Download as PDF, PPTX











![Creating RDD
# Creates a list of animal.
animals = ['cat', 'dog', 'elephant', 'cat', 'mouse', ’cat’]
# Parallelize method is used to create RDD from list. Here “animalRDD” is created.
#sc is Object of Spark Context.
animalRDD = sc.parallelize(animals)
# Since RDD is lazily evaluated, to print it we perform an action operation, i.e.
collect() which is used to print the RDD.
print animalRDD.collect()
Output - ['cat', 'dog', 'elephant', 'cat', 'mouse', 'cat']](https://image.slidesharecdn.com/apachesparkppt-170105054406/75/NaukriEngineering-Apache-Spark-16-2048.jpg)

![Map operation on RDD
‘’’’’ To count the frequency of animals, we make (key/value) pair - (animal,1) for all
the animals and then perform reduce operation which counts all the values.
Lambda is used to write inline functions in python.
‘’’’’
mapRDD = animalRDD.map(lambda x:(x,1))
print mapRDD.collect()
Output - [('cat',1), ('dog',1), ('elephant',1), ('cat',1), ('mouse',1), ('cat',1)]](https://image.slidesharecdn.com/apachesparkppt-170105054406/75/NaukriEngineering-Apache-Spark-18-2048.jpg)
![Reduce operation on RDD
