Download to read offline



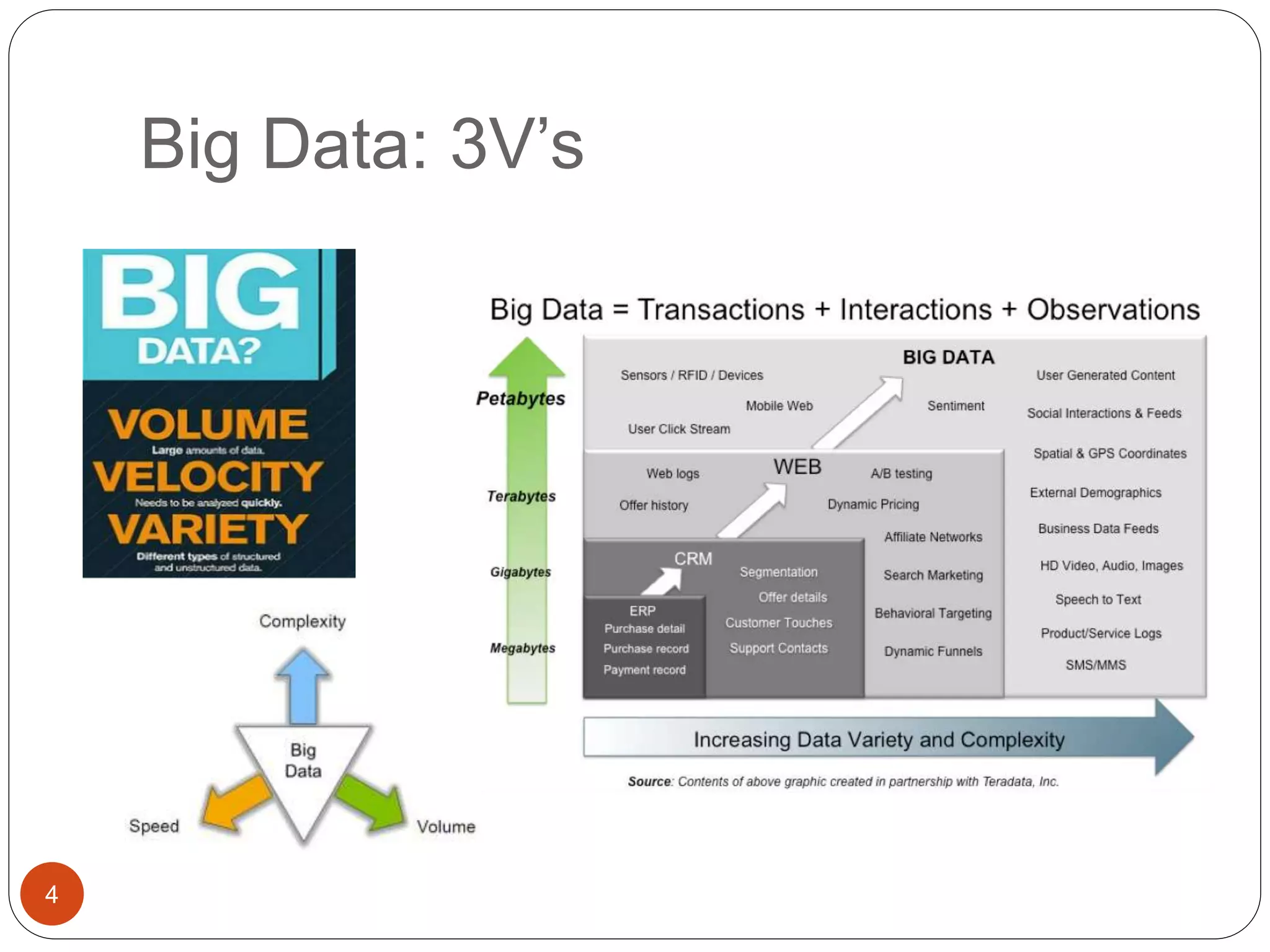
