Download to read offline



![Articles and Meetups
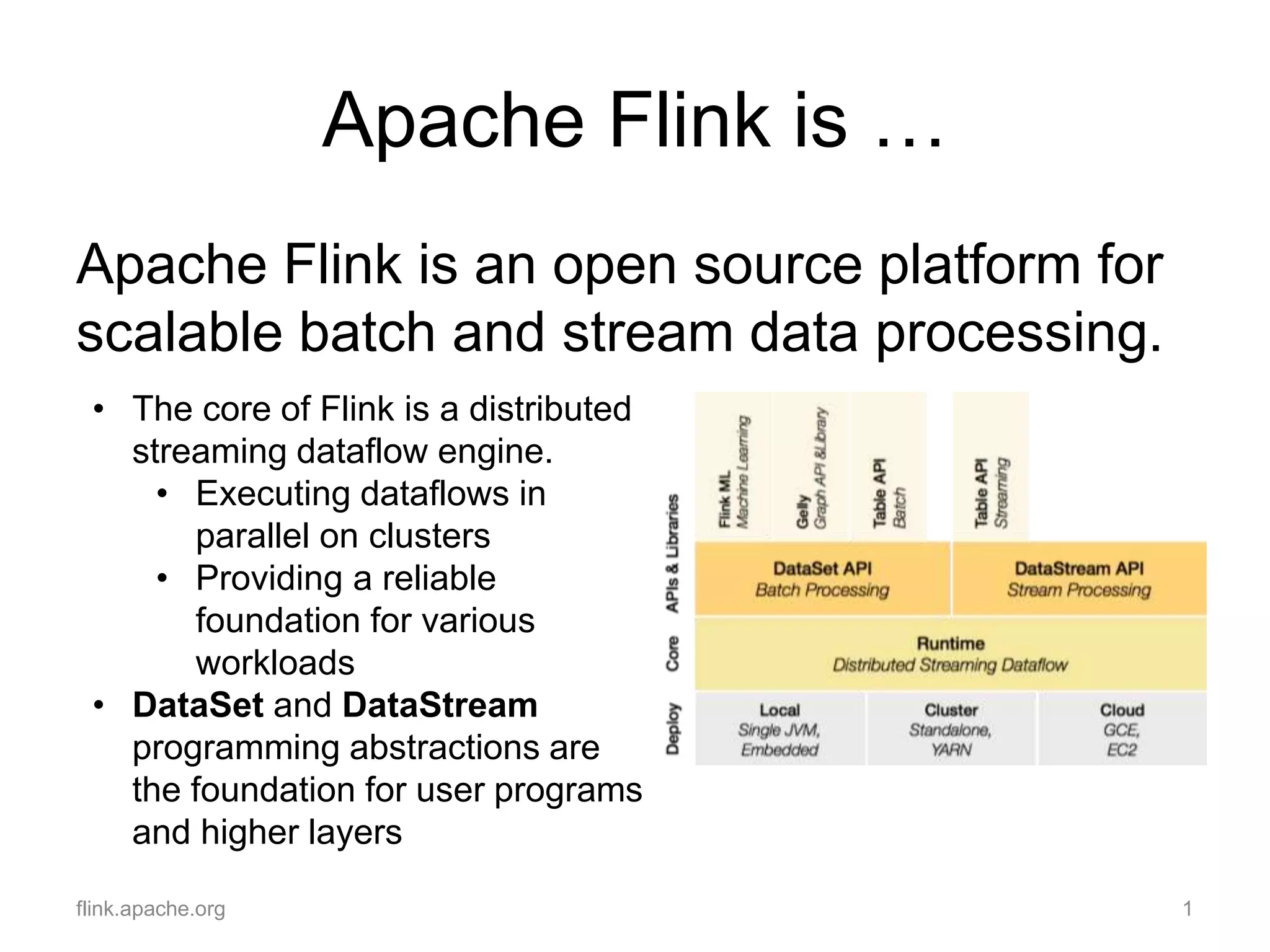
• High-throughput, low-latency, and exactly-once stream
processing with Apache Flink [1]
• Introducing Gelly: Graph Processing with Apache Flink [2]
• Apache Flink and the case for stream processing [3]
• Crunching Parquet Files with Apache Flink [4]
• The morning paper: Asynchronous Distributed Snapshots for
Distributed Dataflows [5]
• Five open source Big Data projects to watch [6]
• Big Data Performance Engineering: Examples from Hadoop,
Pig, HBase, Flink and Spark [7]
5
[1] http://data-artisans.com/high-throughput-low-latency-and-exactly-once-stream-processing-with-apache-flink/
[2] http://flink.apache.org/news/2015/08/24/introducing-flink-gelly.html
[3] http://www.kdnuggets.com/2015/08/apache-flink-stream-processing.html
[4] https://medium.com/@istanbul_techie/crunching-parquet-files-with-apache-flink-200bec90d8a7
[5] http://blog.acolyer.org/2015/08/19/asynchronous-distributed-snapshots-for-distributed-dataflows/
