Download as PDF, PPTX






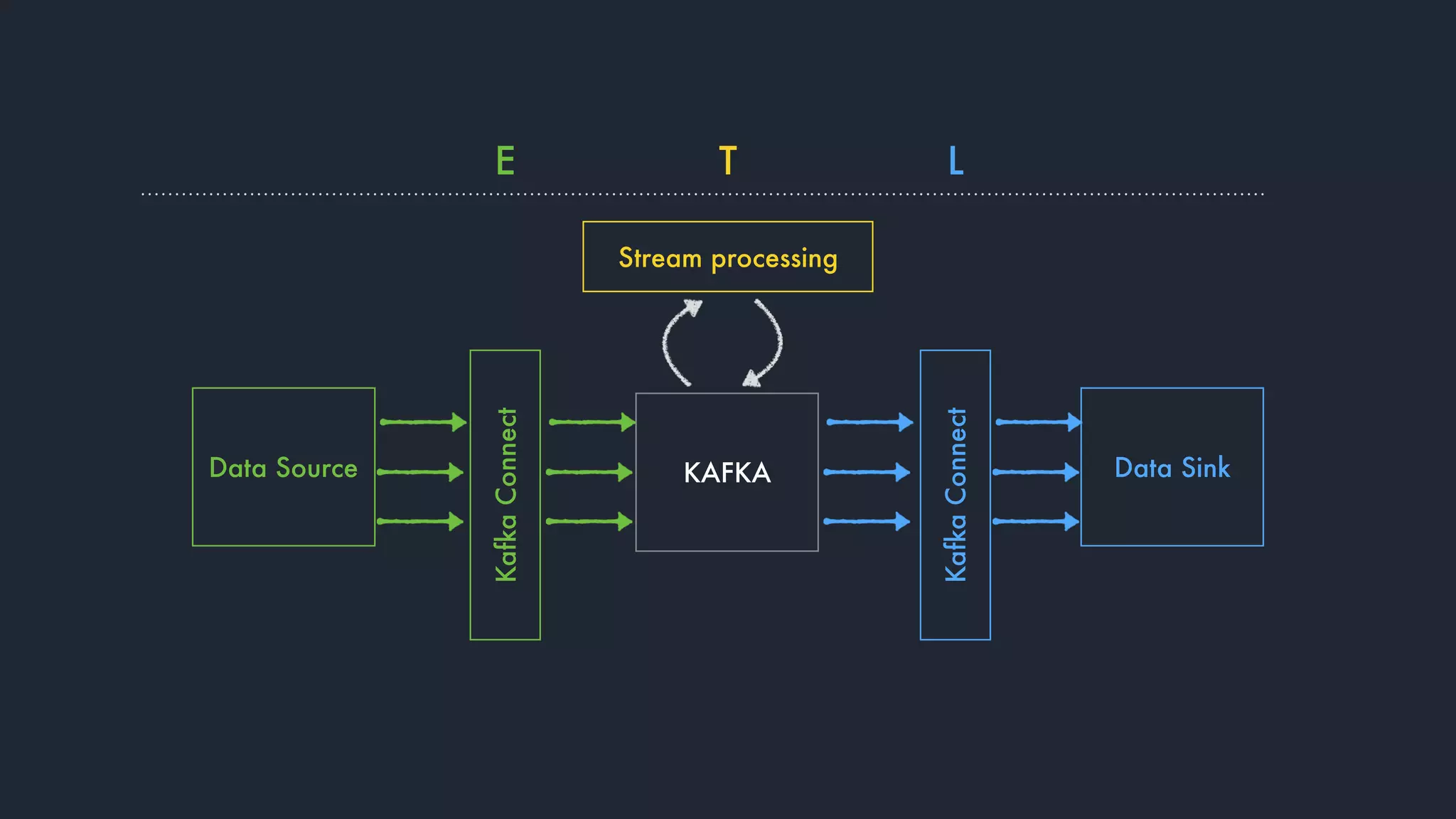





![So while integrating
Kafka with in-memory
data grid, key-value,
document stores,
NoSQL, search etc
systems..
