Download to read offline


































![Three prominent methods:
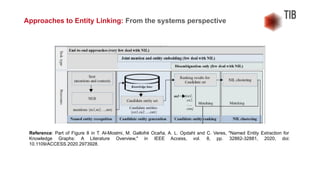
● a surface form matching
○ a candidate list is composed of entities, which simply match surface forms of mentions in the
text; does not work well if referent entity does not contain mention string
● a dictionary lookup
○ a dictionary of additional aliases is constructed using KB metadata like
disambiguation/redirect pages of Wikipedia or lexical synonymy relations
● and a prior probability computation
○ the candidates are generated based on precalculated prior probabilities of correspondence
between certain mentions and entities; based on mention-entity hyperlink count statistics
[1,2,3,4,5,etc.]
○
References
1. Stefan Zwicklbauer, Christin Seifert, and Michael Granitzer. 2016. Robust and collective entity disambiguation through semantic embeddings. In Proceedings of
the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’16, pages 425–434, New York, NY, USA. ACM.
2. Chen-Tse Tsai and Dan Roth. 2016. Cross-lingual Wikification using multilingual embeddings. In Proceedings of the 2016 Conference of the North American
Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 589–598, San Diego, California, USA. ACL.
3. Octavian-Eugen Ganea and Thomas Hofmann. 2017. Deep joint entity disambiguation with local neural attention. In Proceedings of the 2017 Conference on
Empirical Methods in Natural Language Processing, pages 2619–2629, Copenhagen, Denmark. ACL.
4. Nikolaos Kolitsas, Octavian-Eugen Ganea, and Thomas Hofmann. 2018. End-to-end neural entity linking. In Proceedings of the 22nd Conference on
Computational Natural Language Learning, pages 519–529, Brussels, Belgium. Association for Computational Linguistics.
5. Avirup Sil, Gourab Kundu, Radu Florian, and Wael Hamza. 2018. Neural cross-lingual entity linking. In The 32 AAAI, New Orleans, Louisiana, USA. AAAI Press.
Candidate Generation](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-37-320.jpg)




![Two approaches prevail:
● recurrent networks with LSTM cells
○ concatenating outputs of two LSTM networks that independently encode left and right
contexts of a mention (including the mention itself) [1];
○ encode left and right local contexts via LSTMs but also pool the results across all mentions in
a coreference chain and postprocess left and right representations with a tensor network [2];
○ modification of LSTM–GRU in conjunction with an attention mechanism to encode left and
right context of a mention [3];
○ run a bidirectional LSTM network on words complemented with embeddings of word positions
relative to a target mention [4]
References
1 Nitish Gupta, Sameer Singh, and Dan Roth. 2017. Entity linking via joint encoding of types, descriptions, and context. In 2017 EMNLP, pages 2681–2690,
Copenhagen, Denmark. ACL.
2 Avirup Sil, Gourab Kundu, Radu Florian, and Wael Hamza. 2018. Neural cross-lingual entity linking. In The 32 AAAI, New Orleans, Louisiana, USA. AAAI Press.
3. Yotam Eshel, Noam Cohen, Kira Radinsky, Shaul Markovitch, Ikuya Yamada, and Omer Levy. 2017. Named entity disambiguation for noisy text. In CoNLL 2017,
pages 58–68, Vancouver, Canada. ACL.
4. Phong Le and Ivan Titov. 2019b. Distant learning for entity linking with automatic noise detection. In Proceedings of the 57th Annual Meeting of the Association for
Computational Linguistics, pages 4081–4090, Florence, Italy, July. ACL.
Mention Encoding Subcomponent](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-43-320.jpg)

