This document summarizes a training presentation on Azure Data Explorer (Kusto). The presentation covered:
1. An introduction to Kusto as a new way to analyze big data and logs that is fast, easy to use, and helps understand services quickly.
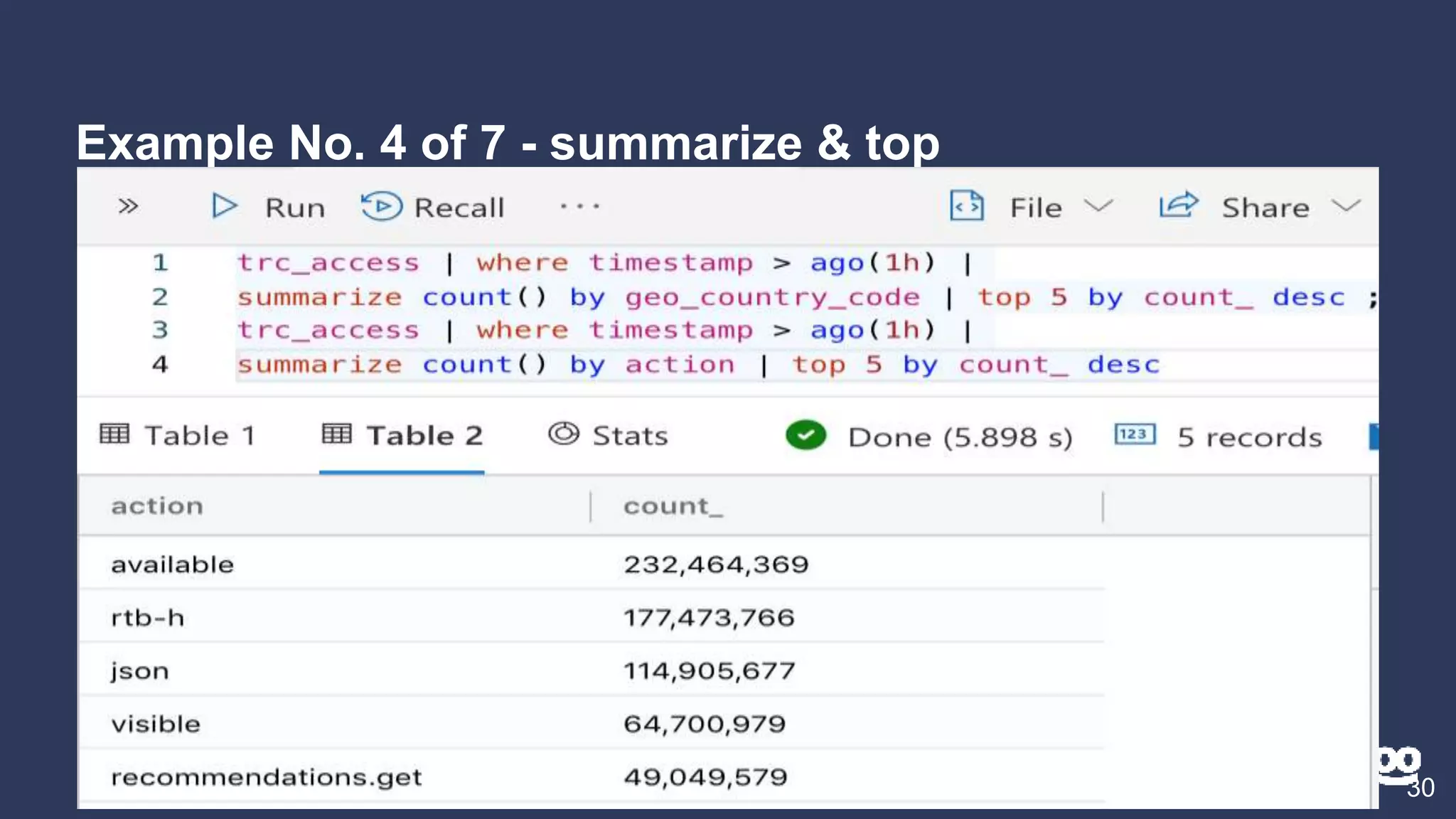