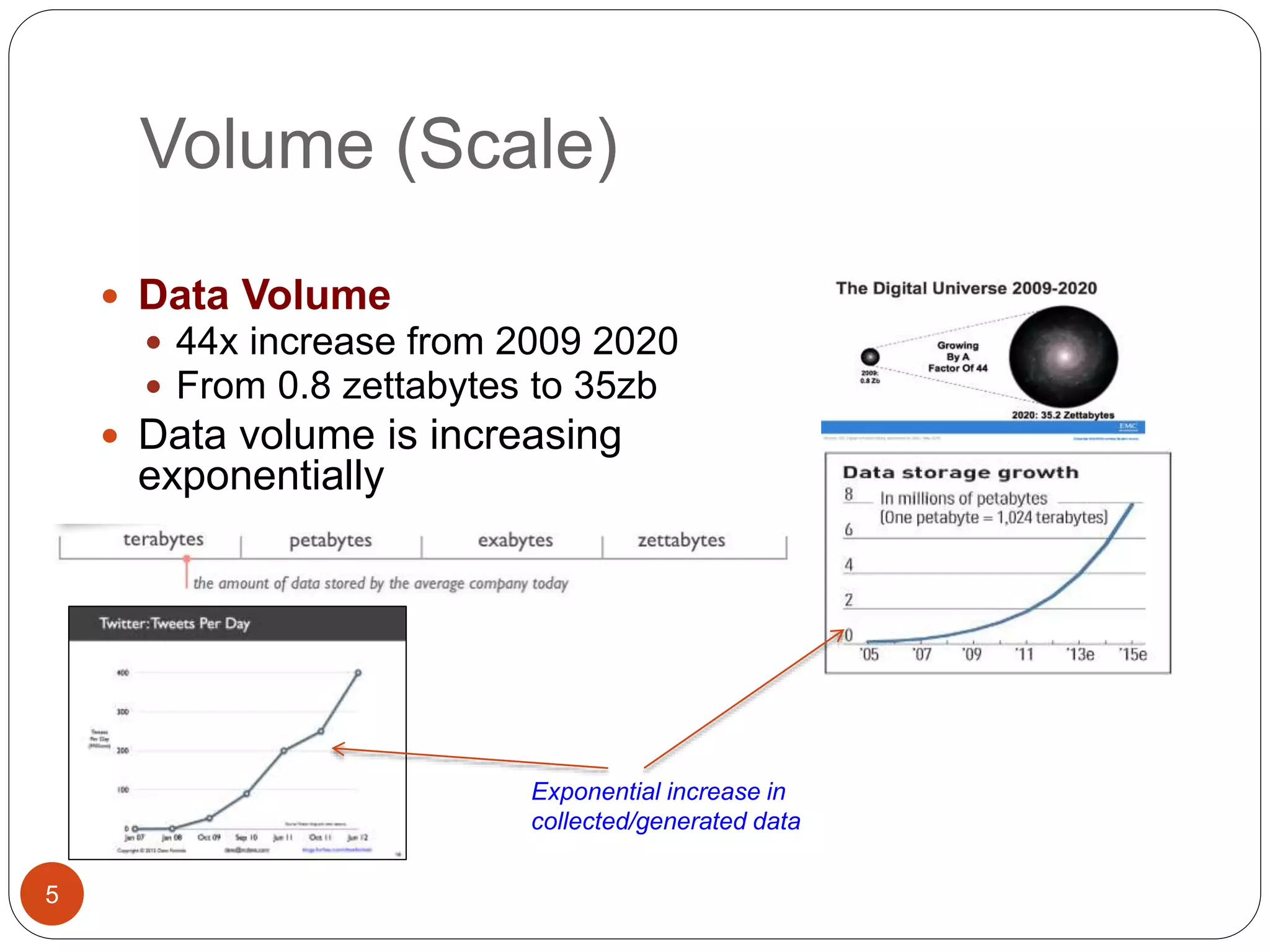






