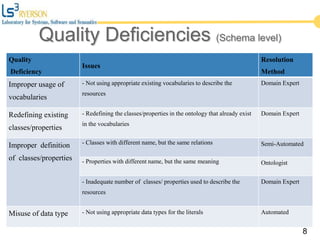
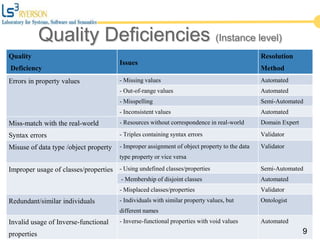
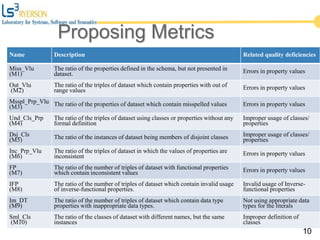
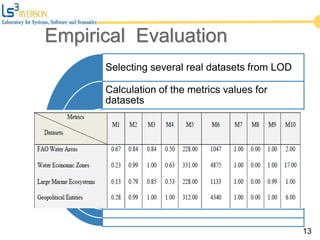
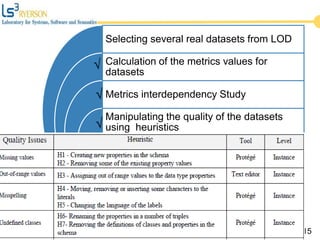
The document discusses the quality issues associated with Linked Open Data (LOD) and proposes a set of metrics to evaluate data quality prior to publication. It highlights the need for proper data quality assessment to prevent common deficiencies, such as improper usage of vocabularies and data types. The empirical evaluation demonstrates the effectiveness of these metrics in identifying quality problems across various datasets.























































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)













