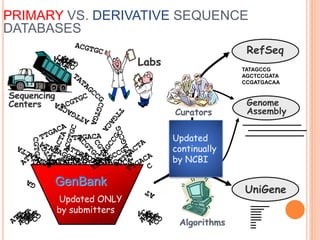
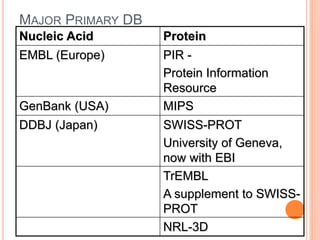
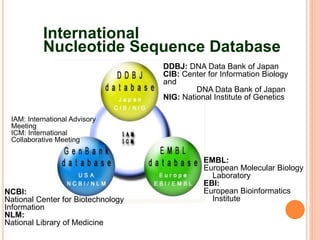
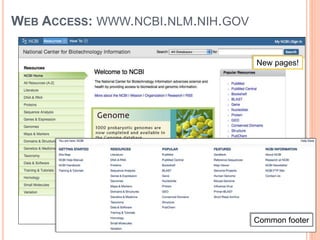
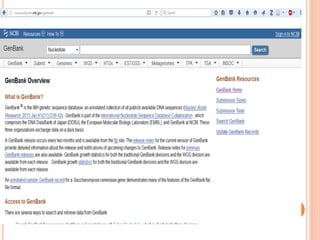
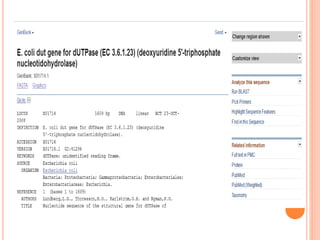
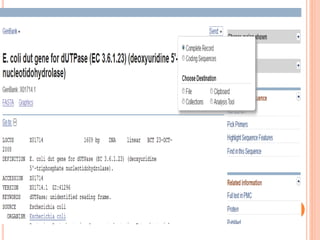
The document provides an overview of biological databases, their structure, and types, including primary and derivative databases. It highlights key features of data organization, the functionality of well-maintained databases, and the role of prominent databases like GenBank and Swiss-Prot. Additionally, it discusses the importance of data integration for revealing inter-related biological information.





































































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)




