Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
k_oi
8,308 views
もくもくしたこと
2016/02/27のJubatusもくもく会 #2でもくもくした内容の報告資料
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 15
2
/ 15
3
/ 15
4
/ 15
5
/ 15
6
/ 15
7
/ 15
8
/ 15
9
/ 15
10
/ 15
11
/ 15
12
/ 15
13
/ 15
14
/ 15
15
/ 15
More Related Content
PDF
gRPCをちょこっと調べた話
by
Shuzo Kashihara
PDF
Iron Python / Iron Ruby で .NET Programming
by
terurou
PDF
LT: 今日帰ってすぐに始められるPython #nds45
by
civic Sasaki
PDF
78tch
by
78tch
PPTX
私の好きなPython構文 vol.2 #nds46
by
civicpg
ODP
LKFT作ってみた
by
sirrow
PPTX
GPT
by
norimatsu5
PPTX
tsudaりについて
by
Yoshikazu GOTO
gRPCをちょこっと調べた話
by
Shuzo Kashihara
Iron Python / Iron Ruby で .NET Programming
by
terurou
LT: 今日帰ってすぐに始められるPython #nds45
by
civic Sasaki
78tch
by
78tch
私の好きなPython構文 vol.2 #nds46
by
civicpg
LKFT作ってみた
by
sirrow
GPT
by
norimatsu5
tsudaりについて
by
Yoshikazu GOTO
What's hot
PDF
先取り Go1.5
by
Preferred Networks
PDF
Javascriptを書きたくないヒ トのためのPythonScript
by
Kazufumi Ohkawa
PDF
5社のGTFSをマージして、PostgreSQLにインポートしてみた
by
Masaki Ito
PDF
Log Analysis System And its designs in LINE Corp. 2014 early
by
SATOSHI TAGOMORI
KEY
HexRinger と FOSS4G の紆余曲折
by
Hironov OKUYAMA
PPTX
Pynyumon03 LT
by
drillan
PDF
HTTP2 RFC 発行記念祝賀会
by
Jxck Jxck
先取り Go1.5
by
Preferred Networks
Javascriptを書きたくないヒ トのためのPythonScript
by
Kazufumi Ohkawa
5社のGTFSをマージして、PostgreSQLにインポートしてみた
by
Masaki Ito
Log Analysis System And its designs in LINE Corp. 2014 early
by
SATOSHI TAGOMORI
HexRinger と FOSS4G の紆余曲折
by
Hironov OKUYAMA
Pynyumon03 LT
by
drillan
HTTP2 RFC 発行記念祝賀会
by
Jxck Jxck
Viewers also liked
PPTX
"アレ"からJubatusを使う
by
JubatusOfficial
PDF
Jubatusハンズオン 機械学習はじめてみた
by
JubatusOfficial
PPTX
もくもく成果 IMAMASU
by
JubatusOfficial
PDF
単語コレクター(文章自動校正器)
by
JubatusOfficial
PPTX
Jubatus 1.0 の紹介
by
JubatusOfficial
PPTX
新機能紹介 1.0.6
by
JubatusOfficial
PPTX
発言小町からのプロファイリング
by
JubatusOfficial
ODP
小町のレス数が予測できるか試してみた
by
JubatusOfficial
PPTX
かまってちゃん小町
by
JubatusOfficial
PDF
Python 特徴抽出プラグイン
by
JubatusOfficial
PDF
Jubakitの解説
by
JubatusOfficial
PPTX
新聞から今年の漢字を予測する
by
JubatusOfficial
PDF
Jubatus解説本の紹介
by
JubatusOfficial
PPTX
銀座のママ
by
JubatusOfficial
PPTX
小町の溜息
by
JubatusOfficial
PPTX
JUBARHYME
by
JubatusOfficial
PDF
地域の魅力を伝えるツアーガイドAI
by
JubatusOfficial
PDF
FIT2012招待講演「異常検知技術のビジネス応用最前線」
by
Shohei Hido
PDF
Jubakit の紹介
by
kmaehashi
PDF
Jubatus 新機能ハイライト
by
JubatusOfficial
"アレ"からJubatusを使う
by
JubatusOfficial
Jubatusハンズオン 機械学習はじめてみた
by
JubatusOfficial
もくもく成果 IMAMASU
by
JubatusOfficial
単語コレクター(文章自動校正器)
by
JubatusOfficial
Jubatus 1.0 の紹介
by
JubatusOfficial
新機能紹介 1.0.6
by
JubatusOfficial
発言小町からのプロファイリング
by
JubatusOfficial
小町のレス数が予測できるか試してみた
by
JubatusOfficial
かまってちゃん小町
by
JubatusOfficial
Python 特徴抽出プラグイン
by
JubatusOfficial
Jubakitの解説
by
JubatusOfficial
新聞から今年の漢字を予測する
by
JubatusOfficial
Jubatus解説本の紹介
by
JubatusOfficial
銀座のママ
by
JubatusOfficial
小町の溜息
by
JubatusOfficial
JUBARHYME
by
JubatusOfficial
地域の魅力を伝えるツアーガイドAI
by
JubatusOfficial
FIT2012招待講演「異常検知技術のビジネス応用最前線」
by
Shohei Hido
Jubakit の紹介
by
kmaehashi
Jubatus 新機能ハイライト
by
JubatusOfficial
Similar to もくもくしたこと
PDF
[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...