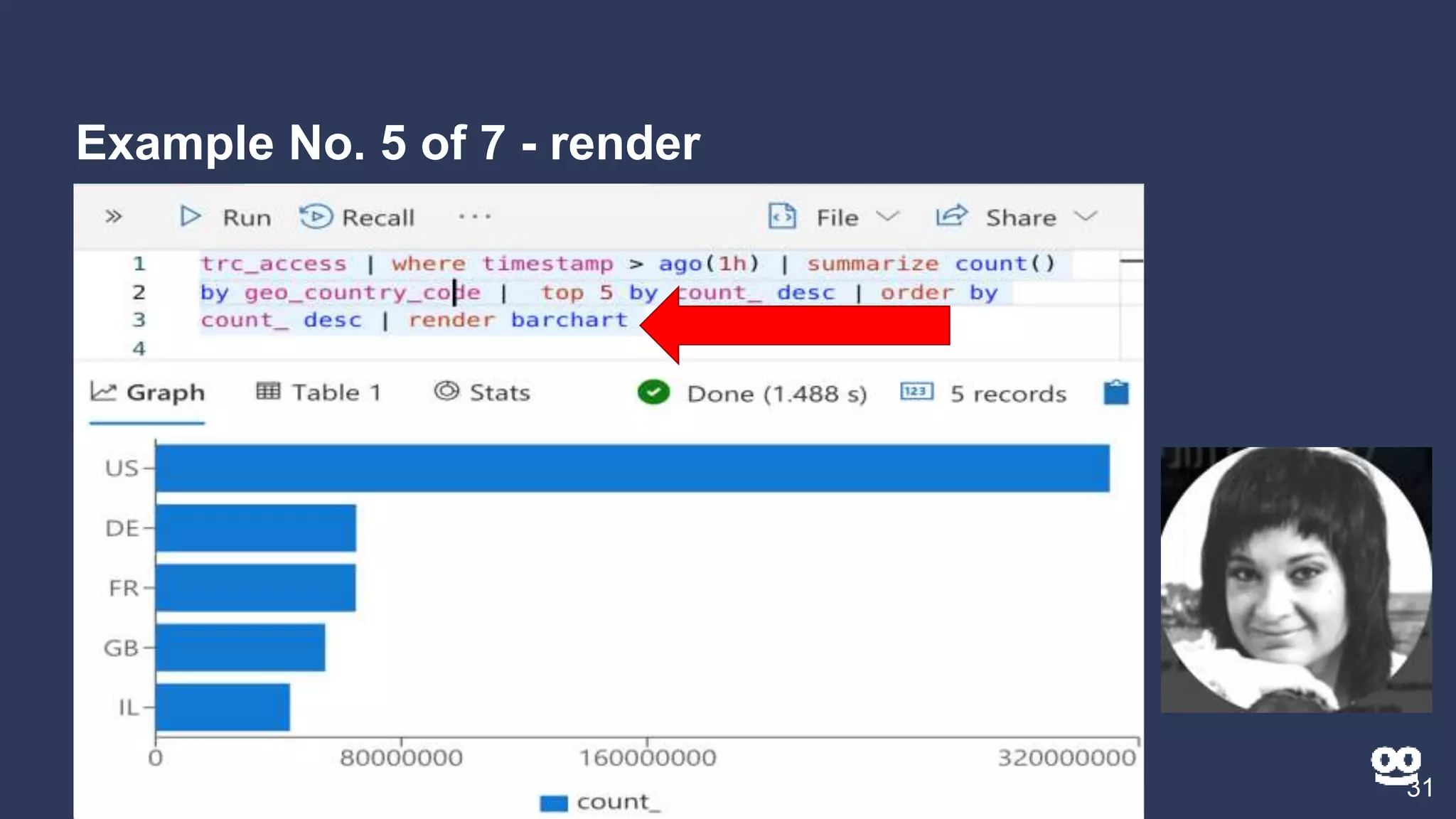
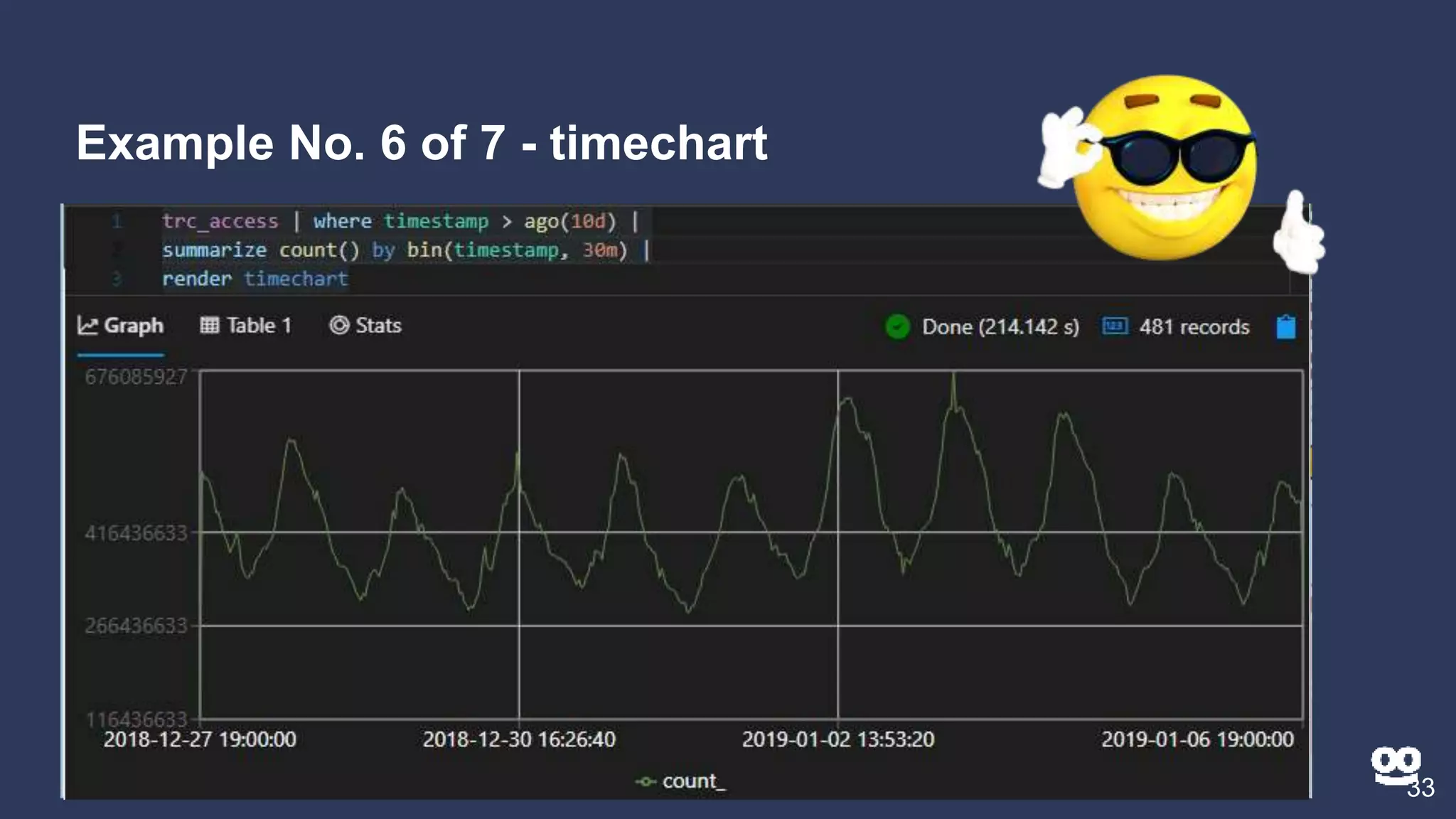
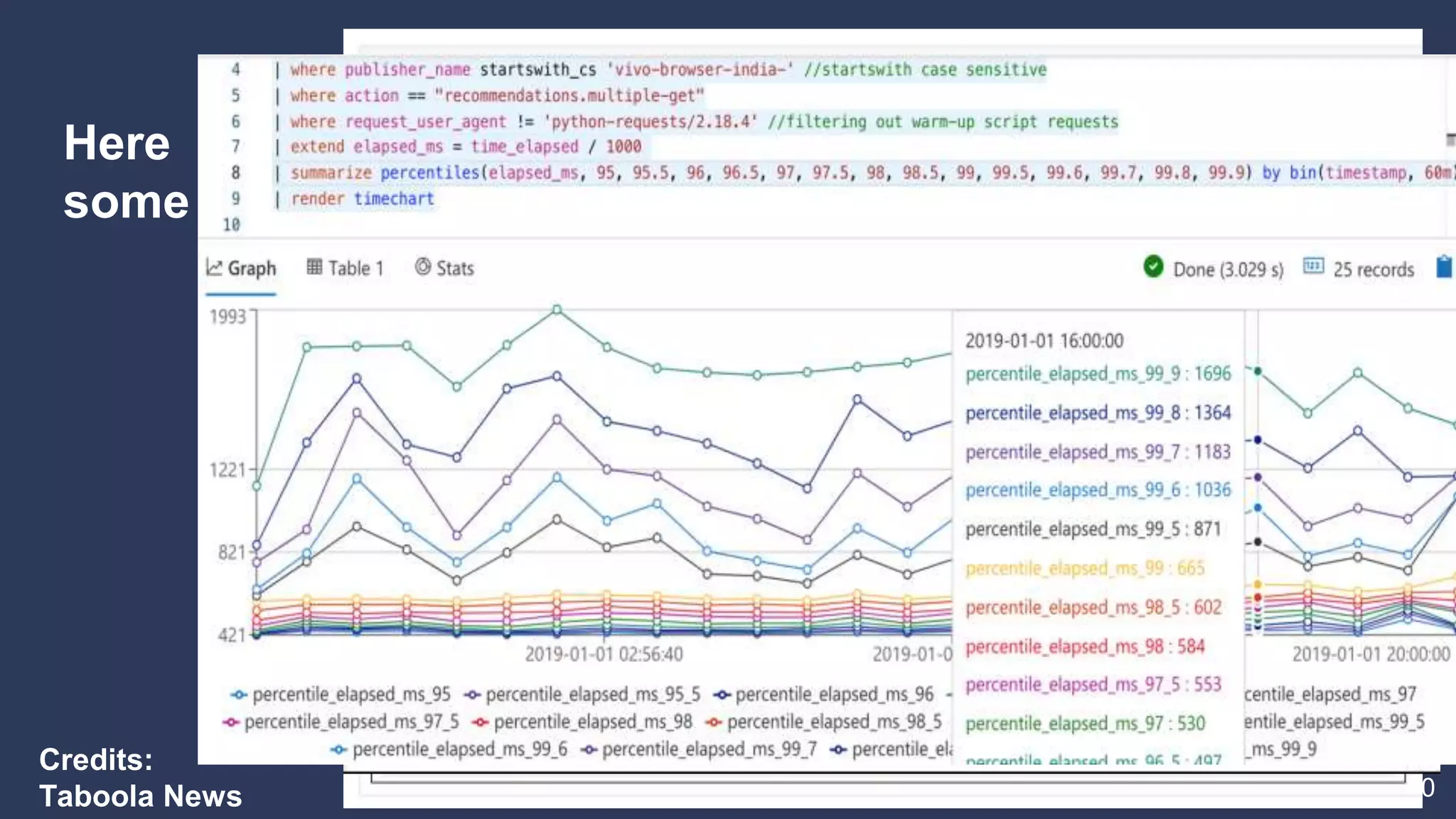
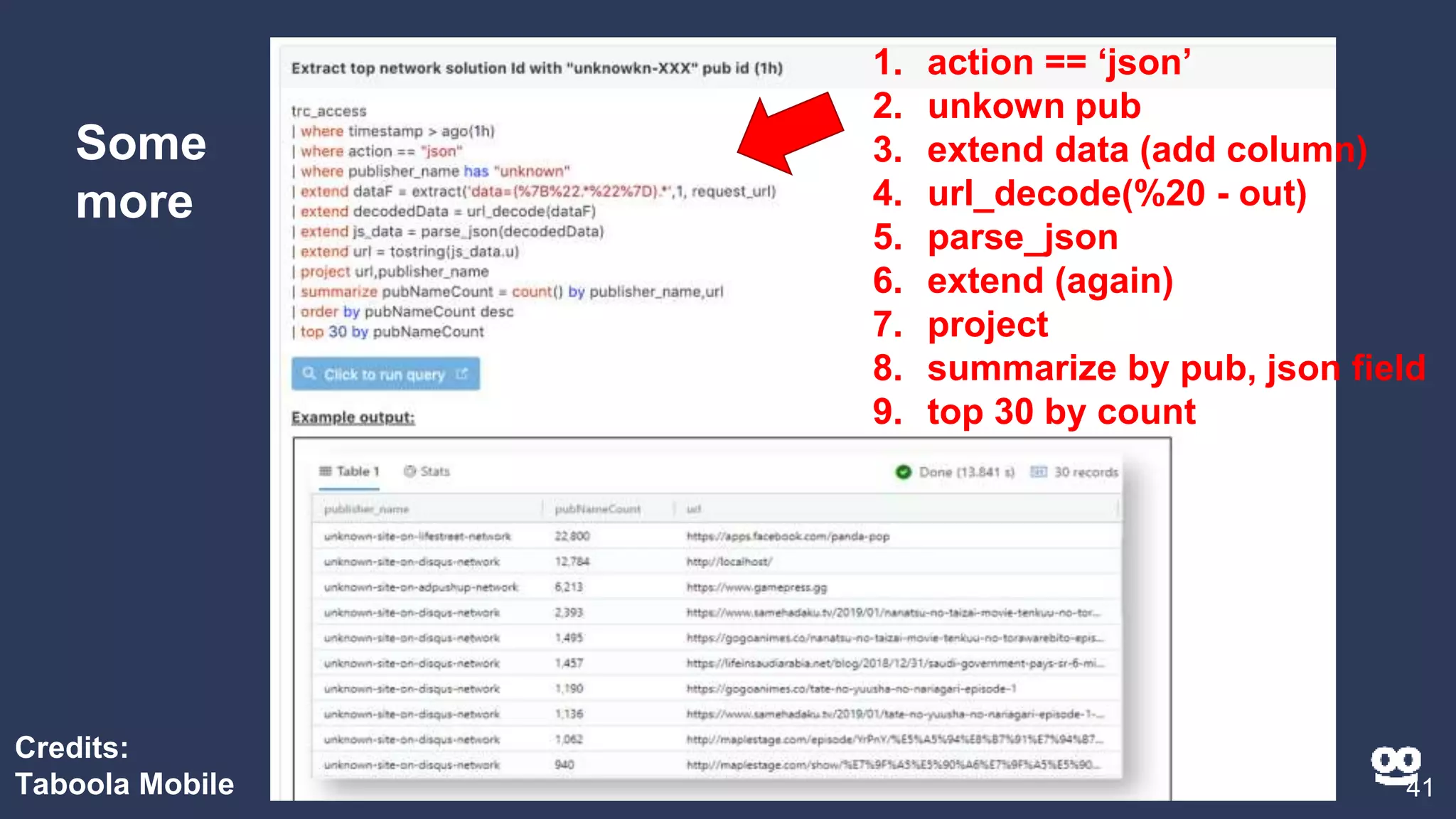
2. Examples of different Kusto query types including counting, filtering, aggregating, rendering graphs, and combining queries.
