【中級者向け】
データ基盤の機能の考え方
Principle of DataPlatform design
Microsoft MVP for Data Platform 2021
永田 亮磨
Twitter:@ryomaru0825
Linkedin:ryoma-nagata-0825
Qiita:qiita.com/ryoma-nagata
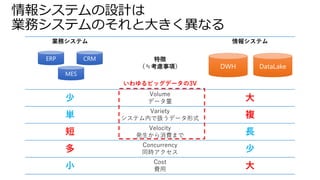
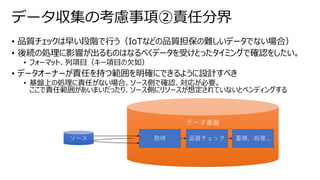
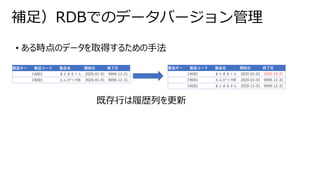
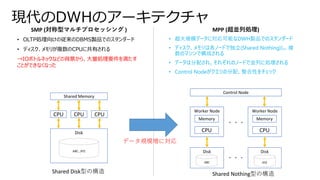
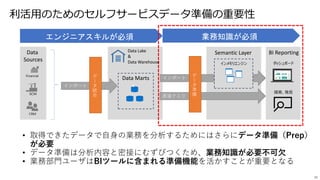
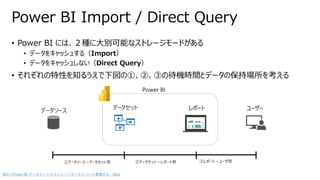
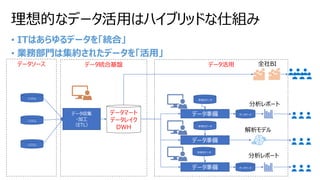
• Power BIには、2種に大別可能なストレージモードがある
• データをキャッシュする(Import)
• データをキャッシュしない(Direct Query)
• それぞれの特性を知るうえで下図の①、②、③の待機時間とデータの保持場所を考える
Power BI Import / Direct Query
データソース データセット レポート ユーザー
Power BI
①データソース~データセット間 ②データセット~レポート間 ③レポート~ユーザ間
改めてPower BI データセットのストレージモードについて整理する - Qiita
39.
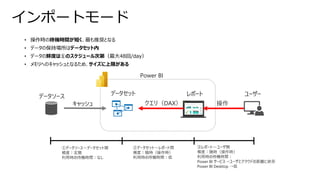
• 操作時の待機時間が短く、最も推奨となる
• データの保持場所はデータセット内
•データの鮮度は①のスケジュール次第(最大48回/day)
• メモリへのキャッシュとなるため、サイズに上限がある
インポートモード
データソース データセット レポート ユーザー
Power BI
キャッシュ
①データソース~データセット間
頻度:定期
利用時の待機時間:なし
操作
クエリ(DAX)
②データセット~レポート間
頻度:随時(操作時)
利用時の待機時間:低
③レポート~ユーザ間
頻度:随時(操作時)
利用時の待機時間:
Power BI サービス→ユーザとクラウドの距離に依存
Power BI Desktop →低
40.
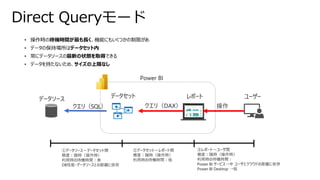
• 操作時の待機時間が最も長く、機能にもいくつかの制限があ
• データの保持場所はデータセット内
•常にデータソースの最新の状態を取得できる
• データを持たないため、サイズの上限なし
Direct Queryモード
データソース データセット レポート ユーザー
Power BI
クエリ(SQL)
①データソース~データセット間
頻度:随時(操作時)
利用時の待機時間:長
DB性能・データソースとの距離に依存
操作
クエリ(DAX)
②データセット~レポート間
頻度:随時(操作時)
利用時の待機時間:低
③レポート~ユーザ間
頻度:随時(操作時)
利用時の待機時間:
Power BI サービス→中 ユーザとクラウドの距離に依存
Power BI Desktop →低
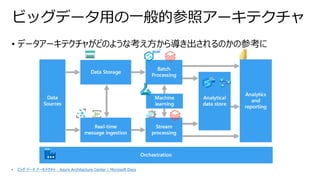
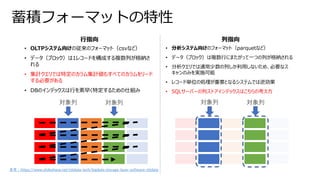
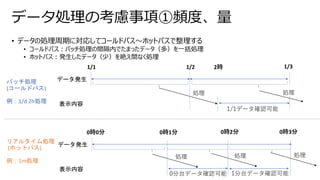
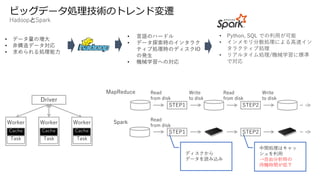
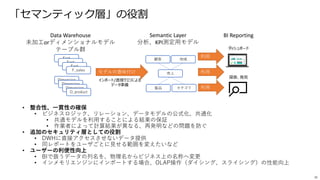
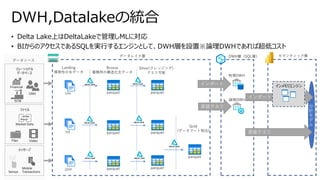
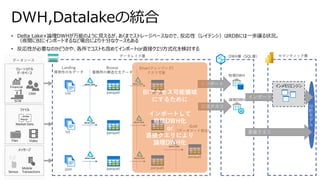
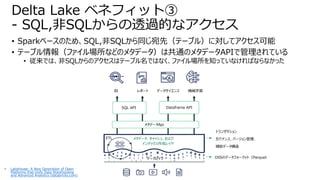
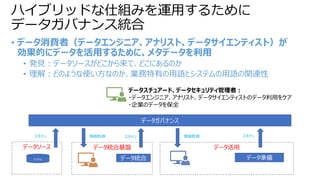
• Sparkベースのため、SQL,非SQLから同じ宛先(テーブル)に対してアクセス可能
• テーブル情報(ファイル場所などのメタデータ)は共通のメタデータAPIで管理されている
•従来では、非SQLからのアクセスはテーブル名ではなく、ファイル場所を知っていなければならなかった
Delta Lake ベネフィット③
- SQL,非SQLからの透過的なアクセス
• Lakehouse: A New Generation of Open
Platforms that Unify Data Warehousing
and Advanced Analytics (databricks.com)
データレイク
BI データサイエンス 機械学習
レポート
ETL メタデータ、キャッシュ、および
インデックス作成レイヤ
OSSのデータフォーマット(Parquet
トランザクション
ガバナンス、バージョン管理、
補助データ構造
メタデータApi
Dataframe API
SQL API







