Download as PDF, PPTX








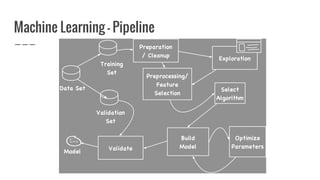
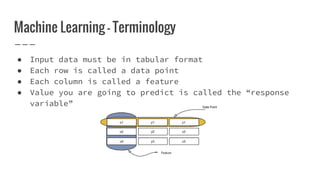

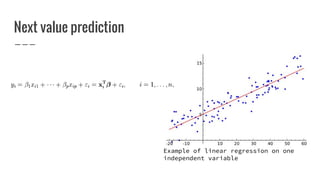
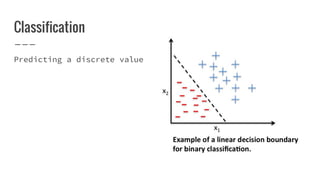
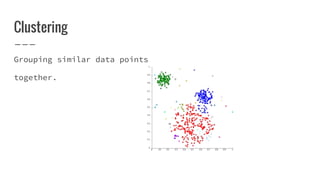


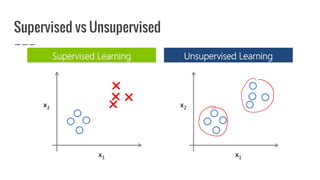













Nirmal Fernando is a technical lead at WSO2 who graduated from the University of Moratuwa. He discusses machine learning and predictive analytics, explaining that predictive analytics uses patterns in existing data to predict future outcomes. Machine learning gives computers the ability to learn without explicit programming. He then demonstrates building a logistic regression model using Apache Spark MLlib to predict whether individuals in the Pima Indian Diabetes dataset have diabetes.

















































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)












![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)