![Two approaches prevail:
● recurrent networks with LSTM cells
● self-attention: encoding methods based on self-attention rely on the outputs from pre-trained
BERT layers for context and mention encoding.
○ a mention representation is modeled by pooling over word pieces in a mention span. The
authors also put an additional self-attention block over all mention representations that
encode interactions between several entities in a sentence [1].
○ reduce a sequence by keeping the representation of the special pooling symbol ‘[CLS]’
inserted at the beginning of a sequence [2].
○ mark positions of a mention span by summing embeddings of words within the span with a
special vector [3] and use the same reduction strategy as [2].
○ concatenate text with all mentions in it and jointly encode this sequence via a self-attention
model based on pre-trained BERT [4].
References
1 Matthew E. Peters, Mark Neumann, Robert Logan, Roy Schwartz, Vidur Joshi, Sameer Singh, and Noah A. Smith. 2019. Knowledge enhanced contextual word
representations. In Proceedings of the 2019 EMNLP-IJCNLP, pages 43–54, Hong Kong, China. ACL.
2 Ledell Yu Wu, Fabio Petroni, Martin Josifoski, Sebastian Riedel, and Luke Zettlemoyer. 2020. Zero-shot entity linking with dense entity retrieval. ArXiv,
abs/1911.03814.
3 Lajanugen Logeswaran, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, Jacob Devlin, and Honglak Lee. 2019. Zero-shot entity linking by reading entity
descriptions. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3449–3460, Florence, Italy. ACL.
4 Ikuya Yamada, Koki Washio, Hiroyuki Shindo, and Yuji Matsumoto. 2020. Global entity disambiguation with pretrained contextualized embeddings of words and
entities. arXiv preprint arXiv:1909.00426v2.
Mention Encoding Subcomponent](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-45-320.jpg)


![Aim to obtain vector representations for entities:
● capture different kinds of entity information, including entity type, description page, linked mention,
and contextual information, and therefore, generate a large encoder, which involves CNN for the
entity description and alignment function for the others [1].
● encode entities based on their title, description page, and category information. All previously
mentioned models rely on the annotated data, and a few studies are challenged with less
resource dependence [2].
● derive entity embeddings using pre-trained word2vec word vectors through description page
words, surface forms words, and entity category words [3,4].
● depend on the BERT architecture to create representations through the description pages [5,6].
References
1 Nitish Gupta, Sameer Singh, and Dan Roth. 2017. Entity linking via joint encoding of types, descriptions, and context. In Proceedings of the 2017 EMNLP, pages
2681–2690, Copenhagen, Denmark. ACL.
2 Daniel Gillick, Sayali Kulkarni, Larry Lansing, Alessandro Presta, Jason Baldridge, Eugene Ie, and Diego Garcia-Olano. 2019. Learning dense representations for
entity retrieval. In Proceedings of the 23rd CoNLL, pages 528–537, Hong Kong, China. ACL.
3 Yaming Sun, Lei Lin, Duyu Tang, Nan Yang, Zhenzhou Ji, and XiaolongWang. 2015. Modeling mention, context and entity with neural networks for entity
disambiguation. In Proceedings of the 24th, IJCAI’15, pages 1333–1339. AAAI Press.
4 Avirup Sil, Gourab Kundu, Radu Florian, and Wael Hamza. 2018. Neural cross-lingual entity linking. In 32 AAAI, New Orleans, Louisiana, USA. AAAI Press.
5 Lajanugen Logeswaran, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, Jacob Devlin, and Honglak Lee. 2019. Zero-shot entity linking by reading entity
descriptions. In Proceedings of the 57th ACL, pages 3449–3460, Florence, Italy. ACL.
6 Ledell Yu Wu, Fabio Petroni, Martin Josifoski, Sebastian Riedel, and Luke Zettlemoyer. 2020. Zero-shot entity linking with dense entity retrieval. ArXiv,
abs/1911.03814.
Entity Encoding Subcomponent](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-48-320.jpg)