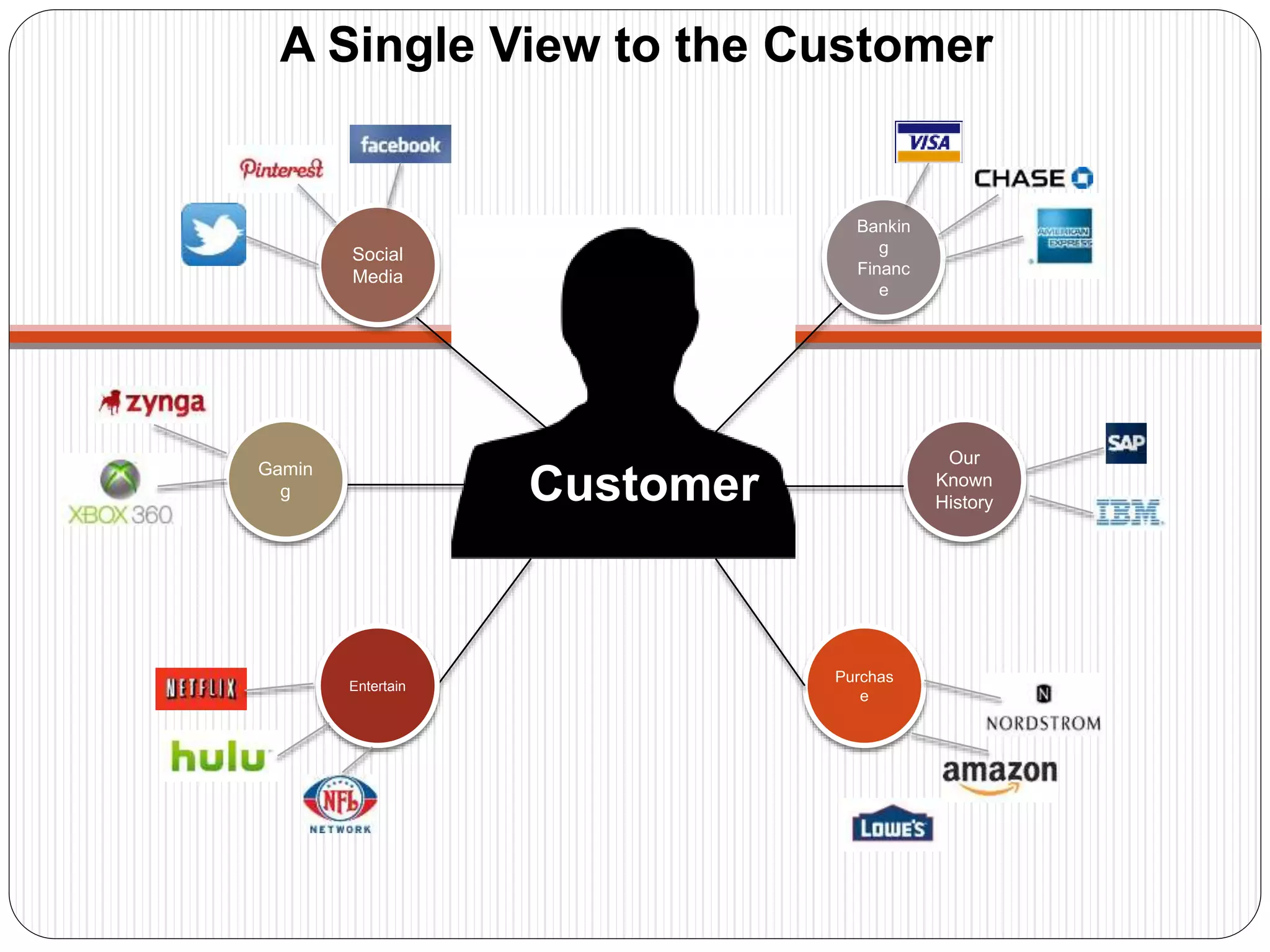