INSERT INTO $TARGET
SELECT *|columns(i.e col1,col2 | col1 AS column1,col2)
FROM $TOPIC_NAME
[ IGNORE columns ]
[ AUTOCREATE ]
[ PK columns ]
[ AUTOEVOLVE ]
[ BATCH = N ]
[ CAPITALIZE ]
[ INITIALIZE ]
[ PARTITIONBY cola[,colb] ]
[ DISTRIBUTEBY cola[,colb] ]
[ CLUSTERBY cola[,colb] ]
[ TIMESTAMP cola|sys_current ]
[ STOREAS $YOUR_TYPE([key=value, .....]) ]
[ WITHFORMAT TEXT|AVRO|JSON|BINARY|OBJECT|MAP ]
KCQL
How does it look like?](https://image.slidesharecdn.com/london-apache-kafka-meetup-landoop-jan-2017-170120000109/75/London-Apache-Kafka-Meetup-Jan-2017-13-2048.jpg)



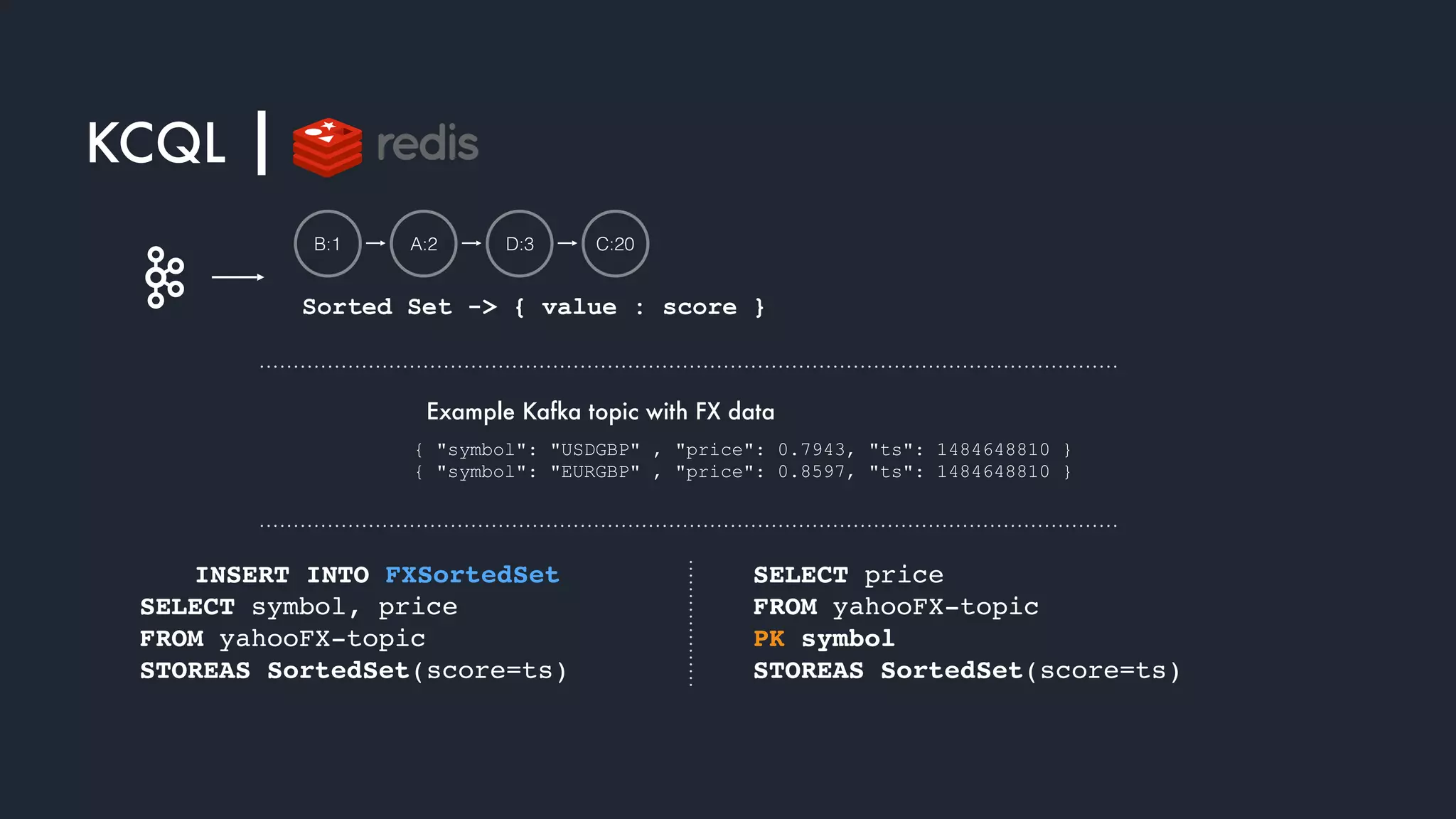




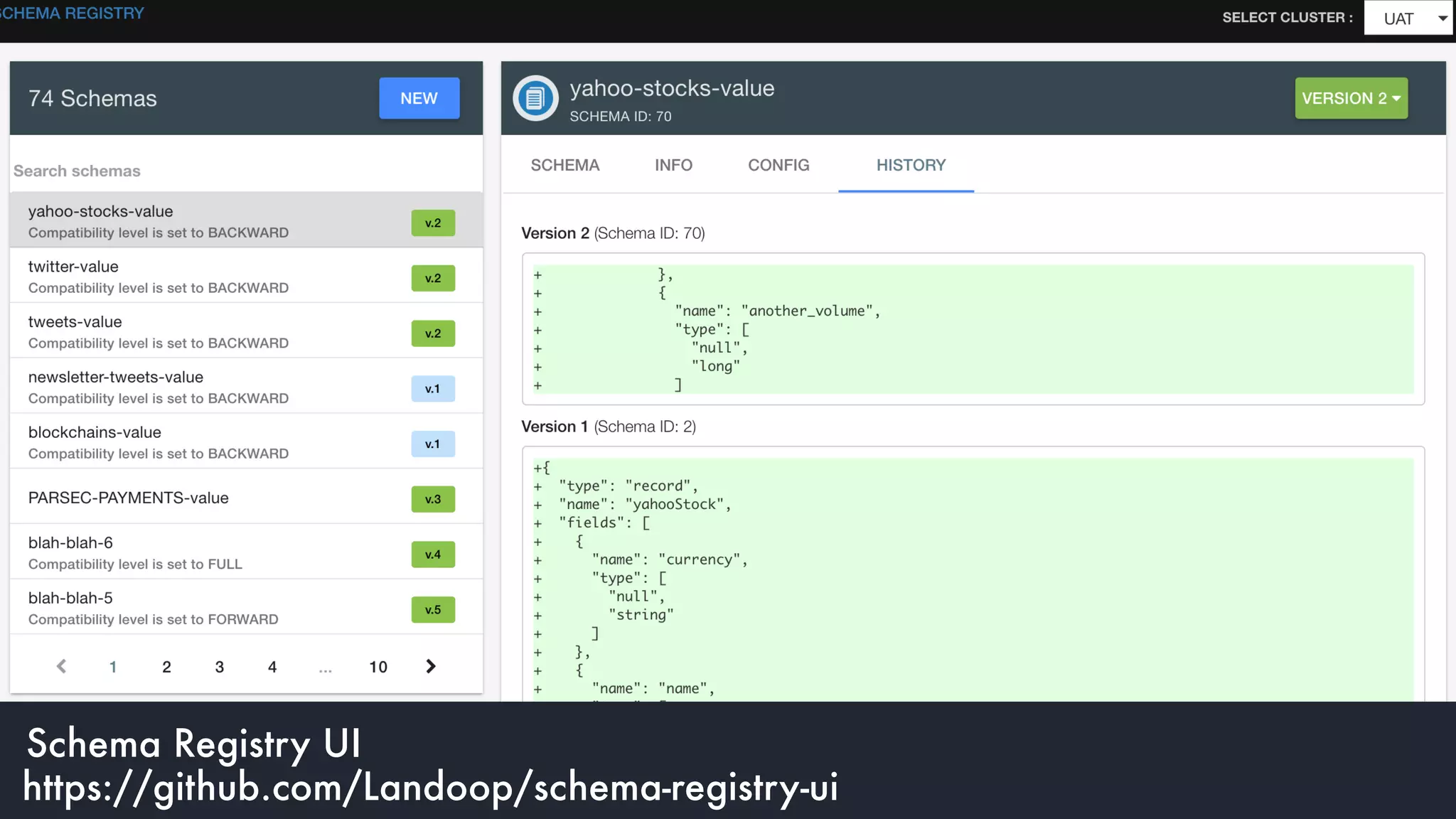
