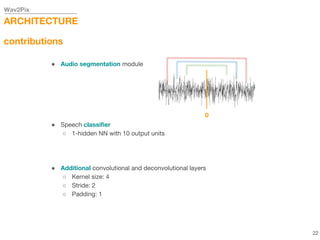

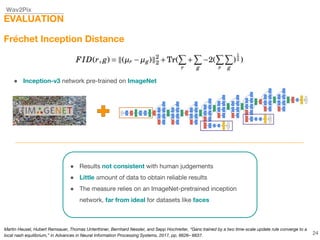
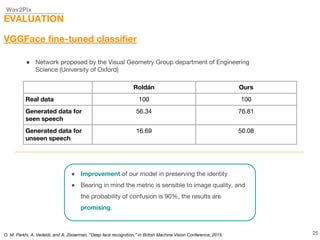
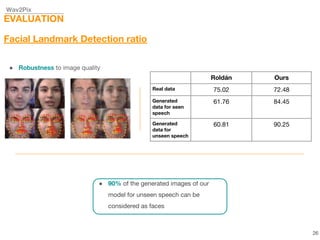
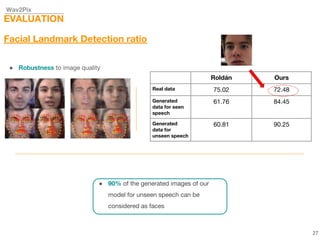




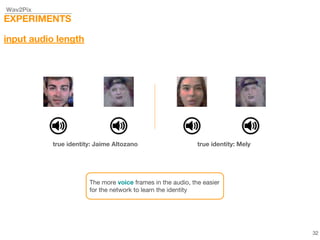
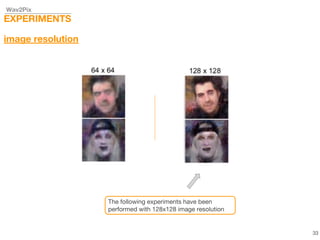
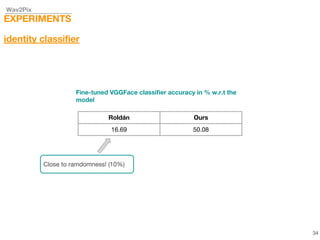
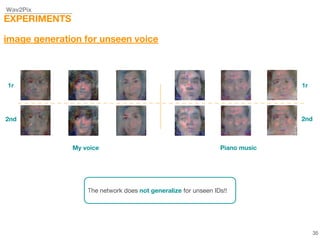
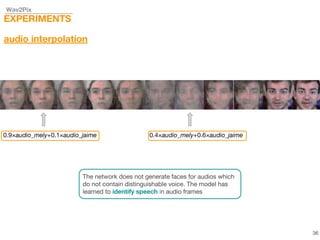




This document describes a study on speech-conditioned face generation using generative adversarial networks. The study aimed to enhance an existing model by adding an audio classifier, increasing the image resolution to 128x128, and using additional evaluation metrics. The results showed that the enhanced model generated higher quality images that better preserved identity for unseen speech compared to the existing model, but it did not generalize to generating faces for unseen identities.





























![SSII2021 [SS2] Deepfake Generation and Detection – An Overview (ディープフェイクの生成と検出)](https://cdn.slidesharecdn.com/ss_thumbnails/ss2-01-210607043612-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Paper Review] Audio adversarial examples](https://cdn.slidesharecdn.com/ss_thumbnails/labmeeting20180114audioadversarialexamples-180126121342-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)