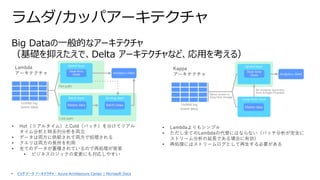
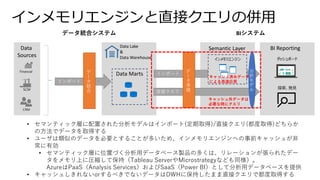
![スキーマオンライトとスキーマオンリード
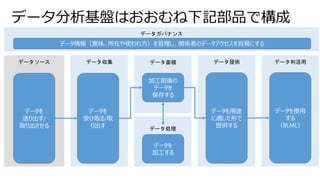
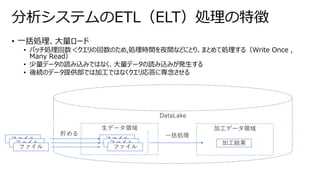
DWH時代← → データレイク以降
• ユーザによる活用 (分析)
シナリオを想定し、
そこからデータ蓄積先の
スキーマを設計
• 業務システムからは、
そのシナリオ実現のため
にETLで「データ」抽出
• 想定に含まれなかった
「データ」の周辺データは
埋没
Schema-on-Write
• 将来のあらゆる分析
要件に対応するために、
すべてのデータを、
可能な限りネイティブ
フォーマットのまま蓄積
• 利用時にはじめて
スキーマ・データ構造を
定義し、Read を実施
Schema-on-Read
abe, 95, 46, 85, 85
itoh, 89, 72, 46, 76,
34
ueda, 95, 13, 57, 63,
87
emoto, 50, 68, 38,
85, 98
otsuka, 13, 16, 67,
100, 7
katase, 42, 61, 90,
11, 33
{"name" : "cat",
"count" : 105}
{"name" : "dog",
"count" : 81}
{"name" : "rabbit",
"count" : 2030}
{"name" : "turtle",
"count" : 1550}
{"name" : "tiger",
"count" : 300}
{"name" : "lion",
"count" : 533}
{"name" : "whale",
"count" : 2934}
xxx.xxx.xxx.xxx - -
[27/Jan/2018:14:20:17
+0000] "GET
/item/giftcards/3720
HTTP/1.1" 200 70 "-"
"Mozilla/5.0
(Windows NT 6.1;
WOW64; rv:10.0.1)
Gecko/20100101
Firefox/10.0.1"
ネイティブフォーマットを、そのまま蓄積
SELECT ~~~ FROM ~~~
WHERE ~~~ ORDER BY ~~~;
利用時にデータ構造を定義
15
ストレージ総保有コスト
の低下](https://image.slidesharecdn.com/dataplatformdesign-210724044101/85/Data-platformdesign-15-320.jpg)




































![[de:code 2019 振り返り Night!] Data Platform](https://cdn.slidesharecdn.com/ss_thumbnails/20190610decode2019dataplatformrecap-190610113039-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29](https://cdn.slidesharecdn.com/ss_thumbnails/lanceriedelappserver-thehiveaug29-130920154018-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011b21part2nosqlhadoop-111114020909-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








![[db tech showcase Tokyo 2014] B33: 超高速データベースエンジンでのビッグデータ分析活用事例 by 株式会社日立製作所 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b33-141127184852-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
















