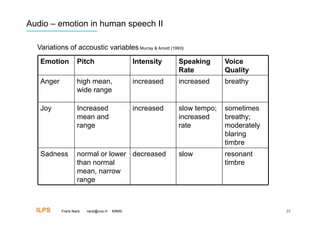
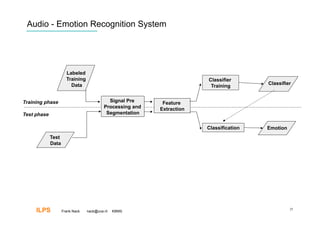
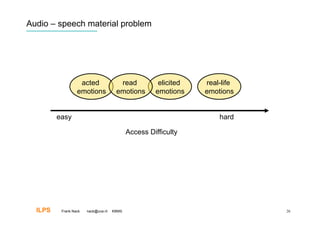
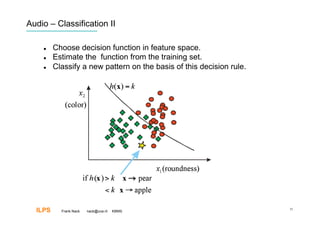
Frank Nack discusses audio and emotion recognition from speech. The document covers listening to sounds, producing sounds, and interpreting emotions from acoustic variables in speech like pitch, intensity, speech rate, and voice quality. It also discusses challenges with speech data collection and segmentation, feature extraction, and using classifiers like SVM, neural networks, decision trees, and HMM for emotion recognition. Measurement and benchmarking of audio emotion recognition systems is difficult due to varying conditions and datasets.










![Audio – Interpretation
Sound in music or human speech is about : what
and how.
The how expresses the emotional value.
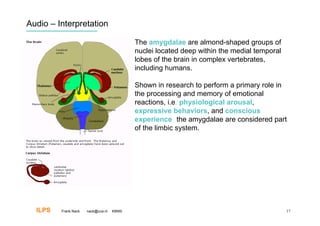
Primary emotions (i.e., innate emotions, such as
fear) depend on the limbic system circuitry, with
the amygdala and anterior cingulate gyrus being
"key players".
Secondary emotions (i.e., feelings attached to
objects [e.g., to dental drills], events, and
situations through learning) require additional
input, based largely on memory, from the
prefrontal and somatosensory cortices. The
stimulus may still be processed directly via the
amygdala but is now also analyzed in the thought
process.
ILPS Frank Nack nack@uva.nl KBMS 18](https://image.slidesharecdn.com/kbms-audio-101012090610-phpapp02/85/Kbms-audio-18-320.jpg)





























































![10[1].1.1.115.9508](https://cdn.slidesharecdn.com/ss_thumbnails/101-1-1-115-9508-101121024800-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