[6] http://www.zdnet.com/article/five-open-source-big-data-projects-to-watch/
[7] http://www.bigsynapse.com/addressing-big-data-performance](https://image.slidesharecdn.com/flinkcommunityupdate-150827084219-lva1-app6892/75/August-Flink-Community-Update-6-2048.jpg)
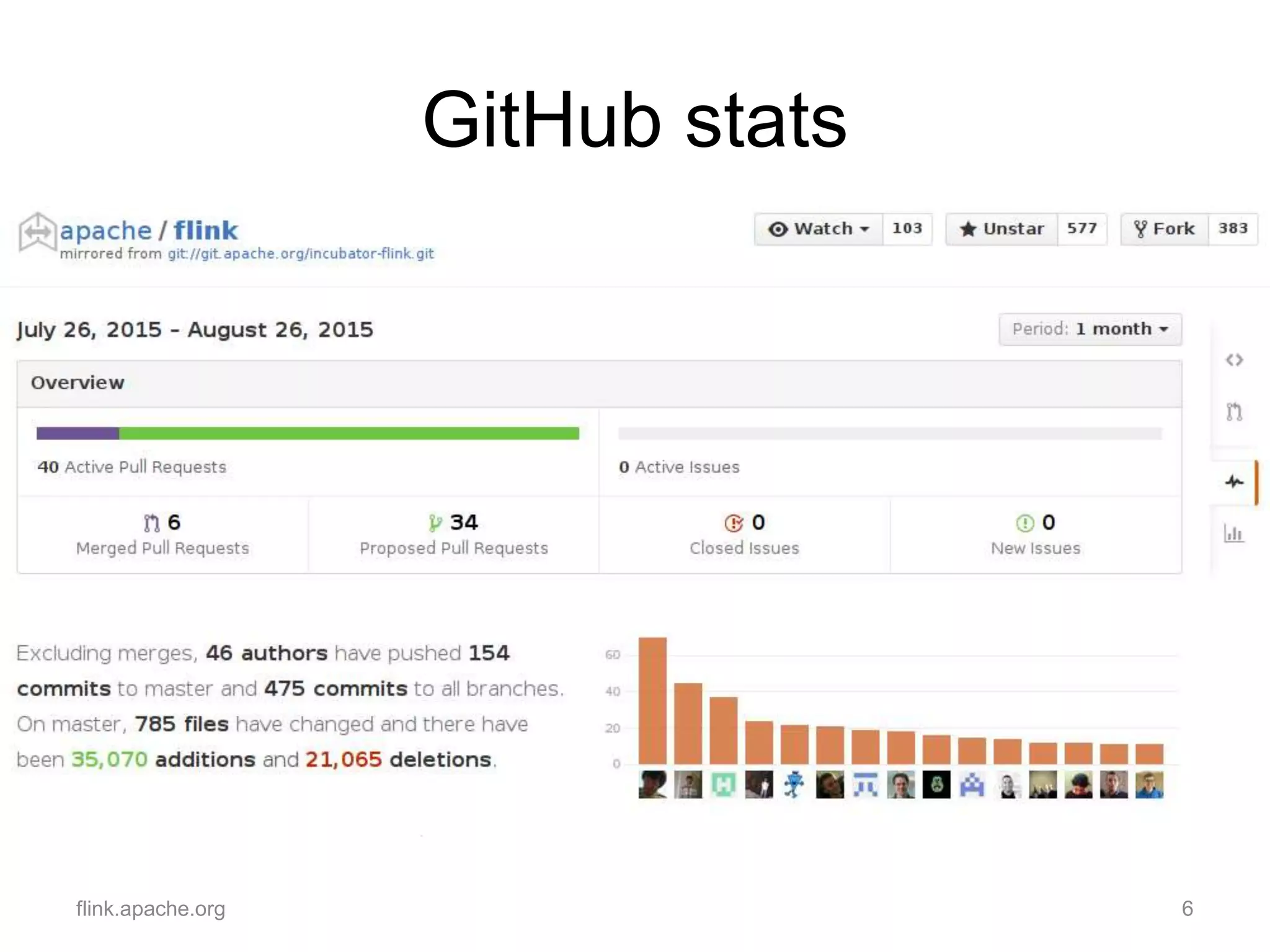



This document summarizes updates from the August 2015 Berlin Apache Flink Meetup. It discusses that Apache Flink now has a new committer, discussions have started for the 0.9.1 release, and Flink is gaining popularity with over 1000 Twitter followers and 500 GitHub stars. It also provides information on improvements now in the master version including the Gelly Scala API and a streaming connector for Elastic Search. Upcoming events are noted including Flink meetups in Washington DC, Belgium, and the Flink Talks schedule being announced for ApacheCon in Budapest.



















































