‘’’’’ reduceByKey is used to perform reduce operation on same key. So in its
arguments, we have defined a function to add the values for same key. Hence, we
get the count of animals.
‘’’’’
reduceRDD = mapRDD.reduceByKey(lambda x,y:x+y)
print reduceRDD.collect()
Output - [('cat',3), ('dog',1), ('elephant',1), ('mouse',1)]](https://image.slidesharecdn.com/apachesparkppt-170105054406/75/NaukriEngineering-Apache-Spark-19-2048.jpg)
![Filter operation on RDD
‘’’’’ Filter all the animals obtained from reducedRDD with count greater than 2. x is
a tuple made of (animal, count), i.e. x[0]=animal name and x[1]=count of animal.
Therefore we filter the reduceRDD based on x[1]>2.
‘’’’’
filterRDD = reduceRDD.filter(lambda x:x[1]>2)
print filterRDD.collect()
Output - [('cat',3)]](https://image.slidesharecdn.com/apachesparkppt-170105054406/75/NaukriEngineering-Apache-Spark-20-2048.jpg)










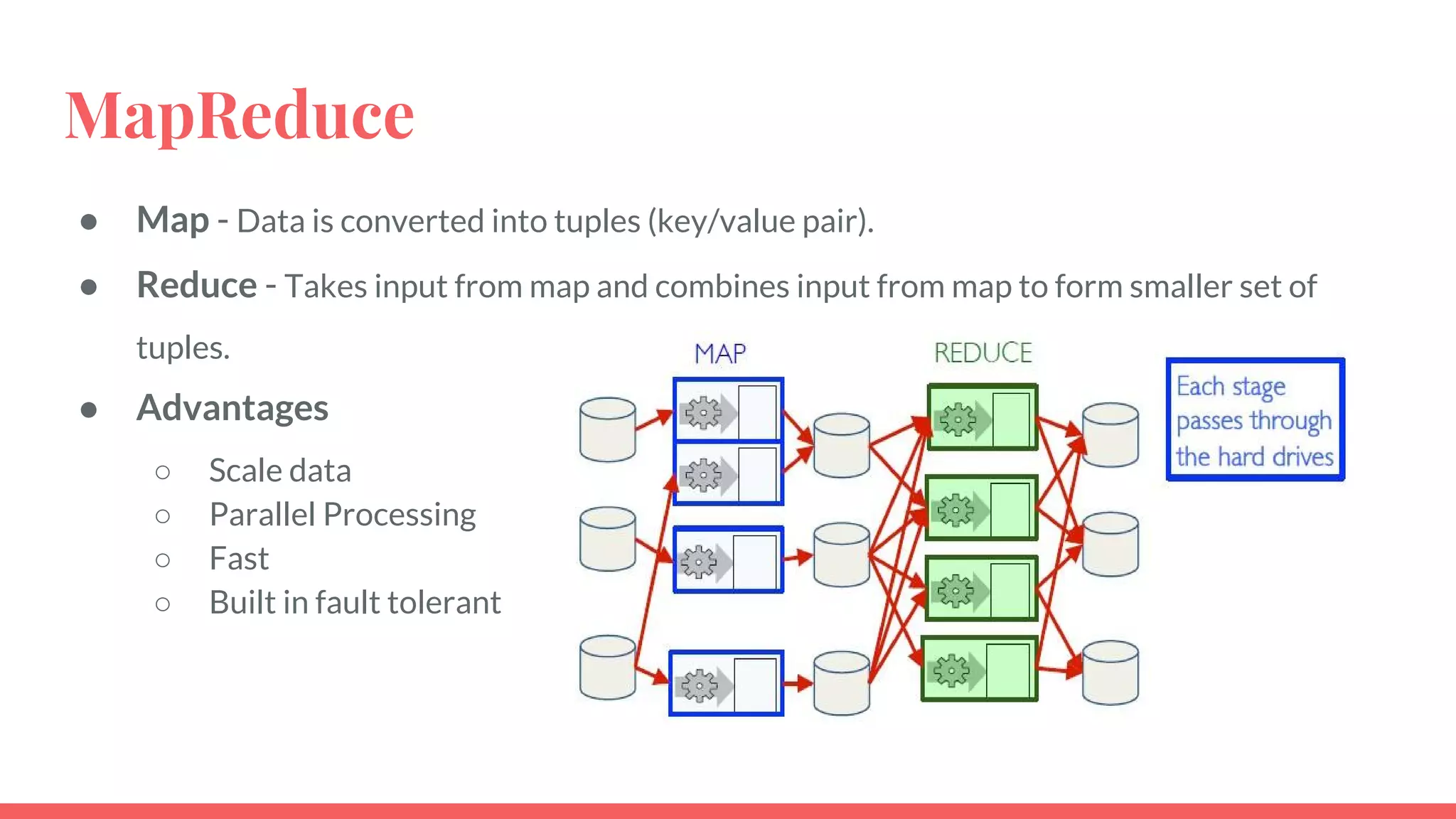
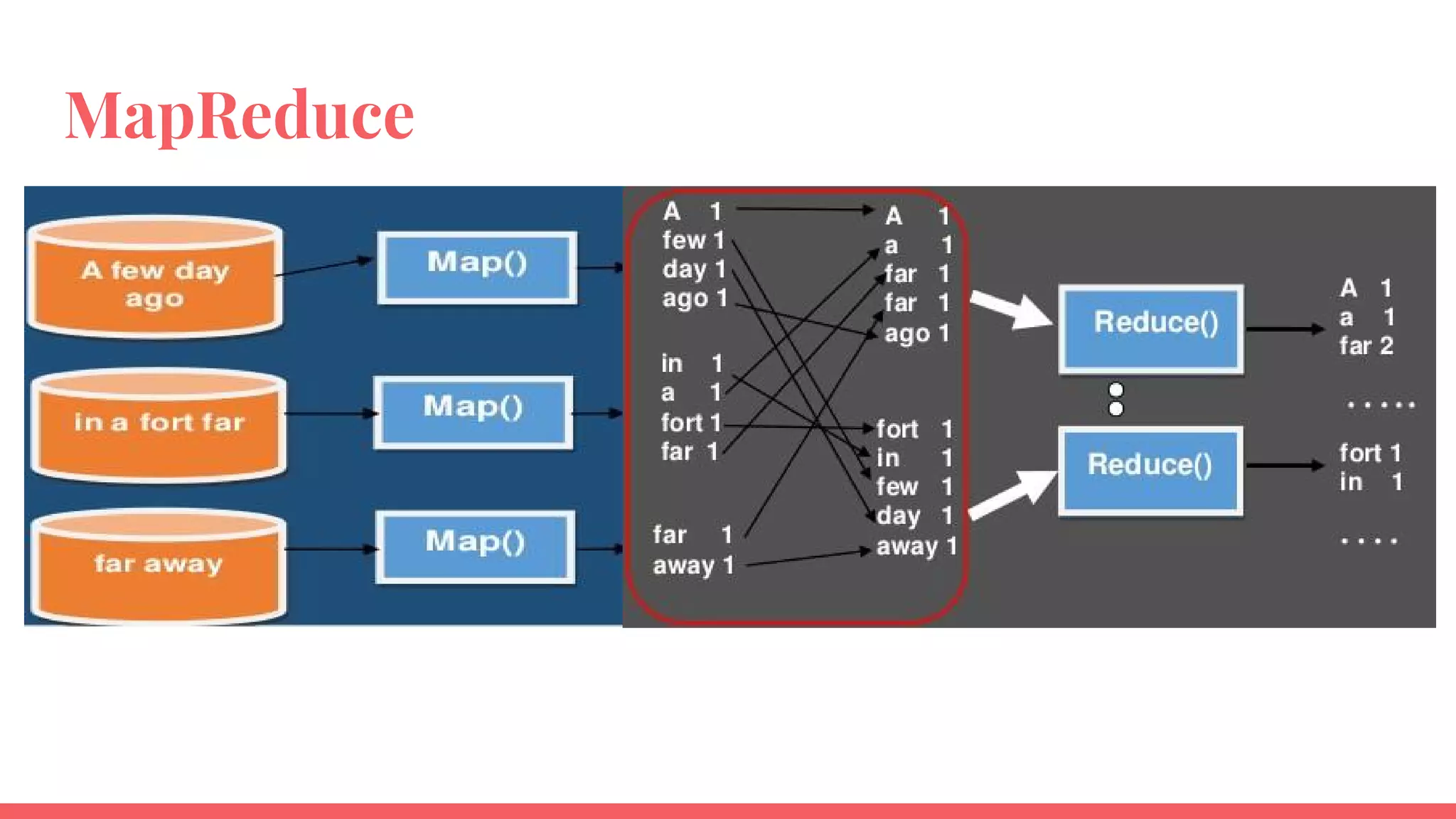
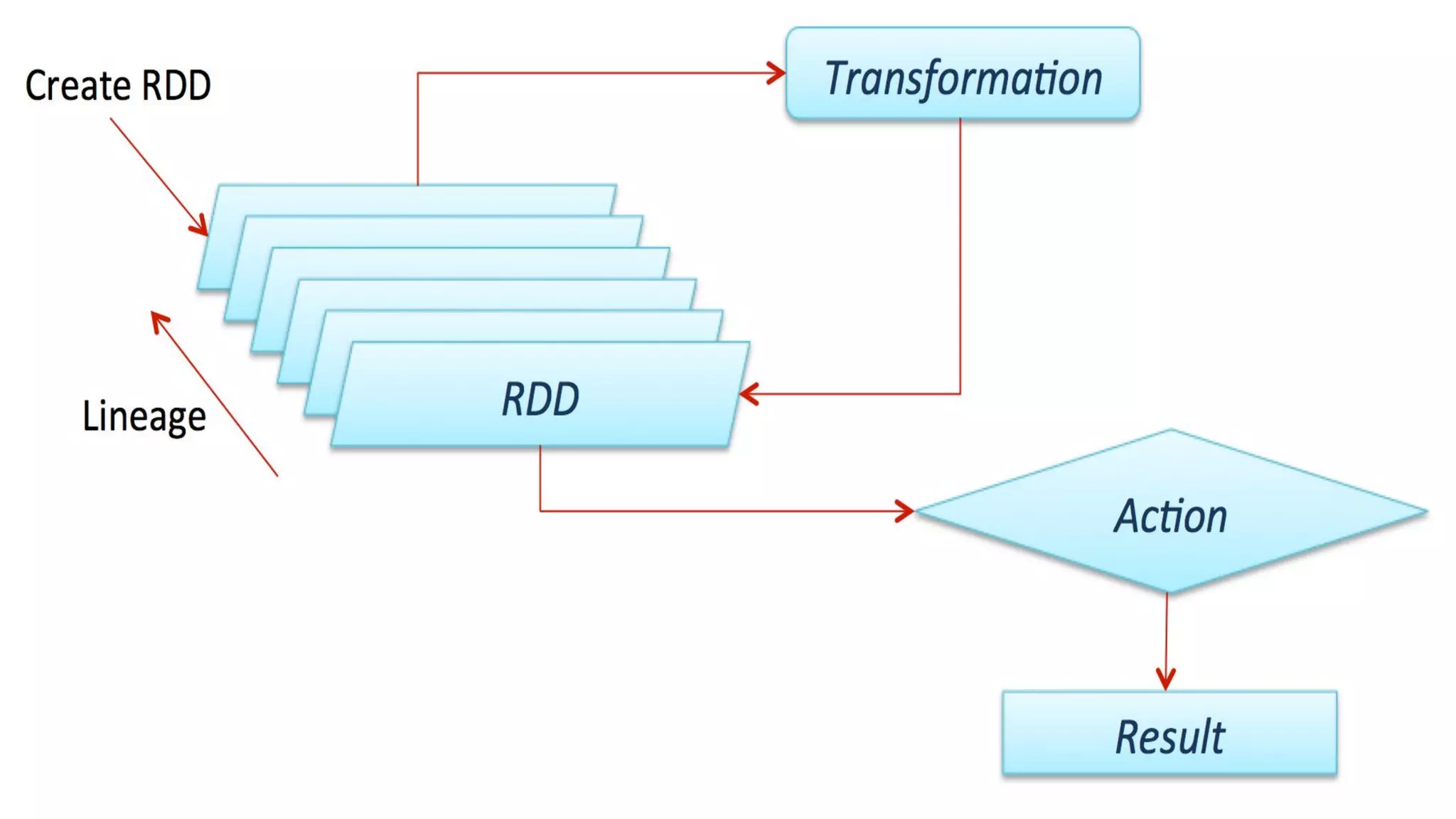
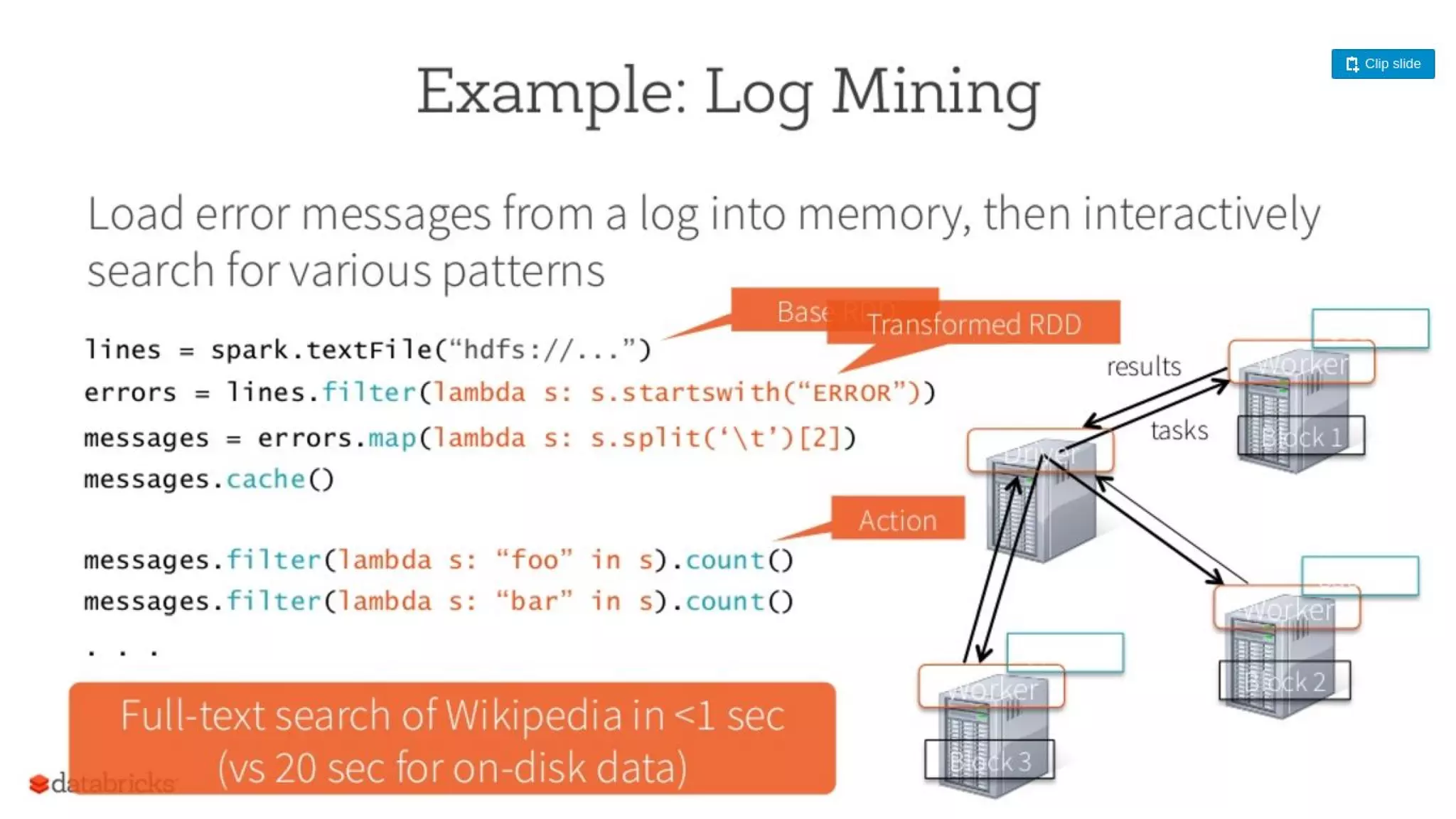
