Downloaded 27 times









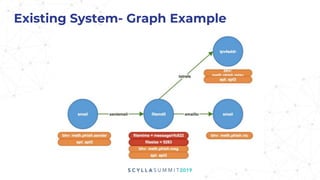










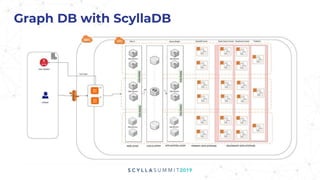

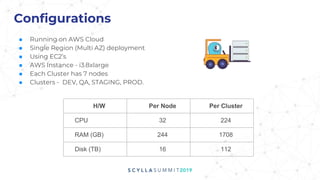



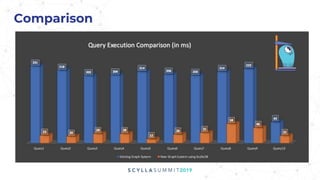





The document presents a technical overview of FireEye's use of ScyllaDB for intel threat analysis, highlighting the transition from a less efficient graph database to JanusGraph, chosen for its scalability and indexing capabilities. ScyllaDB is used as the backend storage to enhance performance and manageability, allowing for effective tracking and analysis of cyber threats. The presentation outlines the architecture, deployment, and advantages of using ScyllaDB in their security operations.













































![[DataCon.TW 2019] Graph Query on Big-data, REST API, and Live Analysis Systems](https://cdn.slidesharecdn.com/ss_thumbnails/graphquery-datacon-190917102738-thumbnail.jpg?width=640&height=640&fit=bounds)









