![● Most of the state-of-the-art studies compare mention and entity representations using a dot product [1,2,3,4] or
cosine similarity [5,6,7].
● The calculated similarity score is often combined with mention-entity priors obtained during the candidate
generation phase [1,3,6] or other features including various similarities, string matching indicator, and entity types
[6,8,9,10].
● Commonly an additional one or two-layer feedforward network [1,6,9] is used. The final disambiguation decision is
inferred via a probability distribution, usually by a softmax function over the candidates. The local similarity score
or a probability distribution can be further utilized for global scoring.
References
1 Octavian-Eugen Ganea and Thomas Hofmann. 2017. Deep joint entity disambiguation with local neural attention. In Proceedings of the 2017 Conference on Empirical
Methods in Natural Language Processing, pages 2619–2629, Copenhagen, Denmark. ACL.
2 Nitish Gupta, Sameer Singh, and Dan Roth. 2017. Entity linking via joint encoding of types, descriptions, and context. In Proceedings of the 2017 EMNLP, pages
2681–2690, Copenhagen, Denmark. ACL.
3 Nikolaos Kolitsas, Octavian-Eugen Ganea, and Thomas Hofmann. 2018. End-to-end neural entity linking. In 22nd CoNLL, pages 519–529, Brussels, Belgium. ACL.
4 Matthew E. Peters, Mark Neumann, Robert Logan, Roy Schwartz, Vidur Joshi, Sameer Singh, and Noah A. Smith. 2019. Knowledge enhanced contextual word
representations. In Proceedings of the 2019 EMNLP-IJCNLP, pages 43–54, Hong Kong, China. ACL.
5 Yaming Sun, Lei Lin, Duyu Tang, Nan Yang, Zhenzhou Ji, and XiaolongWang. 2015. Modeling mention, context and entity with neural networks for entity disambiguation. In
Proceedings of the 24th International Conference on Artificial Intelligence, IJCAI’15, pages 1333–1339. AAAI Press.
6 Matthew Francis-Landau, Greg Durrett, and Dan Klein. 2016. Capturing semantic similarity for entity linking with convolutional neural networks. In Proceedings of the 2016
NAACL: Human Language Technologies, pages 1256–1261, San Diego, California, USA.
7 Daniel Gillick, Sayali Kulkarni, Larry Lansing, Alessandro Presta, Jason Baldridge, Eugene Ie, and Diego Garcia-Olano. 2019. Learning dense representations for entity
retrieval. In Proceedings of the 23rd CoNLL, pages 528–537, Hong Kong, China. ACL.
8 Avirup Sil, Gourab Kundu, Radu Florian, and Wael Hamza. 2018. Neural cross-lingual entity linking. In 32 AAAI, New Orleans, Louisiana, USA. AAAI Press.
9 Hamed Shahbazi, Xiaoli Z Fern, Reza Ghaeini, Rasha Obeidat, and Prasad Tadepalli. 2019. Entity-aware elmo:Learning contextual entity representation for entity
disambiguation. arXiv preprint arXiv:1908.05762.
Comparing Mention and Candidate Entity Representations](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-50-320.jpg)

![● Optionally addressed in some systems
● Aim to equip EL systems to recognize cases when referent entities of some mentions can be
absent in the KBs. This is known as NIL prediction.
● Four common ways to perform NIL prediction.
○ a candidate generator does not yield any corresponding entities for a mention by setting a
threshold for linking probability [1,2]
○ introduce an additional special ‘NIL’ entity in the ranking phase, so some models predict it as
the best match for the mention [3]
○ train an additional binary classifier that accepts mention-entity pairs after the ranking phase,
as well as several additional features (best linking score, whether mentions are also detected
by a dedicated NER system, etc.), and makes the final decision about whether a mention is
linkable or not [4,5].
References
1 Matthew E. Peters, Mark Neumann, Robert Logan, Roy Schwartz, Vidur Joshi, Sameer Singh, and Noah A. Smith. 2019. Knowledge enhanced contextual word
representations. In Proceedings of the 2019 EMNLP-IJCNLP, pages 43–54, Hong Kong, China. Association for Computational Linguistics.
2 Nevena Lazic, Amarnag Subramanya, Michael Ringgaard, and Fernando Pereira. 2015. Plato: A selective context model for entity resolution. TACL, 3:503–515.
3 Nikolaos Kolitsas, Octavian-Eugen Ganea, and Thomas Hofmann. 2018. End-to-end neural entity linking. In 22nd CoNLL, pages 519–529, Brussels, Belgium. ACL.
4 Jose G. Moreno, Romaric Besanc¸on, Romain Beaumont, Eva D’hondt, Anne-Laure Ligozat, Sophie Rosset, Xavier Tannier, and Brigitte Grau. 2017. Combining word
and entity embeddings for entity linking. In Extended Semantic Web Conference (1), volume 10249 of Lecture Notes in Computer Science, pages 337–352.
5 Pedro Henrique Martins, Zita Marinho, and Andr´e F. T. Martins. 2019. Joint learning of named entity recognition and entity linking. In Proceedings of the 57th Annual
Meeting of the Association for Computational Linguistics: Student Research Workshop, pages 190–196, Florence, Italy. Association for Computational Linguistics.
Unlinkable Mention Prediction](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-52-320.jpg)

