Recommended
PDF
データウェアハウス入門 (マーケティングデータ分析基盤技術勉強会)
PDF
[Azure Deep Dive] Spark と Azure HDInsight によるビッグ データ分析入門 (2017/03/27)
PDF
BigData-JAWS#16 Lake House Architecture
PDF
データ分析基盤、どう作る?システム設計のポイント、教えます - Developers.IO 2019 (20191101)
PDF
PPTX
AWS朝会2022/1 セッション① 数年間、レイクハウスを設計運用してみた
PPTX
Hadoop / Elastic MapReduceつまみ食い
PDF
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
PDF
[db tech showcase Tokyo 2018] #dbts2018 #E28 『Hadoop DataLakeにリアルタイムでデータをレプリケ...
PDF
PPTX
大規模分散システムの現在 -- GFS, MapReduce, BigTableはどう変化したか?
PPTX
リクルートライフスタイルの考える�ストリームデータの活かし方(Hadoop Spark Conference2016)
PDF
データ活用をもっともっと円滑に!�~データ処理・分析基盤編を少しだけ~
PPTX
データサイエンティストが力を発揮できるアジャイルデータ活用基盤
PDF
[db tech showcase Tokyo 2018] #dbts2018 #D1L 『"何が必要?どう実現?"~異種DB間データリアルタイム連携』
PDF
[db tech showcase Tokyo 2018] #dbts2018 #D24 『異種データベース間データ連携ウラ話 ~ 新しいデータベースを試...
PPTX
PDF
Database as code in Devops - DBを10分間で1000個構築するDB仮想化テクノロジーとは?(Ishikawa)
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
PDF
PPTX
PDF
Hadoop Summit 2016 San Jose レポート
PDF
PDF
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
PDF
ビッグデータ革命 クラウドがコモデティ化する「奇跡」
PPTX
PDF
PDF
PDF
PPTX
More Related Content
PDF
データウェアハウス入門 (マーケティングデータ分析基盤技術勉強会)
PDF
[Azure Deep Dive] Spark と Azure HDInsight によるビッグ データ分析入門 (2017/03/27)
PDF
BigData-JAWS#16 Lake House Architecture
PDF
データ分析基盤、どう作る?システム設計のポイント、教えます - Developers.IO 2019 (20191101)
PDF
PPTX
AWS朝会2022/1 セッション① 数年間、レイクハウスを設計運用してみた
PPTX
Hadoop / Elastic MapReduceつまみ食い
PDF
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
What's hot
PDF
[db tech showcase Tokyo 2018] #dbts2018 #E28 『Hadoop DataLakeにリアルタイムでデータをレプリケ...
PDF
PPTX
大規模分散システムの現在 -- GFS, MapReduce, BigTableはどう変化したか?
PPTX
リクルートライフスタイルの考える�ストリームデータの活かし方(Hadoop Spark Conference2016)
PDF
データ活用をもっともっと円滑に!�~データ処理・分析基盤編を少しだけ~
PPTX
データサイエンティストが力を発揮できるアジャイルデータ活用基盤
PDF
[db tech showcase Tokyo 2018] #dbts2018 #D1L 『"何が必要?どう実現?"~異種DB間データリアルタイム連携』
PDF
[db tech showcase Tokyo 2018] #dbts2018 #D24 『異種データベース間データ連携ウラ話 ~ 新しいデータベースを試...
PPTX
PDF
Database as code in Devops - DBを10分間で1000個構築するDB仮想化テクノロジーとは?(Ishikawa)
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
PDF
PPTX
PDF
Hadoop Summit 2016 San Jose レポート
PDF
PDF
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
PDF
ビッグデータ革命 クラウドがコモデティ化する「奇跡」
PPTX
PDF
PDF
Similar to [INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop
PDF
PPTX
PPTX
PDF
Cassandraとh baseの比較して入門するno sql
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
PPTX
Cloud impact on IT industry (in Japanese)
PDF
ITpro EXPO版「データセンター視点で比較したクラウドの内側」
PDF
20120409 aws meister-reloaded-dynamo-db
PDF
PPTX
PPT
PDF
Hadoop Conference Japan 2009 - NTT Data
PPTX
PDF
OSSとクラウドによるコンピューティングモデルの変化
PDF
ビッグデータはバズワードか? (Cloudian Summit 2012)
PDF
PDF
オブジェクトストレージの適用領域とCloudianの位置づけ (Cloudian Summit 2012)
PPTX
PDF
PPT
Devsumi2013【15-e-5】NoSQLの野心的な使い方 ~Apache Cassandra編~