by
Deep Learning JP
PDF
20170421 tensor flowusergroup
by
ManaMurakami1
PDF
まだCPUで消耗してるの?Jubatusによる近傍探索のGPUを利用した高速化
by
JubatusOfficial
PDF
DeepLearningDay2016Summer
by
Takayoshi Yamashita
PDF
DIGITSによるディープラーニング画像分類
by
NVIDIA Japan
PDF
SPADE :Semantic Image Synthesis with Spatially-Adaptive Normalization
by
Tenki Lee
PPTX
[DL輪読会]End-to-End Object Detection with Transformers
by
Deep Learning JP
PDF
MII conference177 nvidia
by
Tak Izaki
PDF
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
PDF
FPGAX2019
by
Hiroki Nakahara
PDF
MIRU2018 tutorial
by
Takayoshi Yamashita
PDF
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
PDF
ハンズオン セッション 1: DIGITS によるディープラーニング入門
by
NVIDIA Japan
PDF
ハンズオン1: DIGITS によるディープラーニング入門
by
NVIDIA Japan
PDF
論文紹介 "DARTS: Differentiable Architecture Search"
by
Yuta Koreeda
PDF
【関東GPGPU勉強会#4】GTX 1080でComputer Vision アルゴリズムを色々動かしてみる
by
Yasuhiro Yoshimura
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
PDF
KDD2018 paper reading
by
Kousuke Kuzuoka
PPTX
CNNチュートリアル
by
Ikuro Sato
[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...
by
Deep Learning JP
20170421 tensor flowusergroup
by
ManaMurakami1
まだCPUで消耗してるの?Jubatusによる近傍探索のGPUを利用した高速化
by
JubatusOfficial
DeepLearningDay2016Summer
by
Takayoshi Yamashita
DIGITSによるディープラーニング画像分類
by
NVIDIA Japan
SPADE :Semantic Image Synthesis with Spatially-Adaptive Normalization
by
Tenki Lee
[DL輪読会]End-to-End Object Detection with Transformers
by
Deep Learning JP
MII conference177 nvidia
by
Tak Izaki
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
FPGAX2019
by
Hiroki Nakahara
MIRU2018 tutorial
by
Takayoshi Yamashita
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
ハンズオン セッション 1: DIGITS によるディープラーニング入門
by
NVIDIA Japan
ハンズオン1: DIGITS によるディープラーニング入門
by
NVIDIA Japan
論文紹介 "DARTS: Differentiable Architecture Search"
by
Yuta Koreeda
【関東GPGPU勉強会#4】GTX 1080でComputer Vision アルゴリズムを色々動かしてみる
by
Yasuhiro Yoshimura
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
KDD2018 paper reading
by
Kousuke Kuzuoka
CNNチュートリアル
by
Ikuro Sato
もくもくしたこと
1.
もくもくしたこと おいかわ かずき (Jubatusもくもく会 #2,
2016/02/27)
2.