![Modifications of the General Architecture:
● Joint Entity Recognition and Disambiguation Architectures
○ Observe that interaction between recognition and disambiguation is beneficial to improve overall
model
■ E.g., multi-task learning framework that integrates recognition and linking [1]
● Global Context Architectures
○ global EL seen as sequential decision task where disambiguation of new entities is based on the
already disambiguated ones
■ E.g., apply LSTM to be able to maintain long term memory for previous decisions [2]
● Cross-lingual Architectures
○ leverage supervision signals from multiple languages for training a model in a target language
■ E.g., the inter-lingual links in Wikipedia utilized for alignment of entities in multiple languages. With
this alignment, the annotated data from high-resource languages like English can help to improve
the quality of text processing for the low-resource ones [3]
References
1 Pedro Henrique Martins, Zita Marinho, and Andr´e F. T. Martins. 2019. Joint learning of named entity recognition and entity linking. In 57th ACL: Student Research
Workshop, pages 190–196, Florence, Italy. ACL.
2 Zheng Fang, Yanan Cao, Qian Li, Dongjie Zhang, Zhenyu Zhang, and Yanbing Liu. 2019. Joint entity linking with deep reinforcement learning. In The World Wide
Web Conference, WWW ’19, pages 438–447, New York, NY, USA. ACM.
3 Heng Ji, Joel Nothman, Ben Hachey, and Radu Florian. 2015. Overview of TAC-KBP2015 tri-lingual entity discovery and linking. In Proceedings of the 2015 Text
Analysis Conference, TAC 2015, pages 16–17, Gaithersburg, Maryland, USA. NIST.
(Neural) Approaches to Entity Linking: General Architecture
Modifications](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-54-320.jpg)








![● Also involves completing an existing knowledge graph,
and other entity-oriented acquisition tasks such as entity
resolution and alignment.
● Thus, the main tasks of knowledge acquisition include
relation extraction to convert unstructured text to
structured knowledge, knowledge graph completion
(KGC), and other entity-oriented acquisition tasks such as
entity recognition and entity alignment.
○ KGC and relation extraction can be treated jointly. Han et
al. [1] proposed a joint learning framework with mutual
attention for data fusion between knowledge graphs and
text, which solves both KGC and relation extraction from
text.
References
1 X. Han, Z. Liu, and M. Sun, “Neural knowledge acquisition via mutual attention between knowledge
graph and text,” in AAAI, 2018, pp. 4832–4839.
Knowledge Acquisition](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-64-320.jpg)








![1. Embedding-based (ranking) methods
○ For the link prediction KGC task, i.e. for the KGC task with triples (h, r, t) with h or t missing:
■ learn embedding vectors based on existing triples:
● during test, the missing h or t entity is predicted from the existing set E of entities in the KG;
● during training, triple instances are created by replacing h or t with each entity in E, scores are
calculated of all candidate entities, and the top k entities are ranked.
■ all Knowledge Graph Embedding methods that represent inputs and candidates in a unified
embedding space are applicable. E.g., TransE [1], TransH [2], TransR [3], HolE [4].
References
1 A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” in NIPS, 2013, pp. 2787–2795.
2 Z. Wang, J. Zhang, J. Feng, and Z. Chen, “Knowledge graph embedding by translating on hyperplanes,” in AAAI, 2014, pp. 1112–1119.
3 Y. Lin, Z. Liu, M. Sun, Y. Liu, and X. Zhu, “Learning entity and relation embeddings for knowledge graph completion,” in AAAI, 2015, pp. 2181–2187.
4 M. Nickel, L. Rosasco, and T. Poggio, “Holographic embeddings of knowledge graphs,” in AAAI, 2016, pp. 1955–1961.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-73-320.jpg)
![1. Embedding-based (ranking) methods
○ For the link prediction KGC task, i.e. for the KGC task with triples (h, r, t) with h or t missing:
■ TransE model [Bordes et al., 2013]
References
1 A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” in NIPS, 2013, pp. 2787–2795.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-74-320.jpg)
![1. Embedding-based (ranking) methods
○ For the link prediction KGC task, i.e. for the KGC task with triples (h, r, t) with h or t missing:
■ learn embedding vectors based on existing triples:
● during test, the missing h or t entity is predicted from the existing set E of entities in the KG;
● during training, triple instances are created by replacing h or t with each entity in E, scores are
calculated of all candidate entities, and the top k entities are ranked.
■ Unlike representing inputs and candidates in a unified embedding space, ProjE [1] proposes a
combined embedding by space projection of the known parts of input triples, i.e., (h; r; ?) or (?;
r; t), and the candidate entities with the candidate-entity matrix Wc belongs to Rsxd, where s
is the number of candidate entities. Their embedding projection function includes a neural
combination layer and a output projection layer.
References
1 Shi and T. Weninger, “ProjE: Embedding projection for knowledge graph completion,” in AAAI, 2017, pp. 1236–1242.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-75-320.jpg)
![1. Embedding-based (ranking) methods
○ For the link prediction KGC task, i.e. for the KGC task with triples (h, r, t) with h or t missing:
■ learn embedding vectors based on existing triples:
● during test, the missing h or t entity is predicted from the existing set E of entities in the KG;
● during training, triple instances are created by replacing h or t with each entity in E, scores are
calculated of all candidate entities, and the top k entities are ranked.
■ ConMask [1] proposes relationship-dependent content masking over the entity description to
select relevant snippets of given relations, and CNN-based target fusion to complete the
knowledge graph. It can only make a prediction when query relations and entities are explicitly
expressed in the text description.
References
1 B. Shi and T. Weninger, “Open-world knowledge graph completion,” in AAAI, 2018, pp. 1957–1964.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-76-320.jpg)