More from Insight Technology, Inc.
PDF
PDF
Docker and the Oracle Database
PDF
Great performance at scale~次期PostgreSQL12のパーティショニング性能の実力に迫る~
PDF
PDF
仮想通貨ウォレットアプリで理解するデータストアとしてのブロックチェーン
PDF
PDF
PDF
PDF
SQL Server エンジニアのためのコンテナ入門
PDF
Lunch & Learn, AWS NoSQL Services
PDF
db tech showcase2019オープニングセッション @ 森田 俊哉
PDF
db tech showcase2019 オープニングセッション @ 石川 雅也
PDF
db tech showcase2019 オープニングセッション @ マイナー・アレン・パーカー
PPTX
難しいアプリケーション移行、手軽に試してみませんか?
PPTX
Attunityのソリューションと異種データベース・クラウド移行事例のご紹介
PPTX
PPTX
コモディティサーバー3台で作る高速処理 “ハイパー・コンバージド・データベース・インフラストラクチャー(HCDI)” システム『Insight Qube』...
PDF
複数DBのバックアップ・切り戻し運用手順が異なって大変?!運用性の大幅改善、その先に。。
PPTX
Attunity社のソリューションの日本国内外適用事例及びロードマップ紹介[ATTUNITY & インサイトテクノロジー IoT / Big Data フ...
PPTX
レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]
[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop 1. 2. 1. Insight Qubeなる新プロダクト開発中
2. おら オラ Oracle どっぷり検証生活
2. Oracle ACE
3. @kouji_s_0808
4. JPOUG(Japan Oracle User Group)
本日はOracle以外の話です。
本資料に使用されている社名、ロゴ、製品、サービス名およびブランドは、該当する各社の登
録商標または商標です。本資料の一部あるいは全体について、許可なく複製および転載するこ
とを禁じます。
2
3. • 企業は今後10年で50倍のデータ量 • ビッグデータの95%は非構造化データ
• 一方、IT部門は1.5倍増にとどまる が含まれる。
http://enterprisezine.jp/article/detail/3394
• 2011年には1.8ゼタバイトのデータが作成、
複製されると予想
World's Data More Than Doubling Every Two Years—Driving Big Data Opportunity, New IT Roles • Googleは94テラバイト/月のデータ処
理(2010/6時点)
ACM Symposium on Cloud Computing (SOCC) 2010
大量データ 高効率 多種類 高速
3
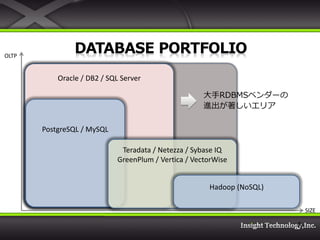
4. OLTP
Oracle / DB2 / SQL Server
大手RDBMSベンダーの
進出が著しいエリア
PostgreSQL / MySQL
Teradata / Netezza / Sybase IQ
GreenPlum / Vertica / VectorWise
Hadoop (NoSQL)
SIZE
4
5. 複数のディストリビューション
本家(http://hadoop.apache.org/)
Cloudera社(http://www.cloudera.com/)
Yahoo!社
(http://developer.yahoo.com/hadoop/)
5
6. 7. • ビッグデータと呼ばれるデータの質を正確に認識する必要がある
• 構造化 / 非構造化
• 利用シーン
• ビッグデータへのアプローチは様々ある中で、最適なものを選択
していく必要がある
• RDBMS / New RDBMS / NoSQL (Hadoop)
• 新しい領域と新しい技術を組み合わせる場合、その技術を活用す
るための情報量が少ない
• 実際にビッグデータに対するプロジェクトの担当者に話を聞くの
が最も効果的
7
8.










![[Azure Deep Dive] Spark と Azure HDInsight によるビッグ データ分析入門 (2017/03/27)](https://cdn.slidesharecdn.com/ss_thumbnails/20170327azuredeepdivehdinsightspark-170327093409-thumbnail.jpg?width=640&height=640&fit=bounds)






![[db tech showcase Tokyo 2018] #dbts2018 #E28 『Hadoop DataLakeにリアルタイムでデータをレプリケ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018e28hadoopdatalake-181004235141-thumbnail.jpg?width=640&height=640&fit=bounds)





![[db tech showcase Tokyo 2018] #dbts2018 #D1L 『"何が必要?どう実現?"~異種DB間データリアルタイム連携』](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018d1ldbattunity-181004234713-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2018] #dbts2018 #D24 『異種データベース間データ連携ウラ話 ~ 新しいデータベースを試...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018d24dbattunity-181004234957-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)