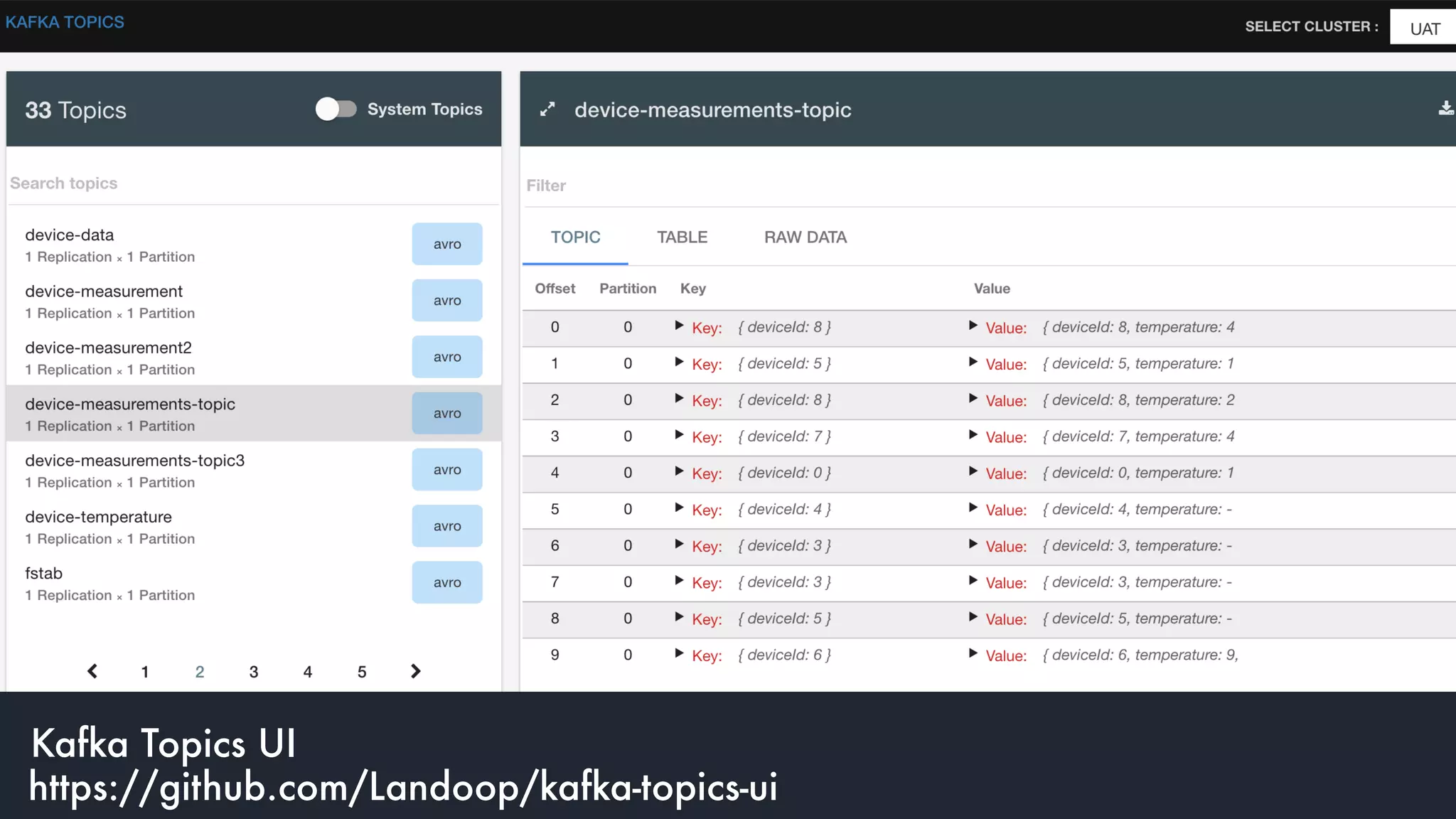
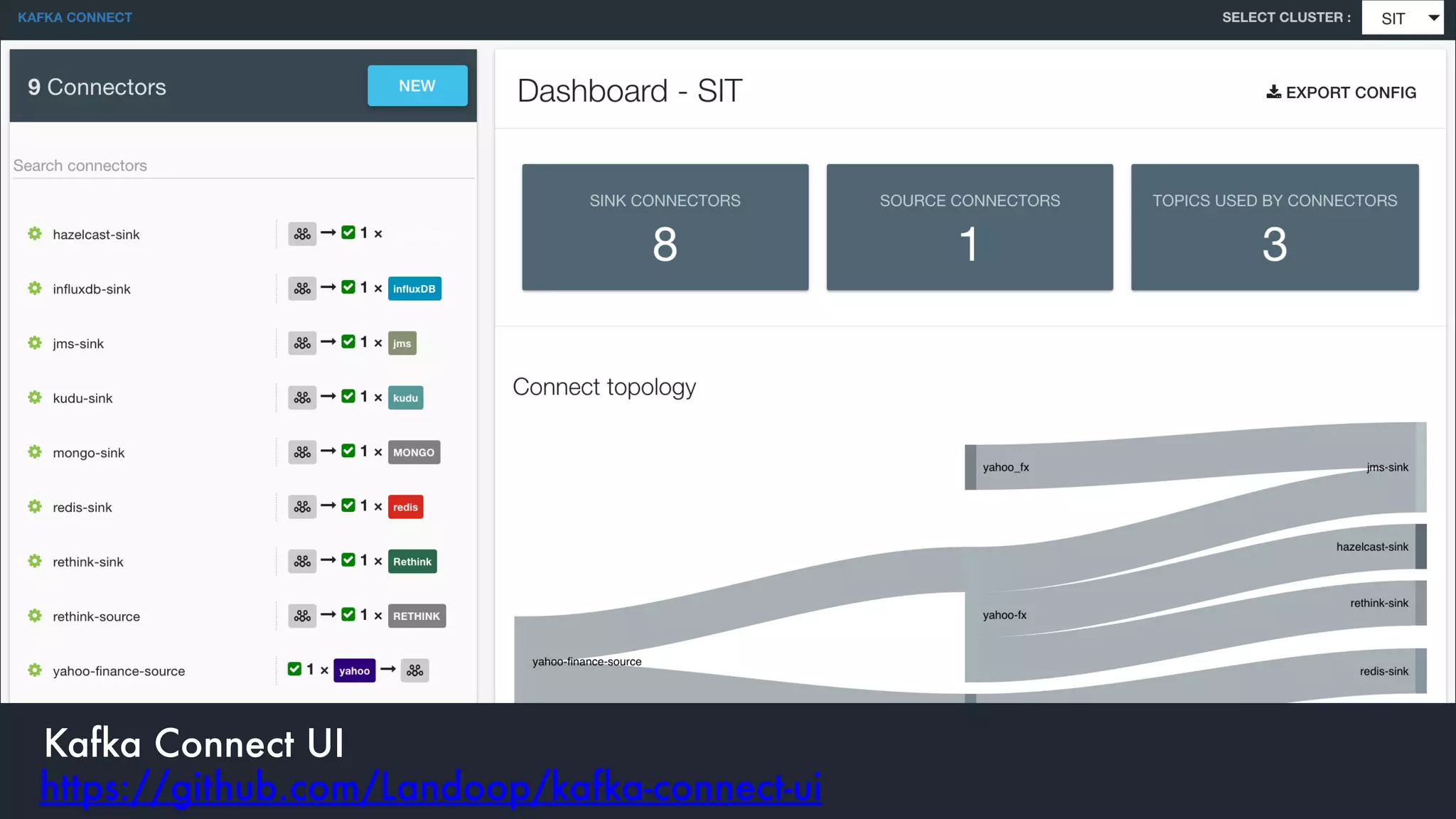
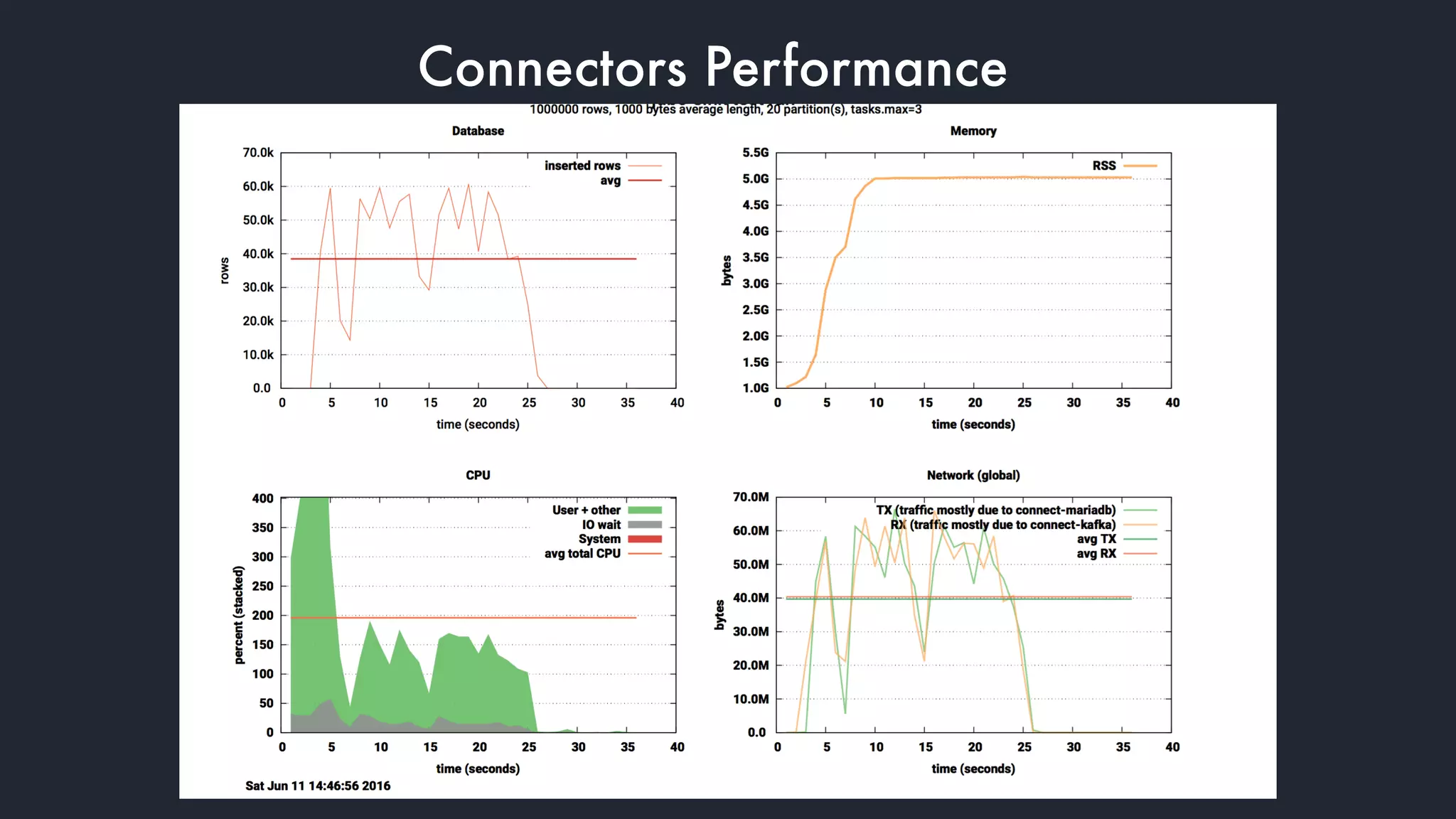
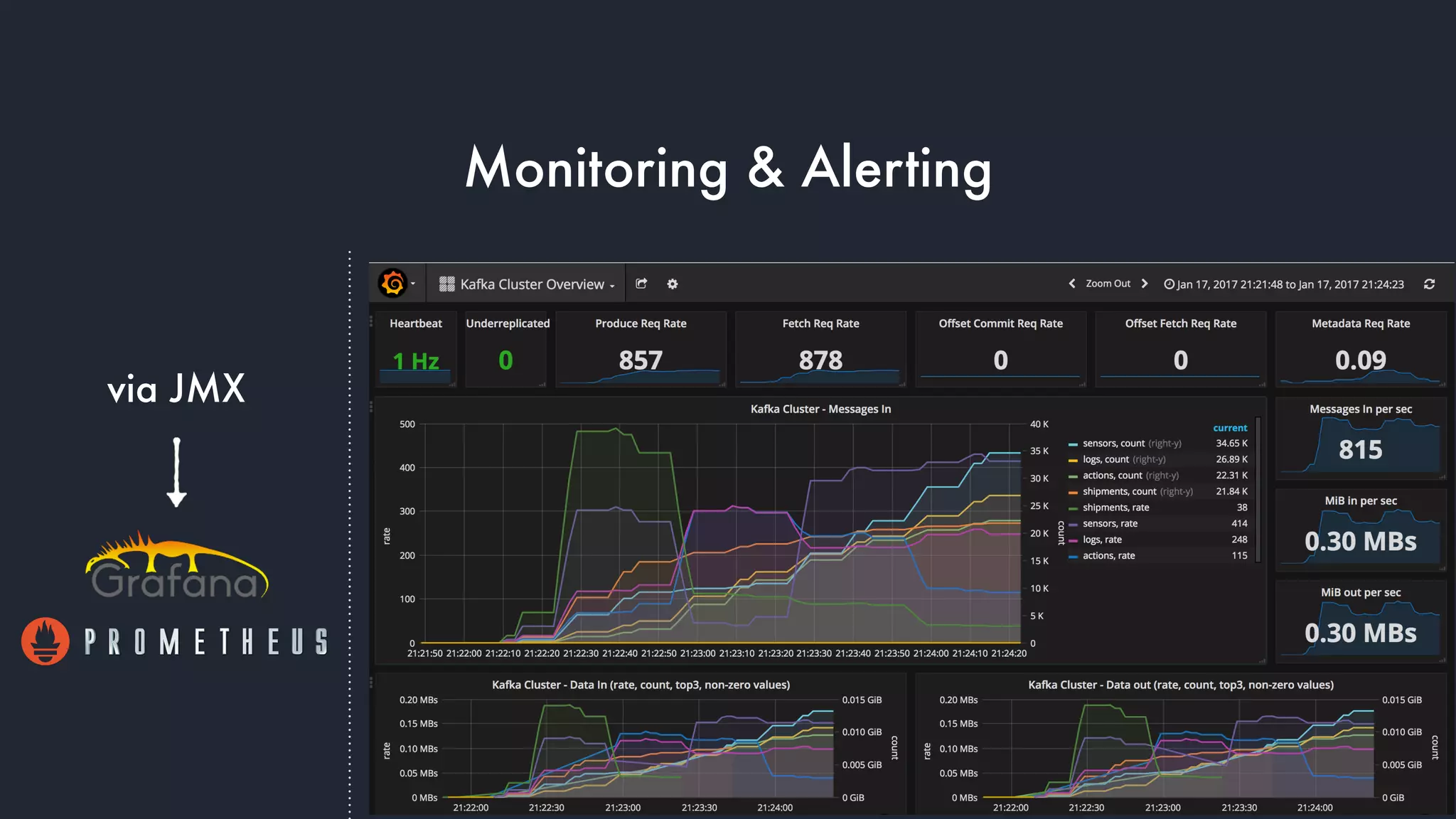

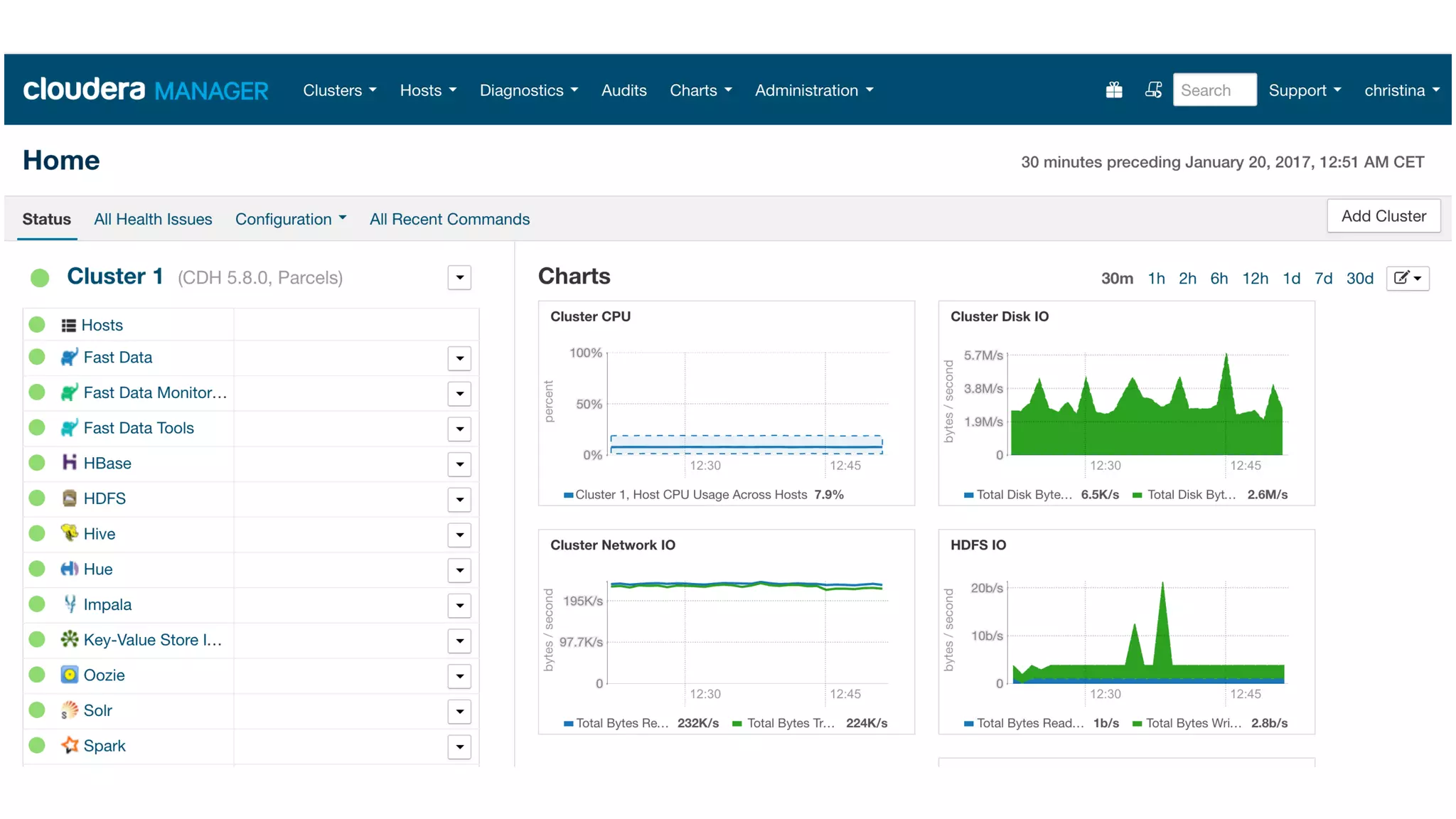
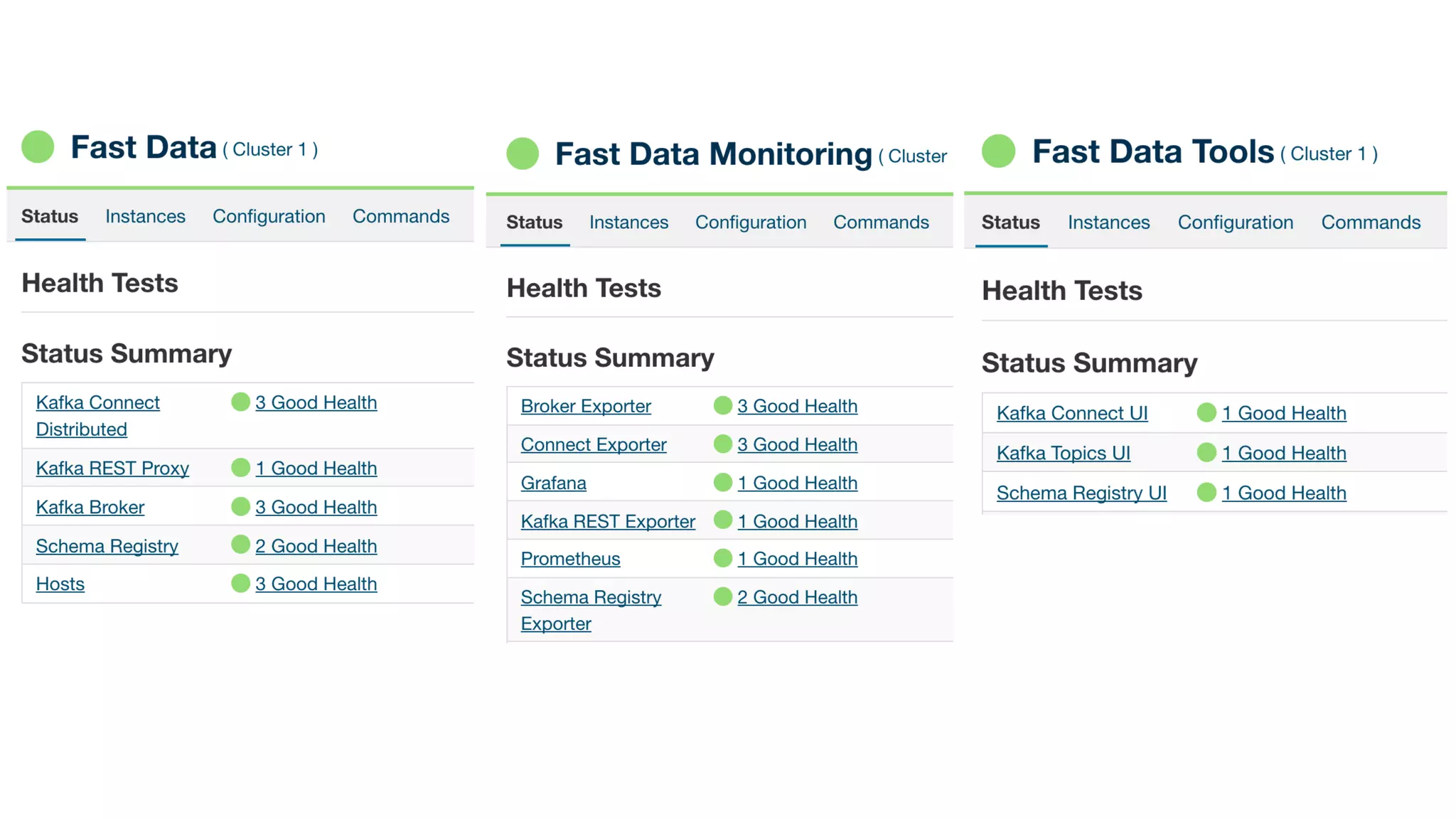

