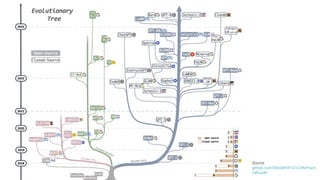
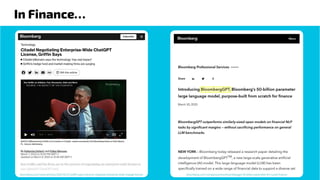
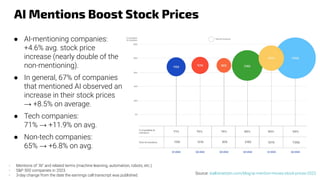
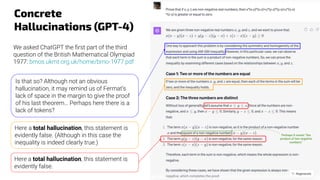
The document provides an overview of the evolution and current state of large language models (LLMs), emphasizing their transformative impact on various domains such as text, image, and music generation. It discusses significant milestones from early systems like ELIZA to modern models like ChatGPT, highlighting their capabilities and challenges, such as hallucinations and drift in performance. Additionally, it addresses the implications of LLMs on industries, including finance, and explores the intricacies of model training, prompt engineering, and fine-tuning in maximizing their effectiveness.
















![Chemistry May Not Be ChatGPT Cup of Tea
A study conducted by three researchers of the University of
Hertfordshire (UK) showed that ChatGPT is not a fan of
chemistry.
Real exams were used, and the authors note that “[a] well-written
question item aims to create intellectual challenge and to require
interpretation and inquiry. Questions that cannot be easily
‘Googled’ or easily answered through a single click in an
internet search engine is a focus.”
“The overall grade on the year 1 paper calculated from the top
four graded answers would be 34.1%, which does not meet the
pass criteria. The overall grade on the year 2 paper would be
18.3%, which does not meet the pass criteria.”
Source: Fergus et al., 2023, Evaluating Academic Answers Generated Using ChatGPT (pubs.acs.org/doi/10.1021/acs.jchemed.3c00087)](https://image.slidesharecdn.com/introllmslhnov2023shared-231107210635-cba19bd0/85/Introduction-to-LLMs-24-320.jpg)


![Prompt Engineering: “Query Crafting”
Improving the output with actions like phrasing
queries, specifying styles, providing context, or
assigning roles (e.g., 'Act as a mathematics
teacher') (Wikipedia, 2023).
Some hints can be found in OpenAI’s “GPT best
practices” (OpenAi, 2023).
Chain-of-thought: popular technique consisting
in “guiding [LLMs] to produce a sequence of
intermediate steps before giving the final answer”
(Wei et al., 2022).
Sources:
- Wei, J.et al., 2022. Emergent abilities of large language models, arxiv.org/abs/2206.07682
- OpenAI, 2023, platform.openai.com/docs/guides/gpt-best-practices/six-strategies-for-getting-better-results
- Wikipedia, 2023, , Prompt Engineering, en.wikipedia.org/wiki/Prompt_engineering
(graph from Wei et al., 2022)
About GSM8K benchmark: arxiv.org/abs/2110.14168](https://image.slidesharecdn.com/introllmslhnov2023shared-231107210635-cba19bd0/85/Introduction-to-LLMs-30-320.jpg)

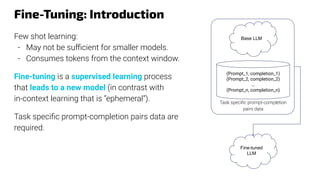



![Reinforcement Learning From Human Feedback
LLMs are trained on the web data with a lot of irrelevant matters (unhelpful), or worse,
where false (dishonest) and/or harmful information are abundant, e.g.,
● Potentially dangerous false medical advices.
● Valid techniques for illegal activities (hacking, deceiving, building weapons, …).
HHH (Helpful, Honest & Harmless) alignment (Askell et al., 2021): ensuring that the
model's behavior and outputs are consistent with human values, intentions, and ethical
standards.
Reinforcement Learning from Human Feedback, or RLHF (Casper et al., 2023)
● “is a technique for training AI systems to align with human goals.”
● “[It] has emerged as the central method used to finetune state-of-the-art [LLMs].”
● It reposes on human judgment and consensus.
Source:
- Casper et al., 2023, Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback. arxiv.org/abs/2307.15217
- Ziegler et al., 2022, Fine-Tuning Language Models from Human Preferences. arxiv.org/abs/1909.08593
- Askell et al., 2021, A General Language Assistant as a Laboratory for Alignment. arxiv.org/abs/2112.00861](https://image.slidesharecdn.com/introllmslhnov2023shared-231107210635-cba19bd0/85/Introduction-to-LLMs-36-320.jpg)


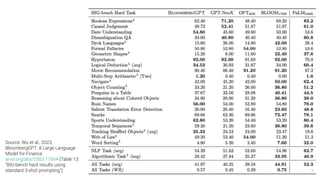


![Question ChatGPT About the Latest Financial
Reports?
—blog.langchain.dev/tutorial-
chatgpt-over-your-data
“[ChatGPT] doesn’t know about
your private data, it doesn’t know
about recent sources of data.
Wouldn’t it be useful if it did?”](https://image.slidesharecdn.com/introllmslhnov2023shared-231107210635-cba19bd0/85/Introduction-to-LLMs-46-320.jpg)