自己紹介 • 及川 一樹 –
GitHub: https://github.com/kazuki/ – Twitter: @k_oi • 趣味とか使ってるものとか – 音声・映像符号 – HTML5とか(WebAudio, WebRTC, asmjs…) – GPGPU (OpenCL, HSA) – 暗号 – 分散とかクラウドとか (Hadoop, P2P, OpenStack, ...) – Gentoo Linux – Python, TypeScript, Rust, C#
3.
もくもくしたもの • メイン – Nearest
Neighbor の高速化 ➔ △ • バックアップねた – Jubatus in Browser ➔ △ – Gentooパッケージの不満解消 ➔ △ • メインが完成するかわからなかったので, バックアップネタをいくつか用意したのですが,すべてが中途半端に....
4.
Jubatus NNの高速化 • Nearest
Neighbor遅いです – 20newsの分類 train: 30分, classify: 30分 ※ Haswell 3.5GHz,全件のtrain/classifyの所要時間 • 原因 – train/classify: ハッシュへの変換が遅い (random_projection) – classify: 登録済みハッシュとの距離計算が遅い
5.
速くする! • Random Projectionが遅い –
熊崎さんが2015年10月ぐらいにキャッシュする実装を作っている feature/cached_random_projection ブランチ – 及川も2015年10月 ぐらいに正規分布に従う乱数生成の高速化を実施 – 今回はこの2つを混ぜて+AVX2(SIMD)でさらなる高速化! • 距離計算が遅い – 比較対象が増えるので,沢山trainするとどんどん遅くなる – GPGPUで力技で解決する!
6.
0 10 20 30 40 50 60 70 80 90 100 train classify結果
7.
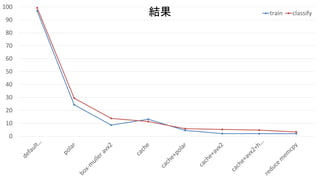
結果 手法 Train [ms]
Classify [ms] Default (box-muller) 96.8534 99.3197 [1]: Polar法で正規分布生成 24.3529 29.4501 [2]: AVX2版Box-muller 8.5948 13.7828 [3]: Cache 13.1329 11.3558 [4]: [1] + [3] 4.48 5.83724 [5]: [2]+ [3] 2.03893 5.26619 [6]: [5] + ハミング距離計算AVX2 2.01252 4.73609 [7]: [6] + メモリコピー削減 1.97709 3.28481 ※メモリコピー削減: 比較対象のBitVectorを常にコピーしていたので, コピーしないで比較するように改良.近いうちにpull-reqだしたい (結果的にモデルサイズ分のメモリコピーを1回のClassifyで実施していた)
8.
GPGPU ! • 間に合いませんでした... –
AMD Kaveri APU + OpenCL 2.0で仮想メモリ空間共有を動かすのに 数時間かかってしまった... – マニュアルに記載の無いコンパイルオプションが必要だった… • 得られた知見 – NNのストレージのメモリ空間は連続しているのでGPGPUしやすい – bit_vectorが必要量の8倍のメモリを確保している =>ストレージはbit_vectorじゃないので大した影響はなさげ (パッチはpull-req済み) • ここまでの作業内容は私のGitHubのjubatus_coreのexperimental/nnブランチで公開済
9.
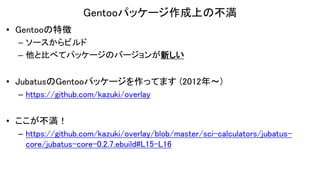
Gentooパッケージ作成上の不満 • Gentooの特徴 – ソースからビルド –
他と比べてパッケージのバージョンが新しい • JubatusのGentooパッケージを作ってます (2012年〜) – https://github.com/kazuki/overlay • ここが不満! – https://github.com/kazuki/overlay/blob/master/sci-calculators/jubatus- core/jubatus-core-0.2.7.ebuild#L15-L16
10.