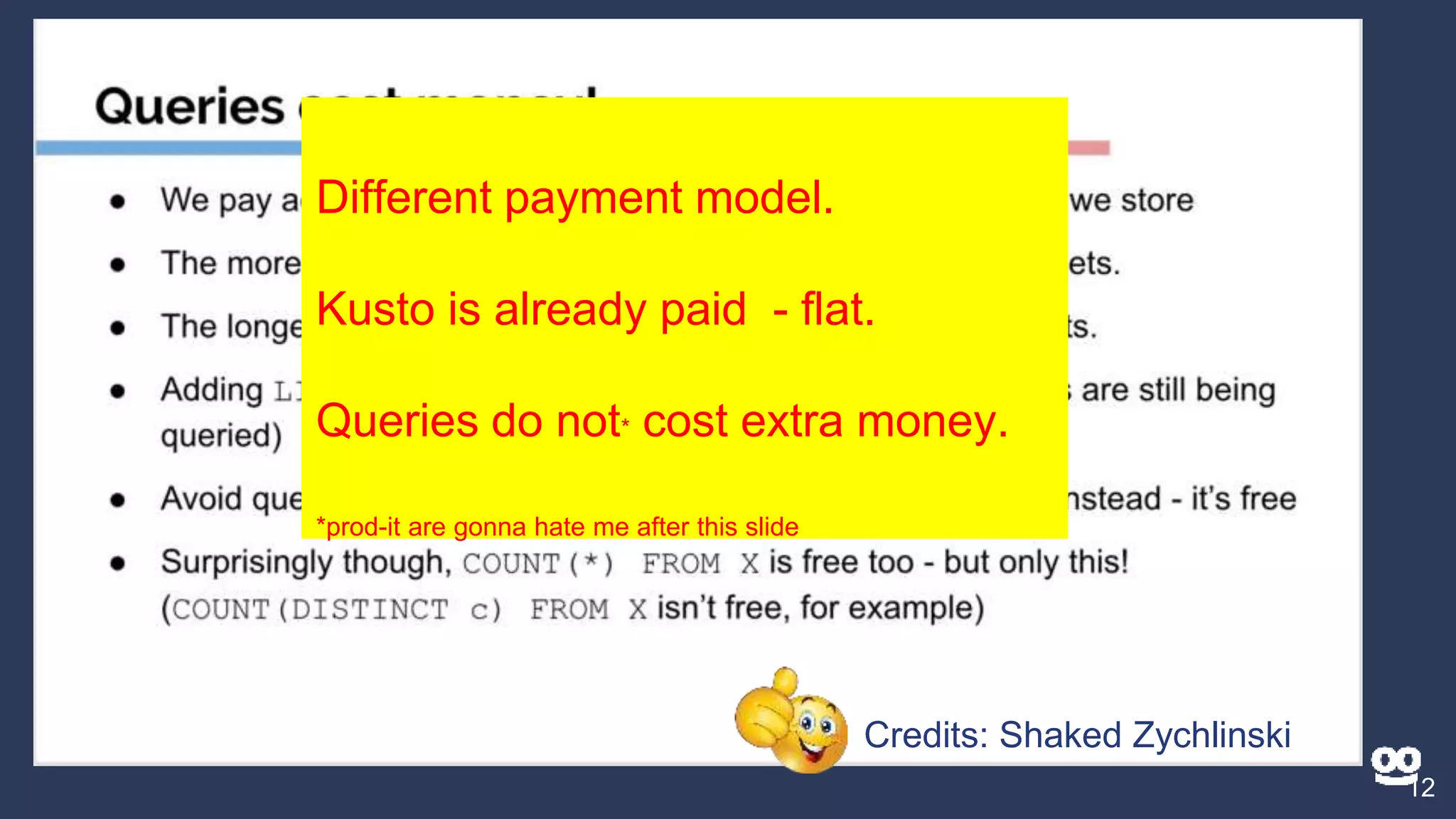
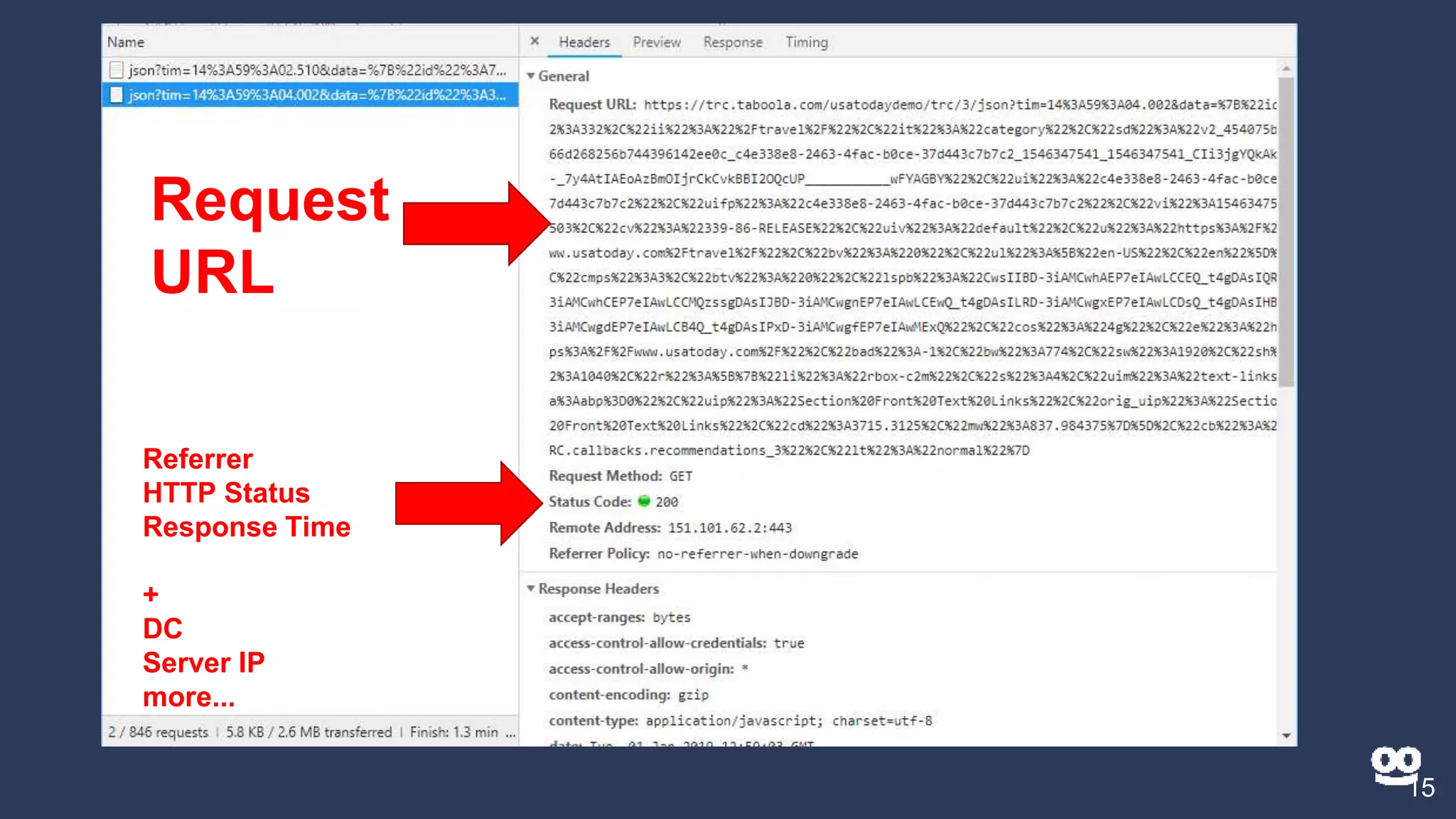
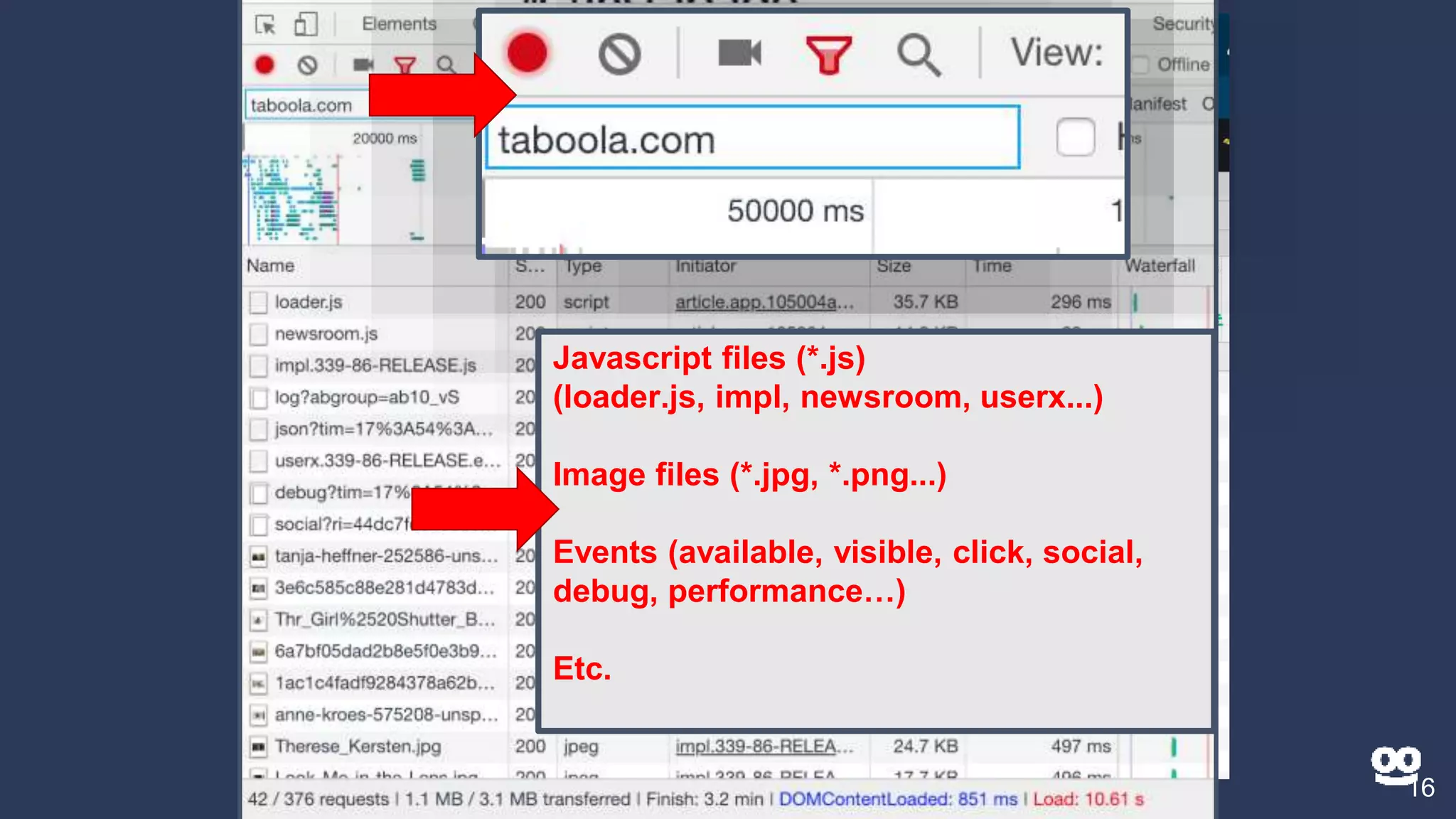
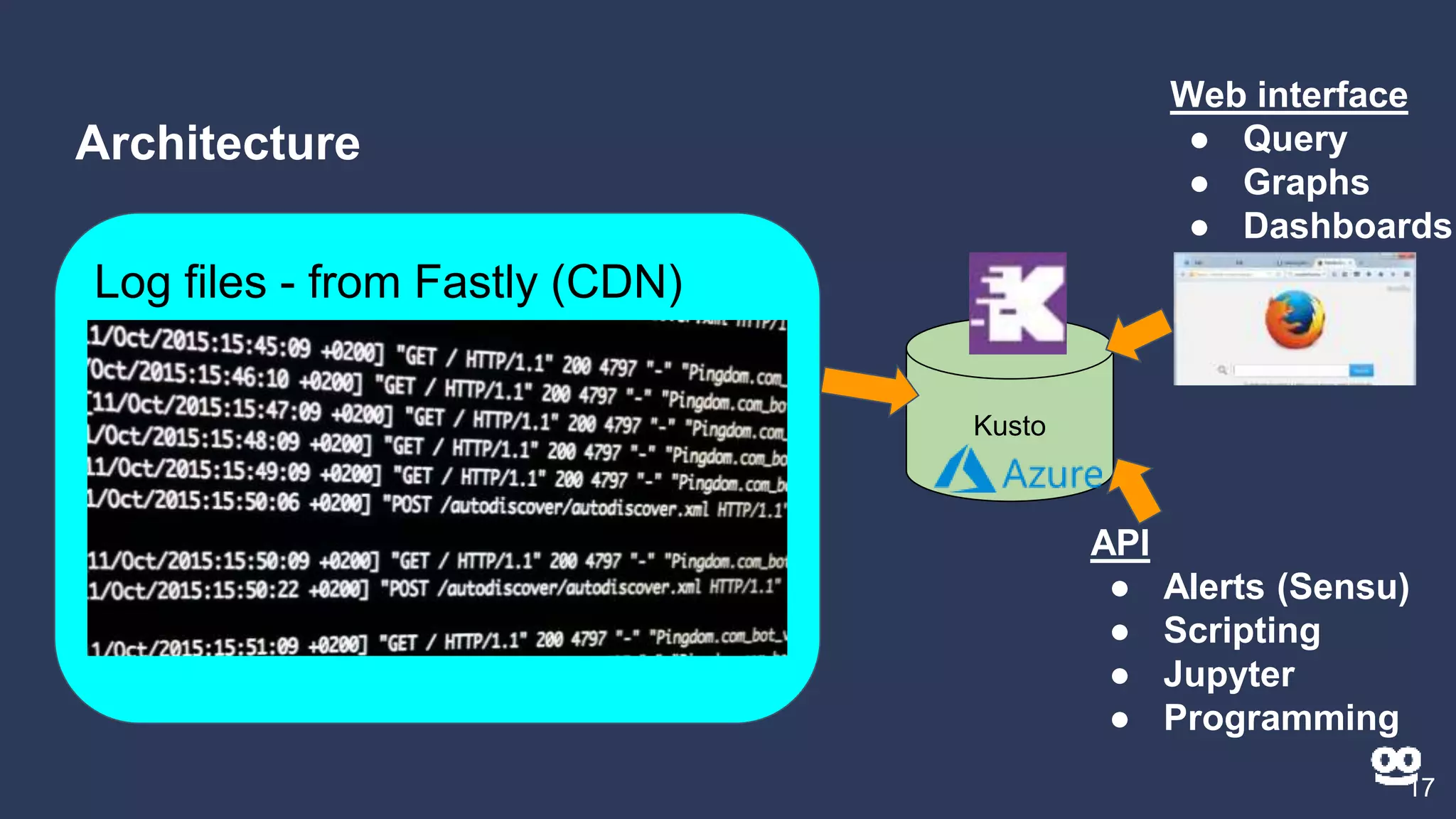
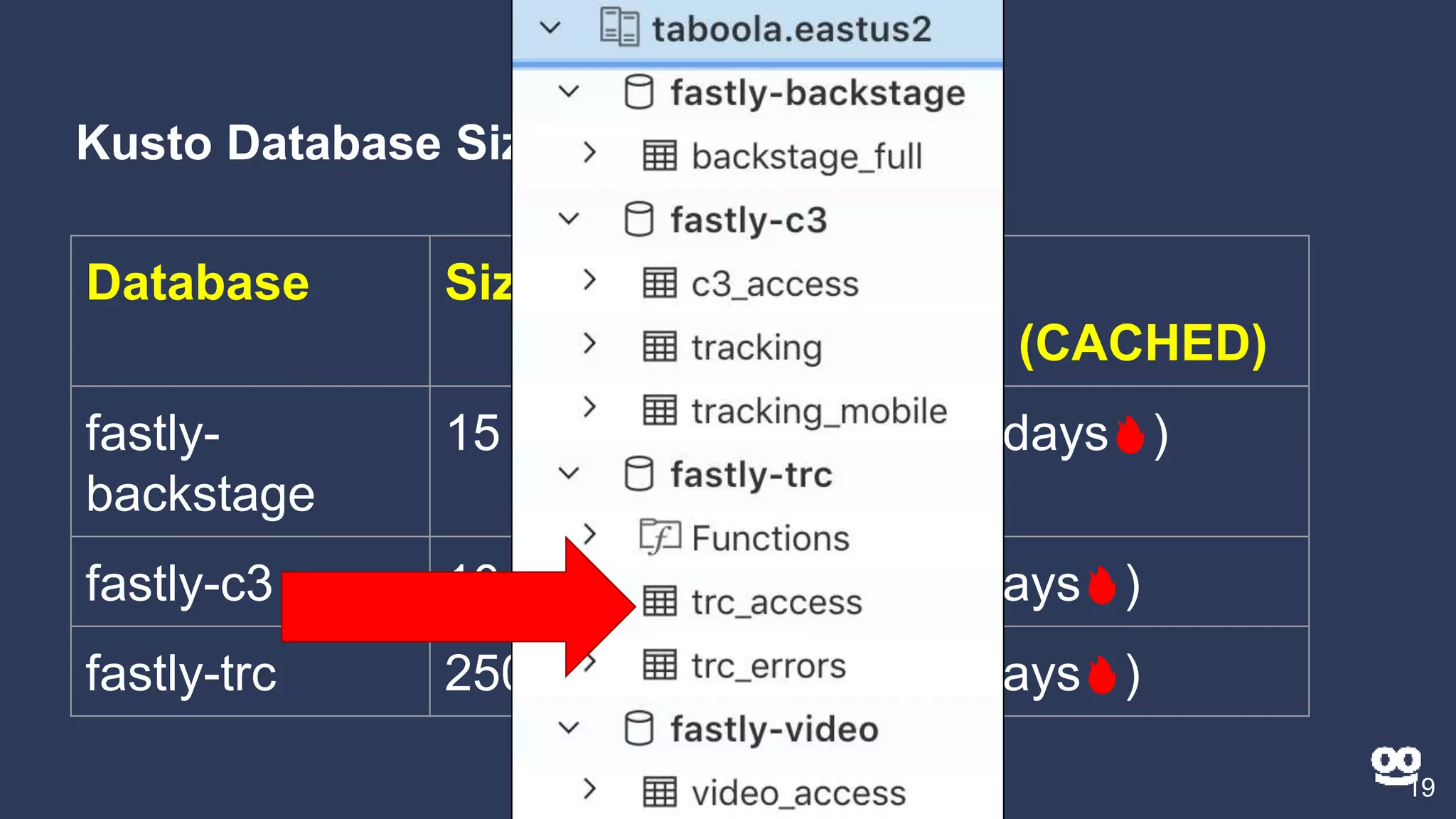
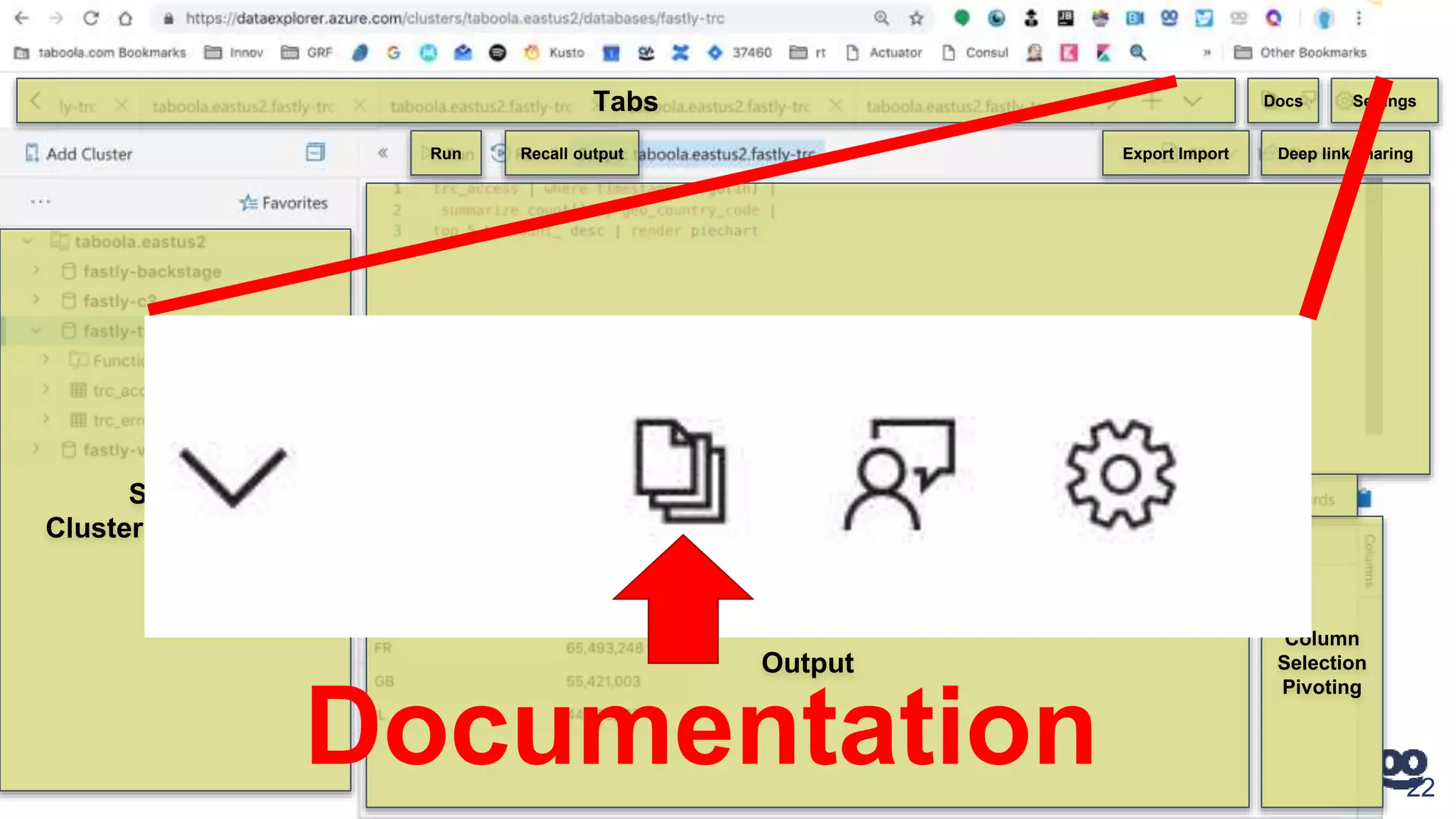
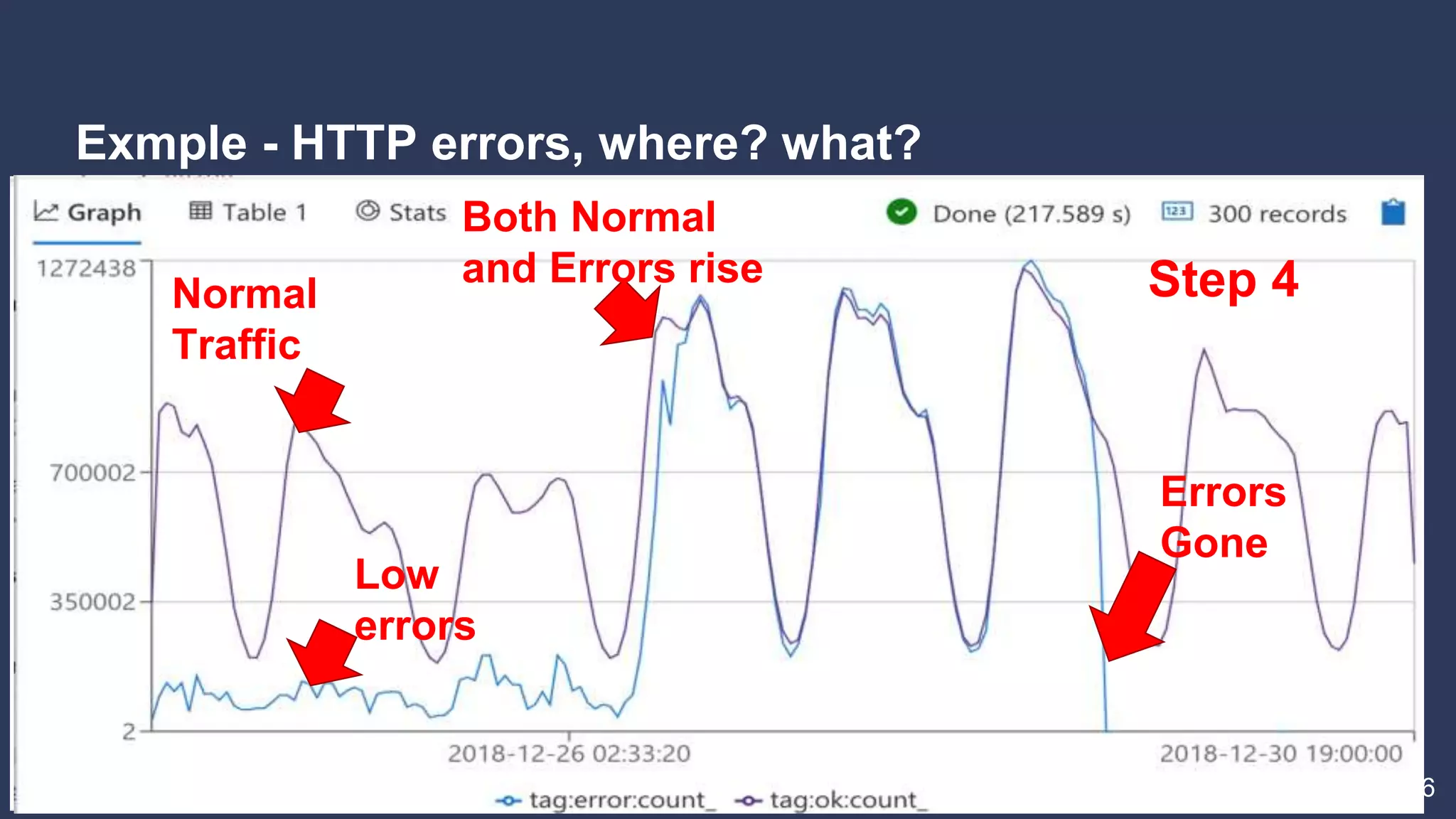
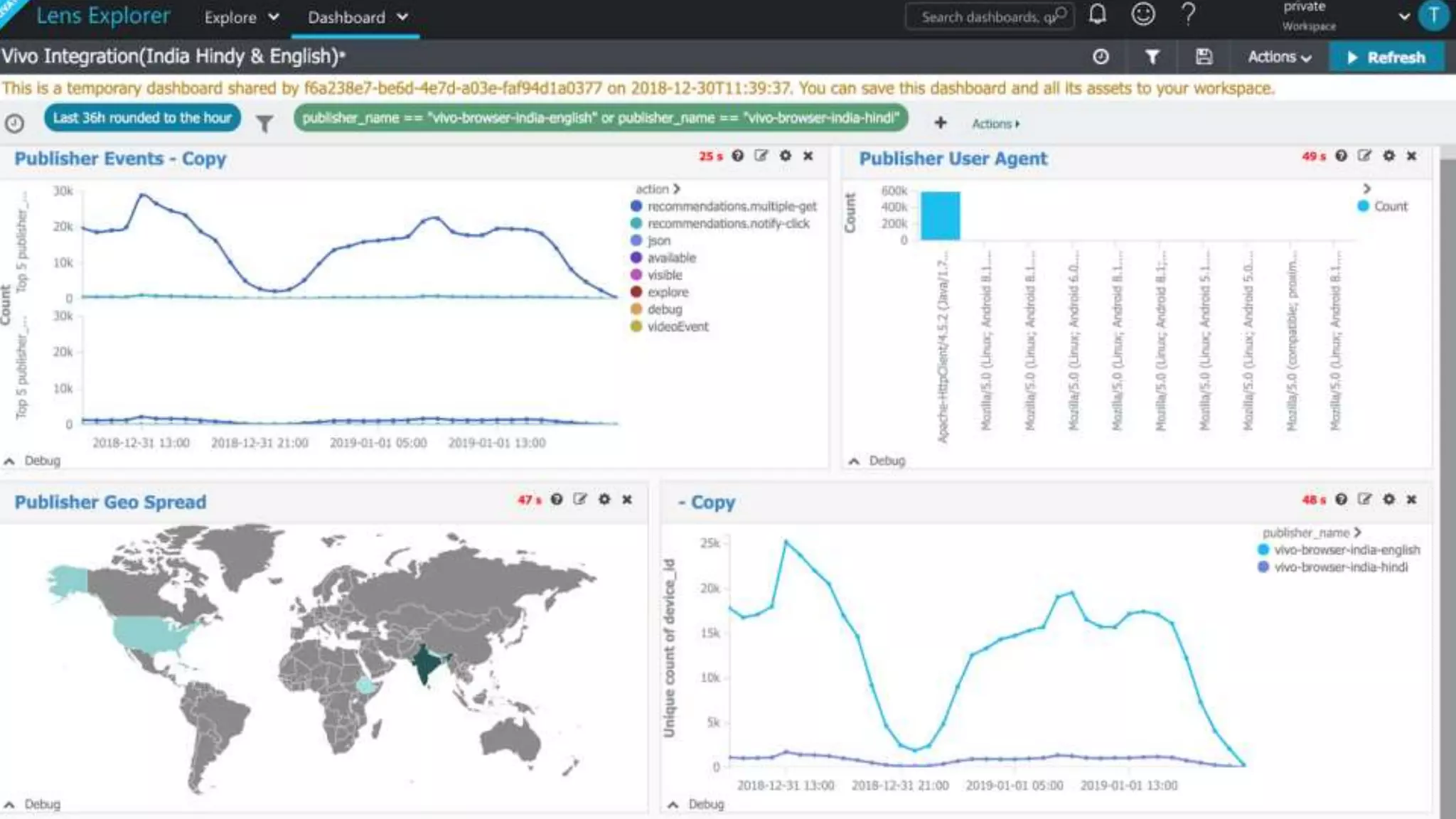
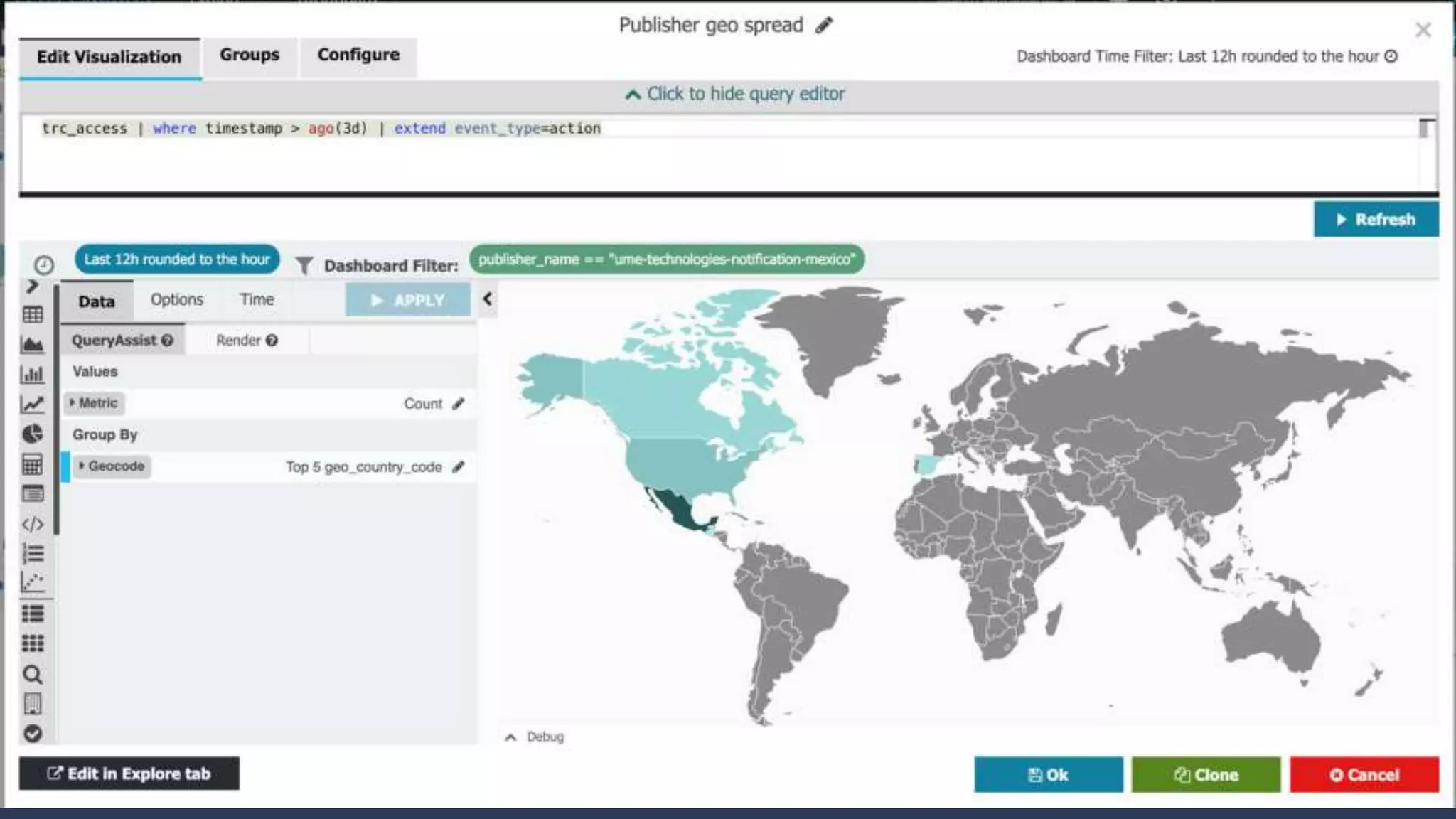