This document provides an overview of Apache Spark and compares it to Hadoop MapReduce. It defines big data and explains that Spark is a solution for processing large datasets in parallel. Spark improves on MapReduce by allowing in-memory computation using Resilient Distributed Datasets (RDDs) which makes it faster, especially for iterative jobs. Spark is also easier to program with rich APIs. While MapReduce is tolerant, Spark caching improves performance. Both are widely used but Spark sees more adoption for real-time applications due to its speed.





























![[@NaukriEngineering] Icon fonts & vector drawable in iOS apps](https://cdn.slidesharecdn.com/ss_thumbnails/iconfontsvectordrawableiniosapps2-161128054507-thumbnail.jpg?width=640&height=640&fit=bounds)













![Apache spark installation [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkinstallationautosaved-171023151151-thumbnail.jpg?width=640&height=640&fit=bounds)












![[@NaukriEngineering] Deferred deep linking in iOS](https://cdn.slidesharecdn.com/ss_thumbnails/deferreddeeplinkinginios-180322075651-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Instant Apps](https://cdn.slidesharecdn.com/ss_thumbnails/instantapp-171103101040-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Video handlings on apple platforms](https://cdn.slidesharecdn.com/ss_thumbnails/videohandlingsonappleplatforms-171103100719-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Introduction to Android O](https://cdn.slidesharecdn.com/ss_thumbnails/androidpptfinal-171101110739-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] MVVM in iOS](https://cdn.slidesharecdn.com/ss_thumbnails/mvvminios-170828085359-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Introduction to Galera cluster](https://cdn.slidesharecdn.com/ss_thumbnails/galeracluster-170509063459-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Inbound Emails for Every Web App: Angle](https://cdn.slidesharecdn.com/ss_thumbnails/angle-hookyourinboundmails-170403091813-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] BDD implementation using Cucumber](https://cdn.slidesharecdn.com/ss_thumbnails/bdd-170322112425-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Feature Toggles](https://cdn.slidesharecdn.com/ss_thumbnails/featurestoggles1-170207065624-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] AppTracer](https://cdn.slidesharecdn.com/ss_thumbnails/apptracerpresentation-161125064808-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Flux Architecture](https://cdn.slidesharecdn.com/ss_thumbnails/flux-161117094040-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Mobile Web app scripts execution using Appium](https://cdn.slidesharecdn.com/ss_thumbnails/html5mobilesiteautomationusingappiumdemo-161117070734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Messaging Queues](https://cdn.slidesharecdn.com/ss_thumbnails/queueprocessing-161111064335-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Docker 101](https://cdn.slidesharecdn.com/ss_thumbnails/dockerbasics1-161109085245-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Git Basic Commands and Hacks](https://cdn.slidesharecdn.com/ss_thumbnails/gittechtalk-161108120807-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] IndexedDB](https://cdn.slidesharecdn.com/ss_thumbnails/indexeddb-161108105450-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] CSS4 Selectors – Part 1](https://cdn.slidesharecdn.com/ss_thumbnails/css4selectorsp1-160912111758-thumbnail.jpg?width=640&height=640&fit=bounds)



