![2. Relation path reasoning
○ A limitation of the embedding based method is that they do not model complex relation paths.
■ Relation path reasoning leverages path information over the graph structure.
○ Random walk inference has been investigated.
■ E.g., the Path-Ranking Algorithm (PRA) [1] chooses a relational path under a combination of
path constraints and conducts maximum-likelihood classification.
○ Neural multi-hop relational path modeling is also studied.
■ Neelakantan et al. [2] models complex relation paths by applying compositionality recursively
over the relations in the path as depicted in the figure below.
References
1 N. Lao and W. W. Cohen, “Relational retrieval using a combination of path-constrained random walks,” Machine learning, vol. 81, no. 1, pp. 53–67, 2010.
2 A. Neelakantan, B. Roth, and A. McCallum, “Compositional vector space models for knowledge base completion,” in ACL-IJCNLP, vol. 1, 2015, pp. 156–166.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-78-320.jpg)
![2. Relation path reasoning
○ Chains-of-Reasoning [1], a neural attention mechanism to enable multiple reasons,
represents logical composition across all relations, entities, and text.
○ DIVA [2] proposes a unified variational inference framework that takes multi-hop reasoning as
two sub-steps of path-finding (a prior distribution for underlying path inference) and
path-reasoning (a likelihood for link classification).
References
1 R. Das, A. Neelakantan, D. Belanger, and A. McCallum, “Chains of reasoning over entities, relations, and text using recurrent neural networks,” in EACL, vol. 1, 2017,
pp. 132–141.
2 W. Chen, W. Xiong, X. Yan, and W. Y. Wang, “Variational knowledge graph reasoning,” in NAACL, 2018, pp. 1823–1832.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-79-320.jpg)
![2. Reinforcement-learning based path finding
○ Deep reinforcement learning (RL) is introduced for multi-hop reasoning by formulating
path-finding between entity pairs as sequential decision making, specifically a Markov
decision process (MDP). The policy-based RL agent learns to find a step of relation to
extending the reasoning paths via the interaction between the knowledge graph environment,
where the policy gradient is utilized for training RL agents.
■ KGC based on RL concepts of State, Action, Reward, and Policy Network
○ DeepPath [1] firstly applies RL into relational path learning and develops a novel reward
function to improve accuracy, path diversity, and path efficiency. It encodes states in the
continuous space via a translational embedding method and takes the relation space as its
action space.
○ Similarly, MINERVA [2] takes path walking to the correct answer entity as a sequential
optimization problem by maximizing the expected reward. It excludes the target answer entity
and provides more capable inference.
References
1 W. Xiong, T. Hoang, and W. Y. Wang, “DeepPath: A reinforcement learning method for knowledge graph reasoning,” in EMNLP, 2017, pp. 564–573.
2 R. Das, S. Dhuliawala, M. Zaheer, L. Vilnis, I. Durugkar, A. Krishnamurthy, A. Smola, and A. McCallum, “Go for a walk and arrive at the answer: Reasoning over paths
in knowledge bases using reinforcement learning,” in ICLR, 2018, pp. 1–18.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-80-320.jpg)
![2. Reinforcement-learning based path finding
○ Instead of using a binary reward function, MultiHop [1] proposes a soft reward mechanism.
Action dropout is also adopted to mask some outgoing edges during training to enable more
effective path exploration.
○ M-Walk [2] applies an RNN controller to capture the historical trajectory and uses the Monte
Carlo Tree Search (MCTS) for effective path generation.
○ Leveraging text corpus with the sentence bag of current entity denoted as bet , CPL [3]
proposes collaborative policy learning for pathfinding and fact extraction from text.
○ For the policy networks, DeepPath uses fully-connected network, the extractor of CPL