Gentooパッケージ作成上の不満 • というわけで msgpack1.1.0に対応させてみました –
最新は1.4.0ですがGentooは1.1.0までしか入ってないので... – Msgpack,API互換壊しまくりなので順に確認したほうが楽そう – MsgpackのC++03向けtuple実装が残念でビルドが通らない... • C++11にすれば解決! ➔ jubatus-msgpack-rpcがC++11に対応してない...orz • 仕方がないので,msgpackのヘッダにパッチをあてて回避... – Jubatus_core: 121+, 103- – Jubatus: 12+, 11- – Jubatus-msgpack-rpc: msgpack-1.xブランチで対応済み – 中途半端... JubatusをC++11化してお掃除するのとあわせて... そのうち... • 利点 – Msgpack 1.0.0 から C++版はヘッダオンリライブラリ ➔libmsgpack.soへのリンクが消滅 • 私のGitHubのjubatus/jubatus_coreのmsgpack-1.1ブランチで公開済み
11.
Jubatus in Browser •
Msgpack 1.0からはヘッダオンリーライブラリ 依存関係が減り jubatus_core単品で動くようになる
12.
すべてがJavaScript になる https://github.com/kripken/emscripten
13.
Jubatus_coreをJavaScript化! • システムコールとかpthreadとかはJavaScriptは対応していないので,#ifdef で隠す • 出力されたJavaScriptファイル
2.3MB • とりあえずnode で Classify のサンプルは動くが, ブラウザのインタフェース作る時間がなかった... • スマフォ向けブラウザは加速度やBluetoothが利用できるので,ブラウザだけ でJubatusを使って何かできる! • 私のGitHubのjubatus_coreのemscriptenブランチで公開済
14.
GPGPUの続き… • あと少しだったのでお家に帰ってからもくもく会の続きを実施 – 動いた!
experimental/nn-gpgpu-opencl ブランチ • 性能評価 (20newsの全件Classify) – Haswell 3.5GHz AVX2: 64s (3.4ms/ops) – Haswell 3.5GHz AVX2 + dGPU: 161s (8.5ms/ops) ※CPU利用率は25%程度 – Kaveri 3.7GHz AVX: 143s (7.6ms/ops) – Kaveri 3.7GHz AVX + iGPU: 137s (7.2ms/ops)※CPU利用率は50%程度 • モデルが小さい(32MBぐらい)ので,カーネル実行レイテンシが支配的 – 大きいモデルで実験すると効果が見えるかも…? – (KaveriはCPU性能低い+iGPUでメモリ転送レイテンシが小さいため少し改善) dGPU: AMD Radeon R9 285, GCN 1.2 Tonga, 3.3TFLOPS (1792SP, 918MHz) iGPU: GCN 1.1, 737GFLOPS (512SP, 720MHz)
15.
GPGPU版の今後 • OpenCL 2.0
SharedVirtualMemory Fine-grain Bufferで実装 – 仮想メモリ空間共有 – clSVMAllocでアロケートしたメモリである必要がある 内部ストレージで利用されている std::vector 等相当の物を書き換える必要 • OpenCL 2.0 SVM Fine-grain System / HAS に切り替え – malloc等で確保したメモリ空間がそのままGPUからも見える! – AMD Kaveri,Intel Broadwell以降でHW的には対応 (SW的には不明.AMDはHSAのみ.Intelはブツを持ってないので未確認) – より簡単に統合できるし,モデルの更新も従来通り実施できる
Download






![結果
手法 Train [ms] Classify [ms]
Default (box-muller) 96.8534 99.3197
[1]: Polar法で正規分布生成 24.3529 29.4501
[2]: AVX2版Box-muller 8.5948 13.7828
[3]: Cache 13.1329 11.3558
[4]: [1] + [3] 4.48 5.83724
[5]: [2]+ [3] 2.03893 5.26619
[6]: [5] + ハミング距離計算AVX2 2.01252 4.73609
[7]: [6] + メモリコピー削減 1.97709 3.28481
※メモリコピー削減: 比較対象のBitVectorを常にコピーしていたので,
コピーしないで比較するように改良.近いうちにpull-reqだしたい
(結果的にモデルサイズ分のメモリコピーを1回のClassifyで実施していた)](https://image.slidesharecdn.com/jubatus-160228085445/85/slide-7-320.jpg)









































![[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...](https://cdn.slidesharecdn.com/ss_thumbnails/20180907pervasiveattention2dconvolutionalneuralnetworksforsequence-to-sequenceprediction-180907000649-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)