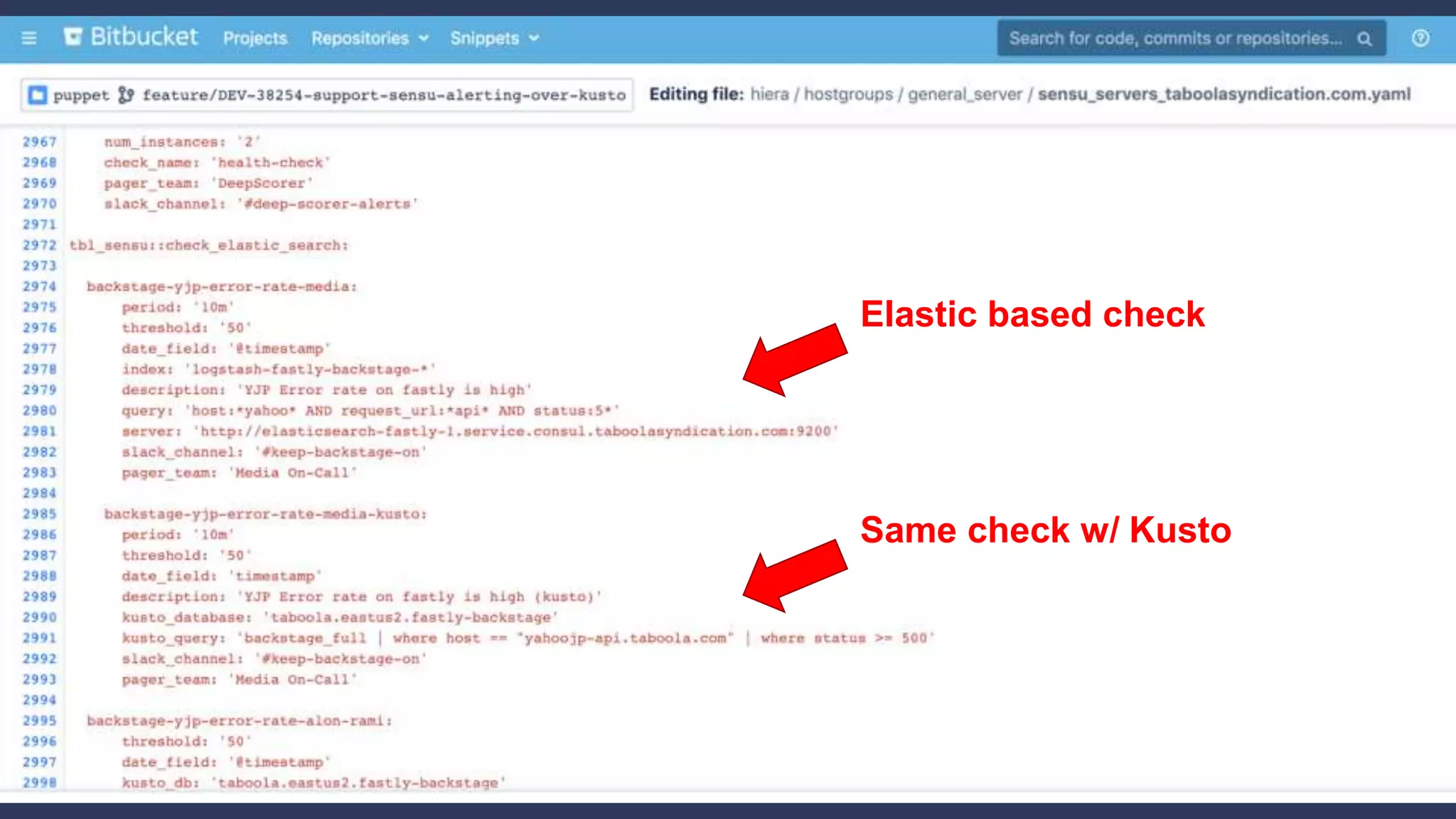
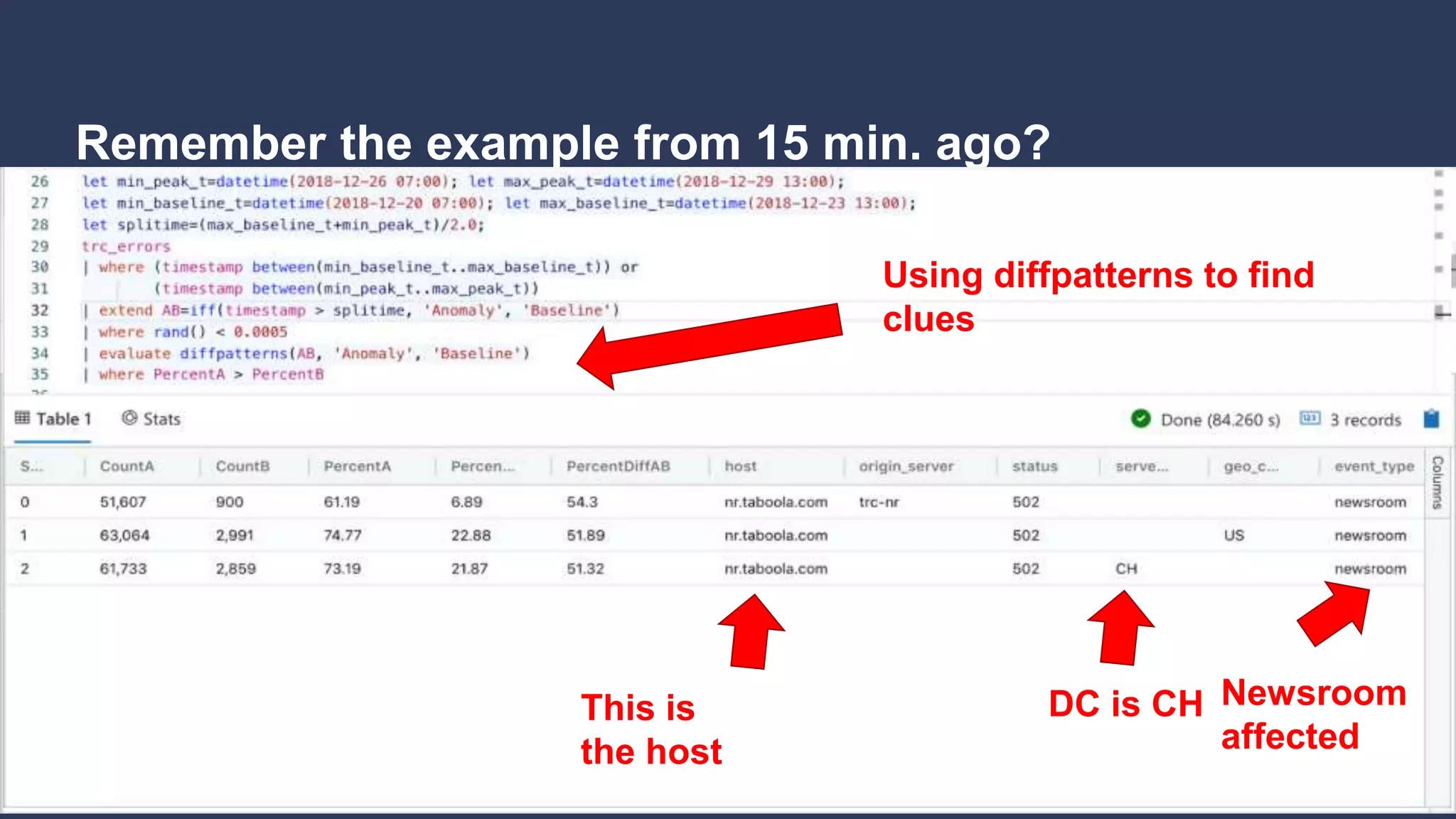
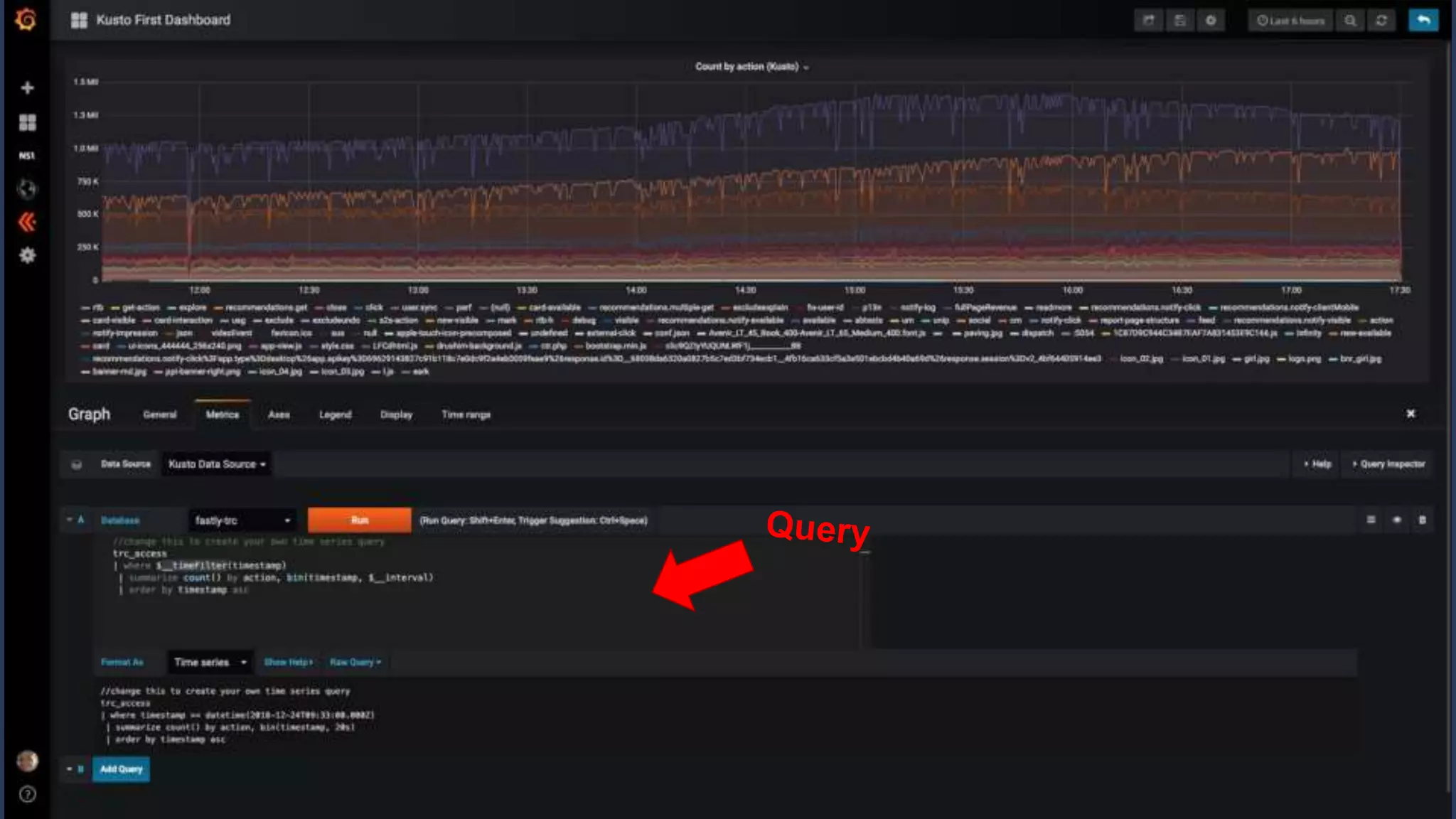
3. How Kusto is used at Taboola to analyze HTTP logs from their CDN, including database sizes and architecture.
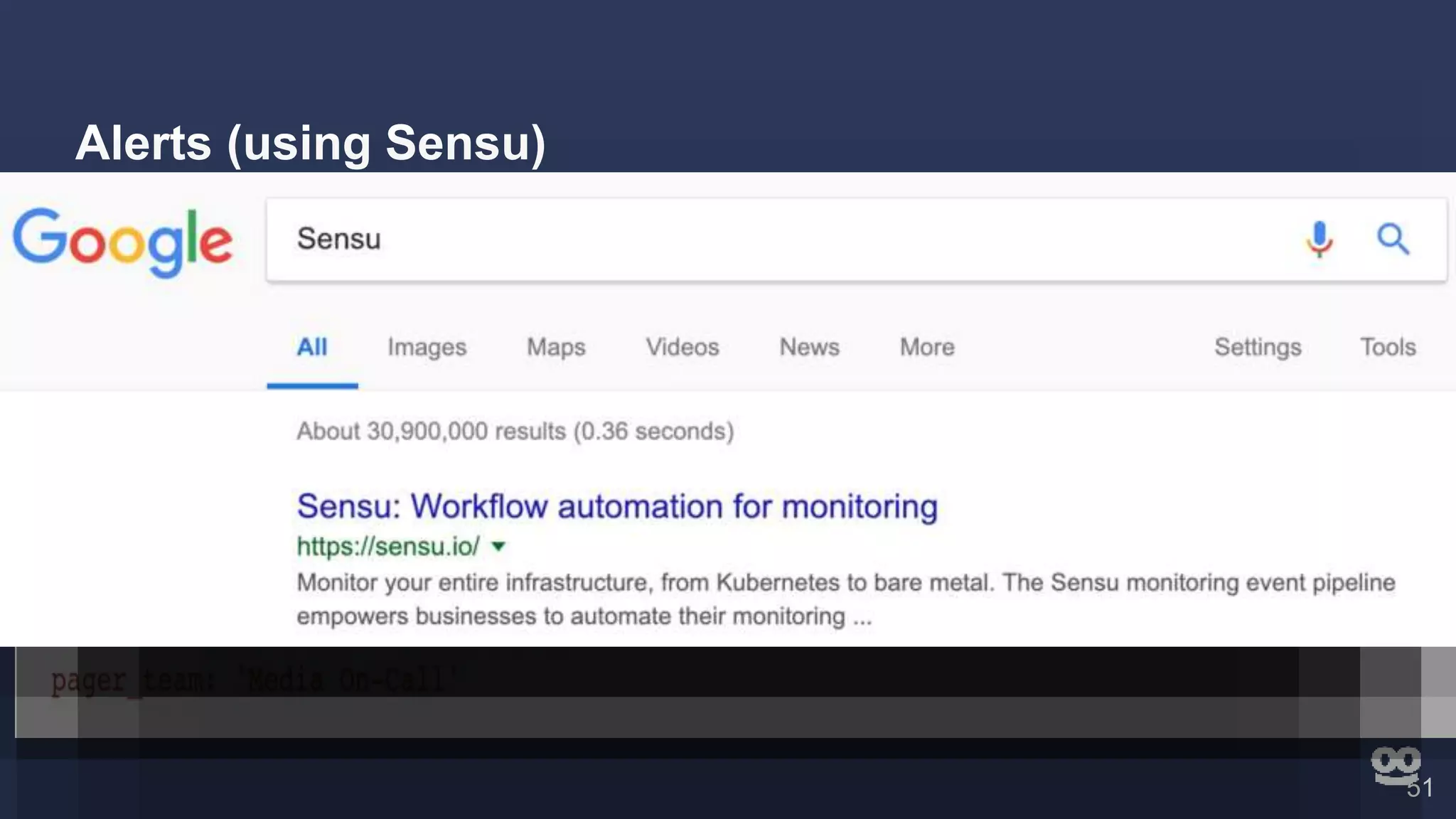
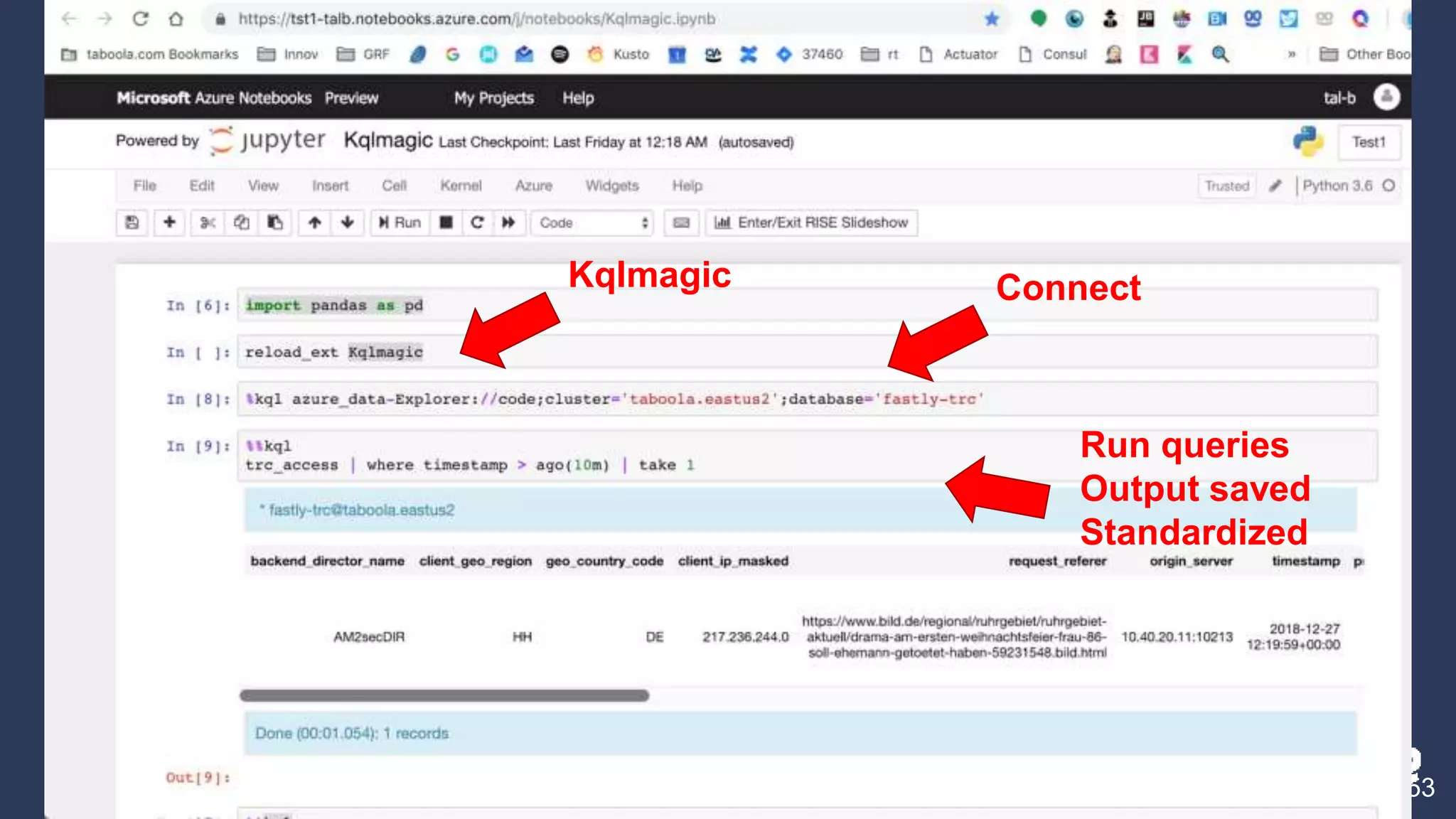
