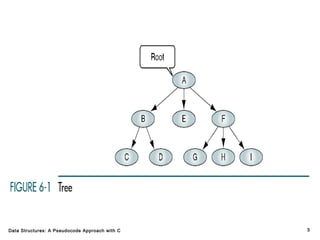
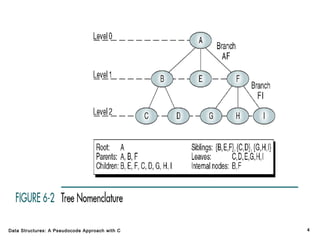
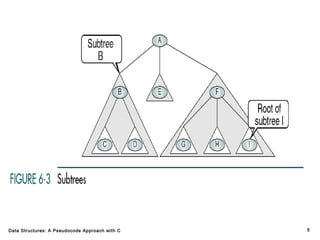
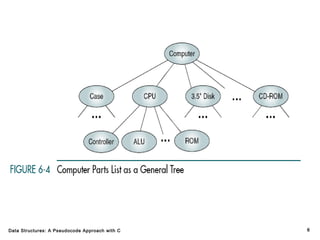
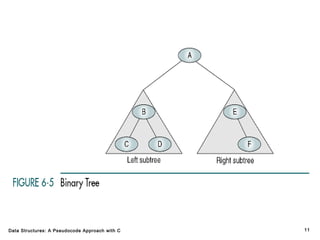
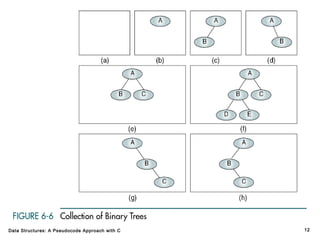
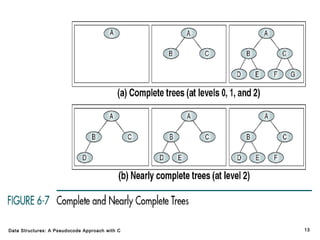
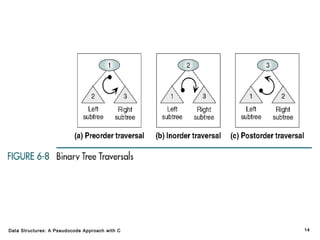
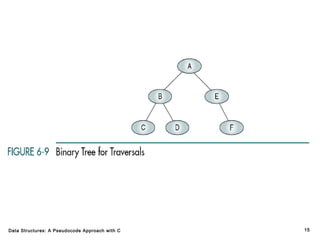
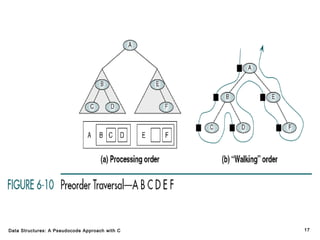
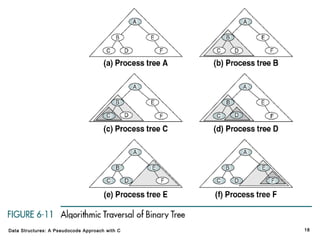
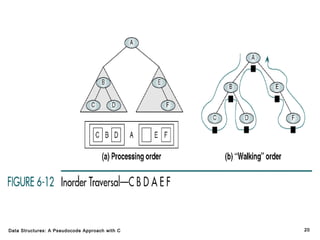
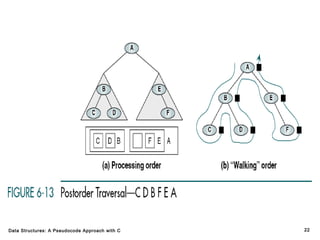
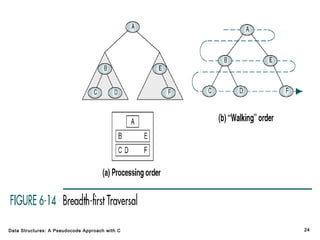
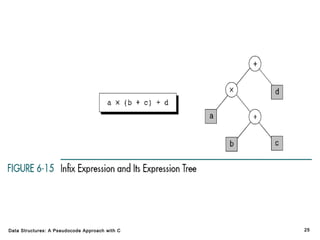
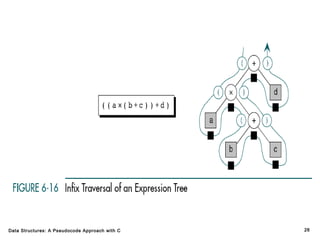
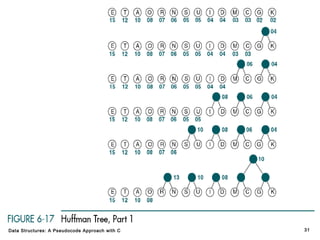
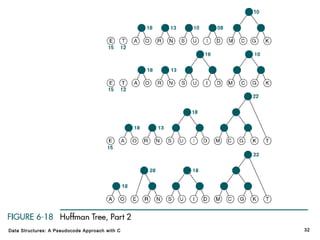
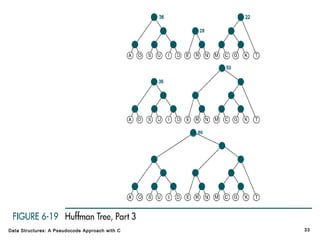
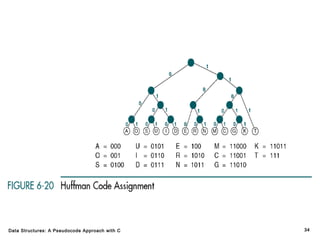
The document introduces the chapter on trees which covers basic tree terminology and concepts, binary trees, and general trees. It discusses understanding and using tree terminology, recognizing binary tree attributes, performing depth-first and breadth-first traversals on trees, parsing expressions using binary trees, designing and implementing Huffman trees, and understanding the basic use and processing of general trees. The chapter also covers properties of and traversals on binary trees, using trees for expression parsing and Huffman coding, insertions and deletions in general trees, and converting a general tree to a binary tree.































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














