Downloaded 36 times







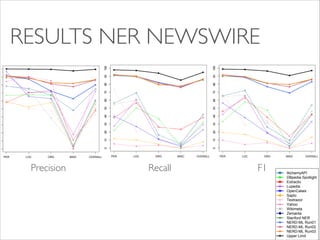
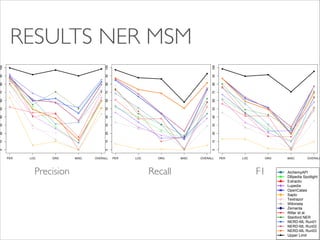
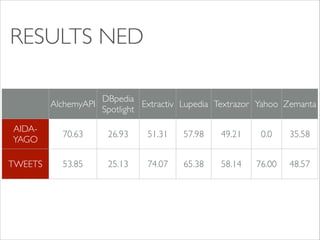




The document evaluates named entity recognition (NER) and disambiguation (NED) tools using news and tweets, comparing the performance of ten out-of-the-box tools via the NERD API and NERD-ML. It discusses the challenges of achieving high precision and recall rates, particularly for the 'misc' class, and notes the necessity of larger datasets. The results indicate progress in NER performance, while highlighting ongoing challenges in NED tasks and data standardization.