Download to read offline












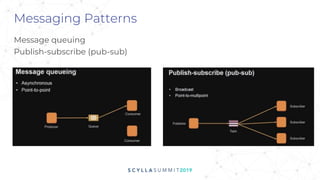







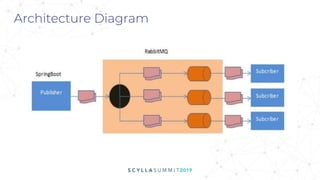



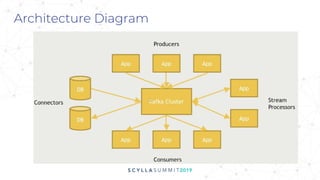
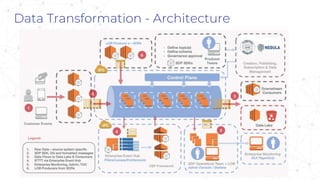














The document discusses the significance of event-driven data architectures in data transformation, focusing on various messaging systems like Amazon SQS, NATS, RabbitMQ, and Apache Kafka. It evaluates their features, advantages, and suitability based on specific company requirements while outlining architectural considerations, including availability, performance, and security. The presentation emphasizes the importance of selecting the right messaging broker to enhance system resiliency and reduce operational burdens.























































































