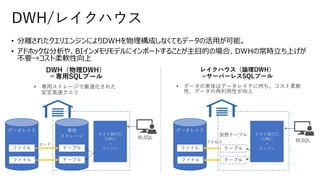
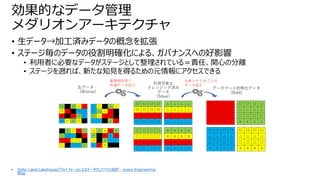
• ニーズ:サイロ化した業務システムの分析のためにデータを統合・集約した DWHが必要と
なった
• 問題:高コスト、スキーマオンライト(後述)、ML対応が困難
従来のDWH型情報基盤
• What is a Data Lakehouse? – Databricks
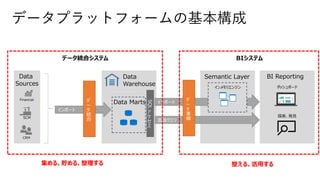
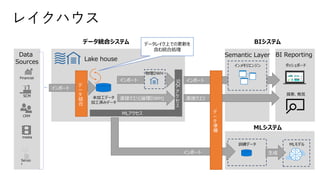
データソース:サイロ化した業務システム
統合:様々なデータを抽出、変換、ロード(ETL)
DWH:データマートの集合体としてRDBMSに保管
BI、可視化:ユーザライクなツールによるデータの分析
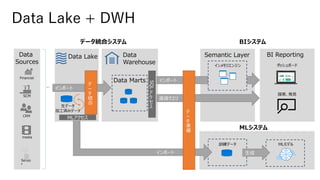
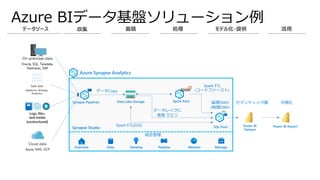
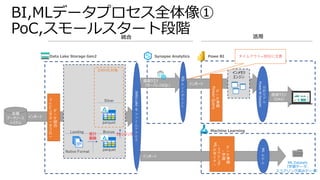
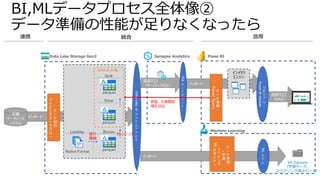
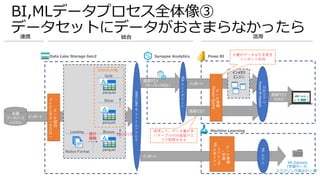
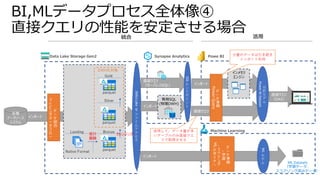
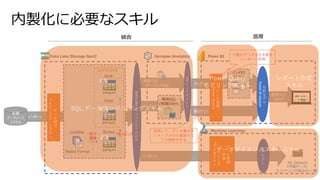
Azure BIデータ基盤ソリューション例
Azure SynapseAnalytics
Synapse Pipelines
SQL Pool
Spark Pool
Data Lake Storage
Spark ETL(GUI)
データレイクに
直接 クエリ
Spark ETL
(コードファースト)
Overview Data Develop Monitor
Pipeline Manage
Synapse Studio
統合管理
データCopy
Power BI Report
Power BI
Dataset
セマンティック層
論理DWH
/物理DWH
可視化



![スキーマオンライトとスキーマオンリード
DWH中心← → データレイク中心
• ユーザによる活用 (分析)
シナリオを想定し、
そこからデータ蓄積先の
スキーマを設計
• 業務システムからは、
そのシナリオ実現のため
にETLで「データ」抽出
• 想定に含まれなかった
「データ」の周辺データは
埋没
Schema-on-Write
• 将来のあらゆる分析
要件に対応するために、
すべてのデータを、
可能な限りネイティブ
フォーマットのまま蓄積
• 利用時にはじめて
スキーマ・データ構造を
定義し、Read を実施
Schema-on-Read
abe, 95, 46, 85, 85
itoh, 89, 72, 46, 76,
34
ueda, 95, 13, 57, 63,
87
emoto, 50, 68, 38,
85, 98
otsuka, 13, 16, 67,
100, 7
katase, 42, 61, 90,
11, 33
{"name" : "cat",
"count" : 105}
{"name" : "dog",
"count" : 81}
{"name" : "rabbit",
"count" : 2030}
{"name" : "turtle",
"count" : 1550}
{"name" : "tiger",
"count" : 300}
{"name" : "lion",
"count" : 533}
{"name" : "whale",
"count" : 2934}
xxx.xxx.xxx.xxx - -
[27/Jan/2018:14:20:17
+0000] "GET
/item/giftcards/3720
HTTP/1.1" 200 70 "-"
"Mozilla/5.0
(Windows NT 6.1;
WOW64; rv:10.0.1)
Gecko/20100101
Firefox/10.0.1"
ネイティブフォーマットを、そのまま蓄積
SELECT ~~~ FROM ~~~
WHERE ~~~ ORDER BY ~~~;
利用時にデータ構造を定義
4
ストレージ総保有コスト
の低下](https://image.slidesharecdn.com/dataplatformsynapsedelta-210902105921/85/Synapse-Analytics-4-320.jpg)








![[DI12] あらゆるデータをビジネスに活用! Azure Data Lake を中心としたビックデータ処理基盤のアーキテクチャと実装](https://cdn.slidesharecdn.com/ss_thumbnails/di12-170616053736-thumbnail.jpg?width=640&height=640&fit=bounds)










![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=640&height=640&fit=bounds)













![[db tech showcase Tokyo 2017] E35: 12台でやってみた!DWHソフトウェアアプライアンス Db2 Warehouse ~...](https://cdn.slidesharecdn.com/ss_thumbnails/e35-2-170913082538-thumbnail.jpg?width=640&height=640&fit=bounds)




![[de:code 2019 振り返り Night!] Data Platform](https://cdn.slidesharecdn.com/ss_thumbnails/20190610decode2019dataplatformrecap-190610113039-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2018] #dbts2018 #E28 『Hadoop DataLakeにリアルタイムでデータをレプリケ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018e28hadoopdatalake-181004235141-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...](https://cdn.slidesharecdn.com/ss_thumbnails/ist18a-2-180822044642-thumbnail.jpg?width=640&height=640&fit=bounds)

![[C23] 「今」を分析するストリームデータ処理技術とその可能性 by Takahiro Yokoyama](https://cdn.slidesharecdn.com/ss_thumbnails/c23hitachiyokoyama-131215225816-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