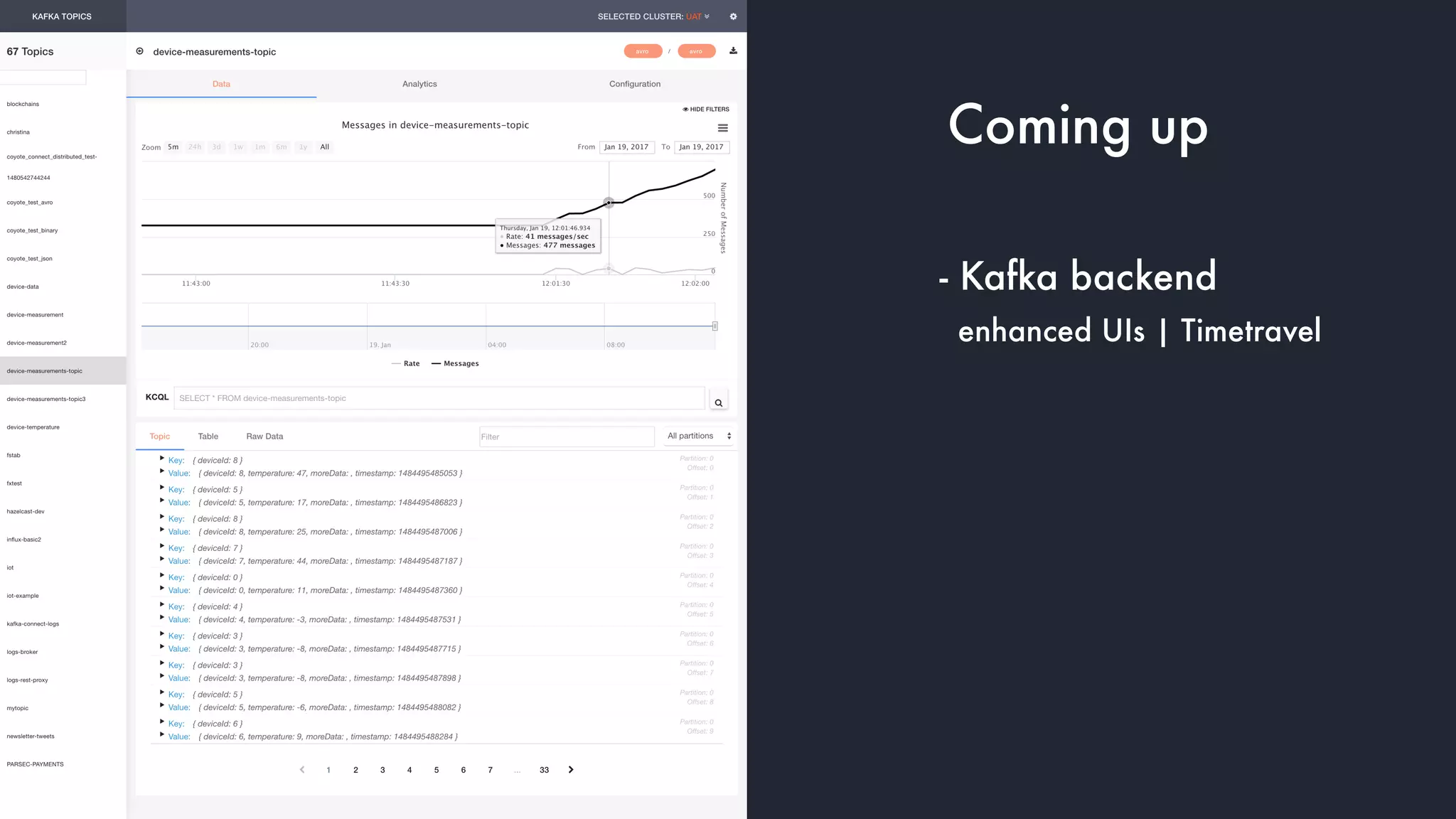



The document discusses the integration and operation of Kafka and Kafka Connect for fast data systems, highlighting its importance in managing data streams efficiently. It introduces Kafka Connect’s framework for creating connectors with a focus on KCQL, a SQL-like query language for configuring sink connectors easily. Additionally, the document mentions various connectors available, deployment options, and tools for monitoring and managing the Kafka ecosystem.
























































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)




![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)


