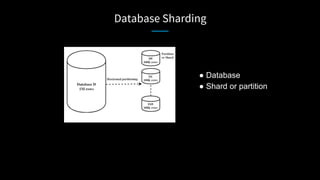
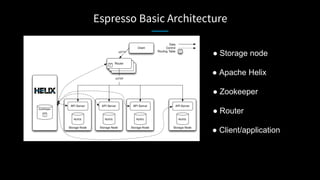
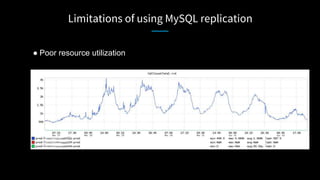
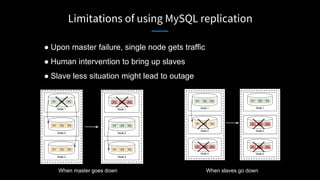
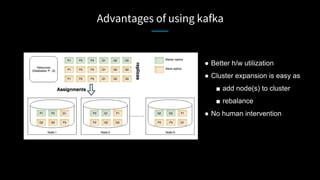
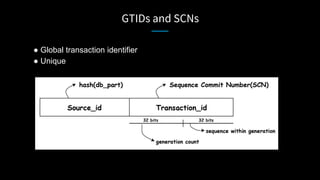
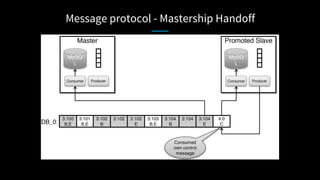
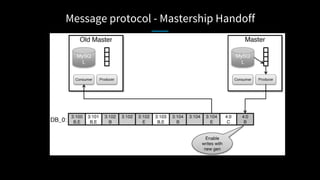
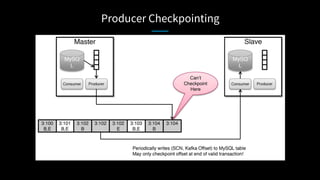
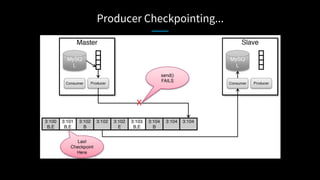
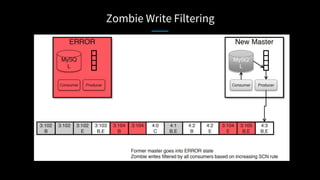
LinkedIn used Kafka to unify and scale their database infrastructure. They replaced their MySQL replication with a Kafka-based approach to allow for more flexible shard placement, easier cluster expansion, and higher availability. Using Kafka eliminated the need for a separate data replication system and provided significant cost savings compared to the previous architecture.