4. Additional features like dashboards, alerts, notebooks, and community resources for learning more.
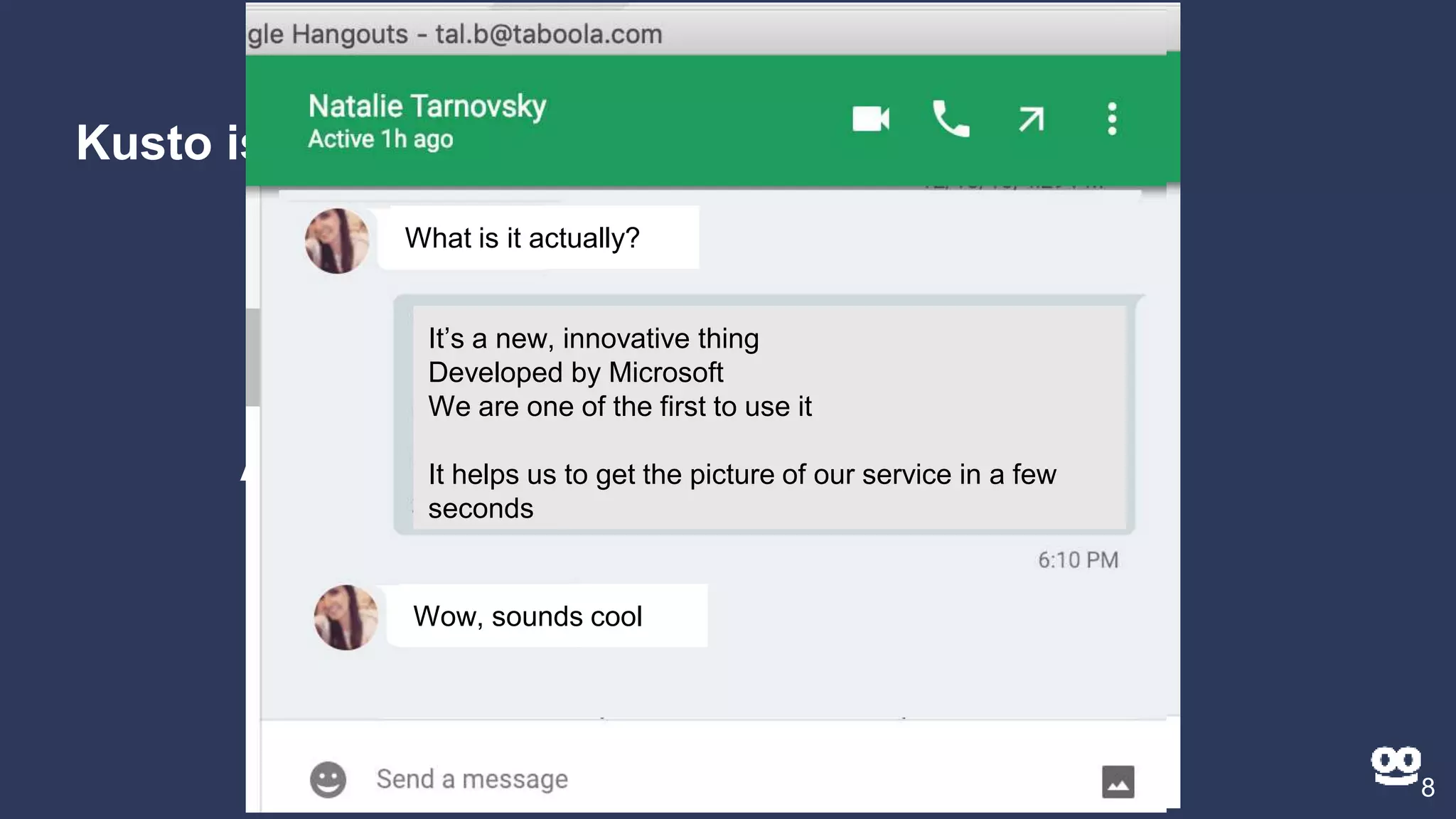
5. A question and answer session addressing common questions about Kusto.














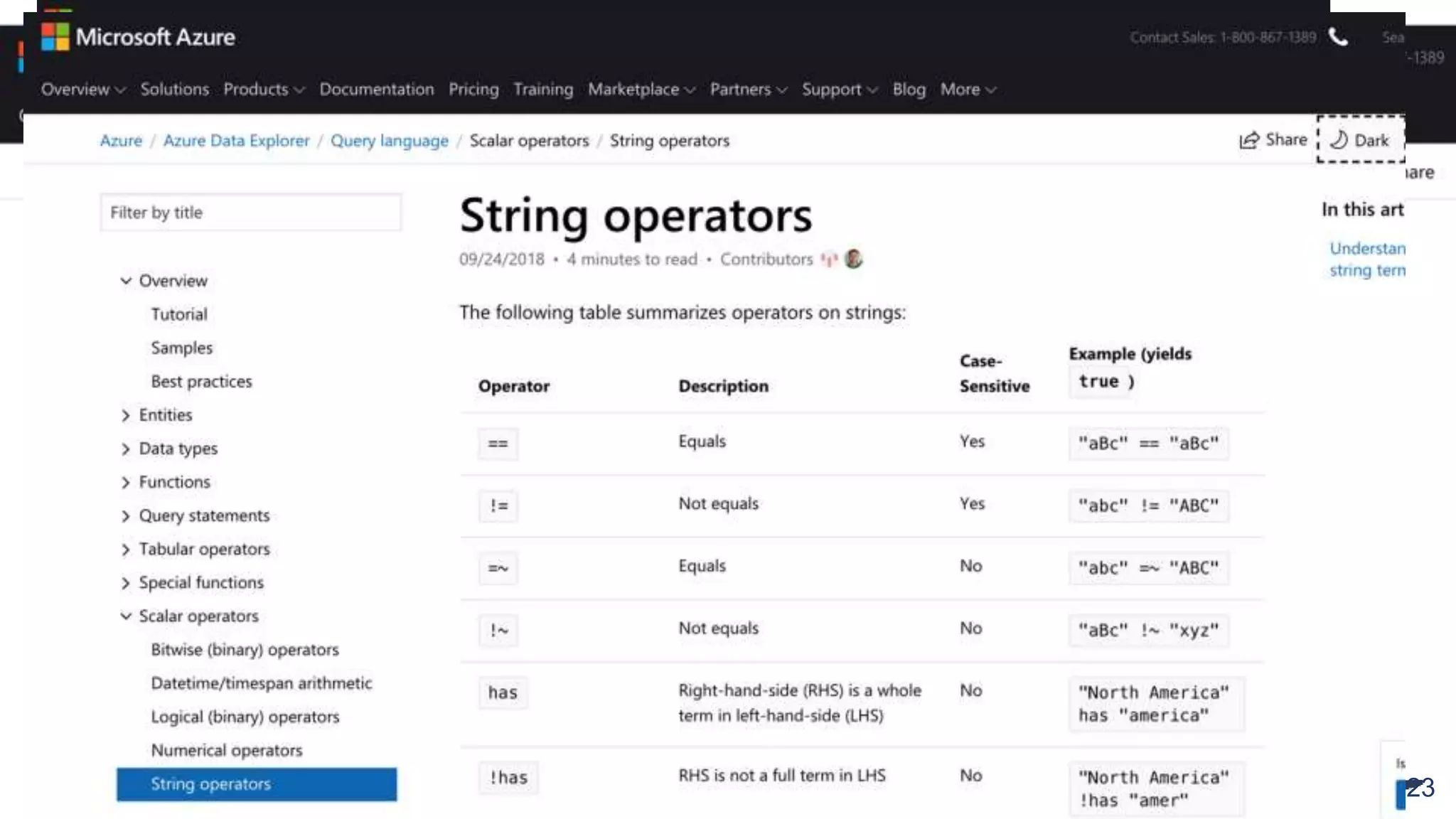
![Query - KQL
24
● Query = statement ; statement ; ….. ; statement
● At least one statement is a tabular expression
● Returns result back
source |
operator1 |
[ | operator2 ]
[ | render ]
(Taboolar?!)](https://image.slidesharecdn.com/kustotrainingforlard-jan2019-190227230322/75/Kusto-Azure-Data-Explorer-Training-for-R-D-January-2019-24-2048.jpg)




















![[B31,32]SQL Server Internal と パフォーマンスチューニング by Yukio Kumazawa](https://cdn.slidesharecdn.com/ss_thumbnails/sqlserverinternalupload-140204185245-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







![[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな](https://cdn.slidesharecdn.com/ss_thumbnails/awsxon18howfarstepfunctionsgo-211124111849-thumbnail.jpg?width=640&height=640&fit=bounds)




![S08_Microsoft 365 E5 Compliance による内部不正対策の実践 [Microsoft Japan Digital Days]](https://cdn.slidesharecdn.com/ss_thumbnails/s08microsoft365e5compliance-211028192815-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DataCon.TW 2019] Graph Query on Big-data, REST API, and Live Analysis Systems](https://cdn.slidesharecdn.com/ss_thumbnails/graphquery-datacon-190917102738-thumbnail.jpg?width=640&height=640&fit=bounds)

