employs CNN, while the rest uses recurrent networks.
References
1 X. V. Lin, R. Socher, and C. Xiong, “Multi-hop knowledge graph reasoning with reward shaping,” in EMNLP, 2018, pp. 3243–3253.
2 Y. Shen, J. Chen, P.-S. Huang, Y. Guo, and J. Gao, “M-Walk: Learning to walk over graphs using monte carlo tree search,” in NeurIPS, 2018, pp. 6786–6797.
3 C. Fu, T. Chen, M. Qu, W. Jin, and X. Ren, “Collaborative policy learning for open knowledge graph reasoning,” in EMNLP, 2019, pp. 2672–2681.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-81-320.jpg)
![3. Rule-based Reasoning
○ Another direction for Knowledge Graph Completion
■ making use of the symbolic nature of knowledge is logical rule learning
○ E.g., the inference rule: (Y; sonOf; X) <-- (X; hasChild; Y) ^ (Y; gender; Male), where the
relation ‘sonOf’ did not exist earlier.
■ Logical rules can been extracted by rule mining tools like AMIE [1]
○ RLvLR [2] proposes a scalable rule mining approach with efficient rule searching and
pruning, and uses the extracted rules for relation prediction.
References
1 L. A. Gal´arraga, C. Teflioudi, K. Hose, and F. Suchanek, “AMIE: association rule mining under incomplete evidence in ontological knowledge bases,” in WWW, 2013,
pp. 413–422.
2 P. G. Omran, K. Wang, and Z. Wang, “An embedding-based approach to rule learning in knowledge graphs,” IEEE TKDE, pp. 1–12, 2019.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-82-320.jpg)
![3. Rule-based Reasoning
○ In a different research direction on this topic, research is focused on injecting logical rules
into embeddings to improve reasoning, with joint learning, as an example, applied to
incorporate first-order logic rules.
■ E.g., KALE [1] proposes a unified joint model with t-norm fuzzy logical connectives defined for
compatible triples and logical rules embedding.
■ Specifically, three compositions of logical conjunction, disjunction, and negation are defined to
compose the truth value of a complex formula.
References
1 S. Guo, Q. Wang, L. Wang, B. Wang, and L. Guo, “Jointly embedding knowledge graphs and logical rules,” in EMNLP, 2016, pp. 192–202.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-83-320.jpg)
![4. Meta Relational Learning
○ Consider that the real-world scenario of knowledge is, in fact, dynamic where unseen triples
are usually acquired.
○ The new scenario is called as meta relational learning or few-shot relational learning
■ requires models to predict new relational facts with only very few samples
○ GMatching [1] develops a metric based few-shot learning method with entity embeddings and
local graph structures.
■ It encodes one-hop neighbors to capture the structural information with R-GCN and then takes
the structural entity embedding for multistep matching guided by long short-term memory
(LSTM) networks to calculate the similarity scores.
References
1 W. Xiong, M. Yu, S. Chang, X. Guo, and W. Y. Wang, “One-shot relational learning for knowledge graphs,” in EMNLP, 2018, pp. 1980–1990.
Approaches to Knowledge Graph Completion](https://image.slidesharecdn.com/perspectivesonminingknowledgegraphsfromtext-220221102735/85/Perspectives-on-mining-knowledge-graphs-from-text-84-320.jpg)

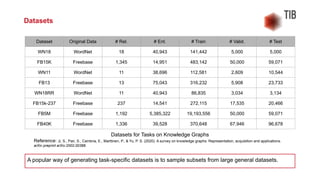
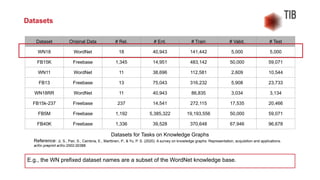















The document presents a talk by Jennifer D'Souza on mining knowledge graphs from text, emphasizing the challenges and methodologies involved in entity linking, which includes handling entity ambiguity and name variations. It covers datasets and knowledge bases relevant for entity linking, particularly open-domain settings, and highlights neural and non-neural approaches developed since 2015. Additionally, it introduces a novel multidisciplinary corpus of scholarly abstracts that link scientific entities across various STEM disciplines.





























