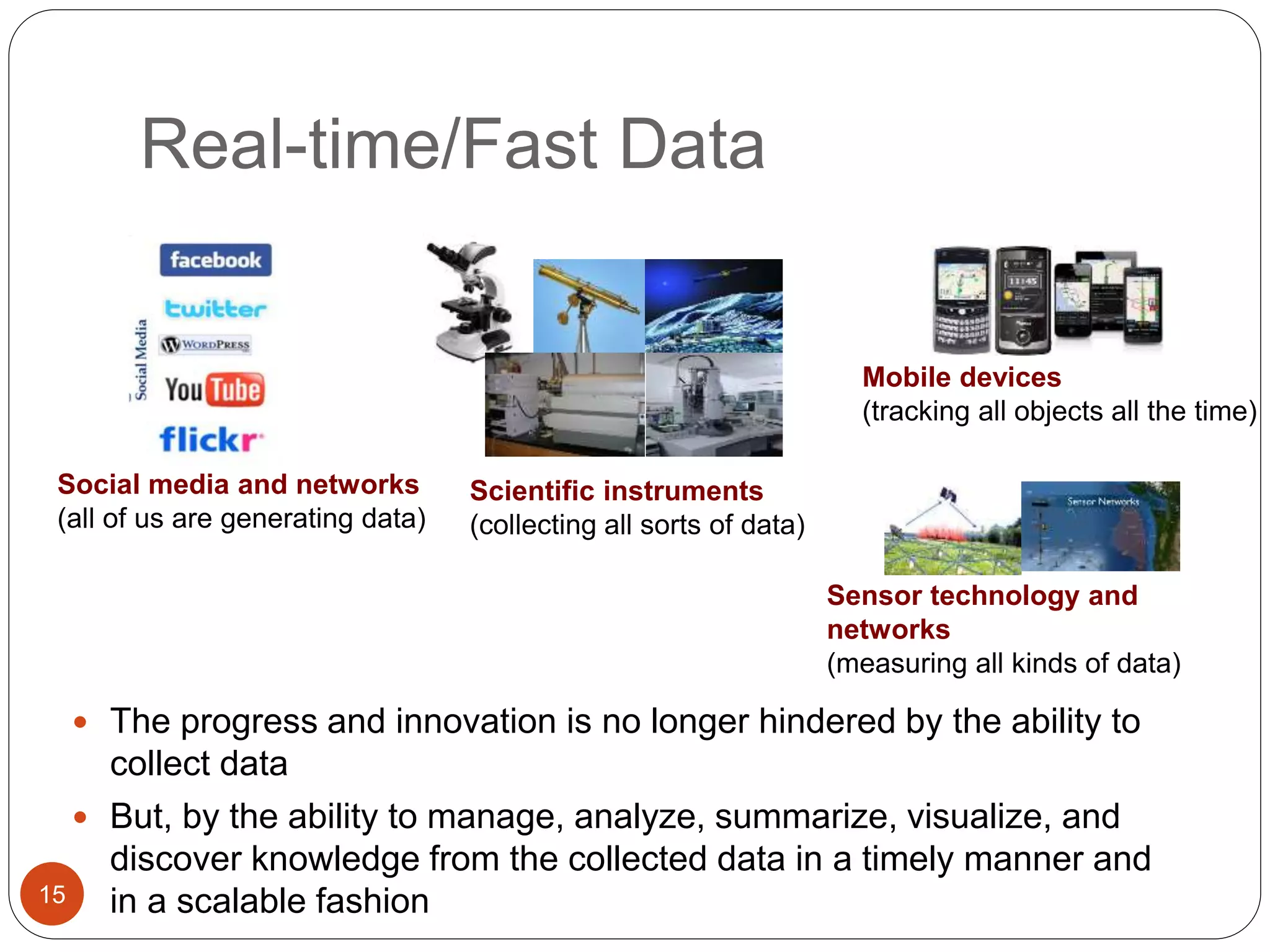
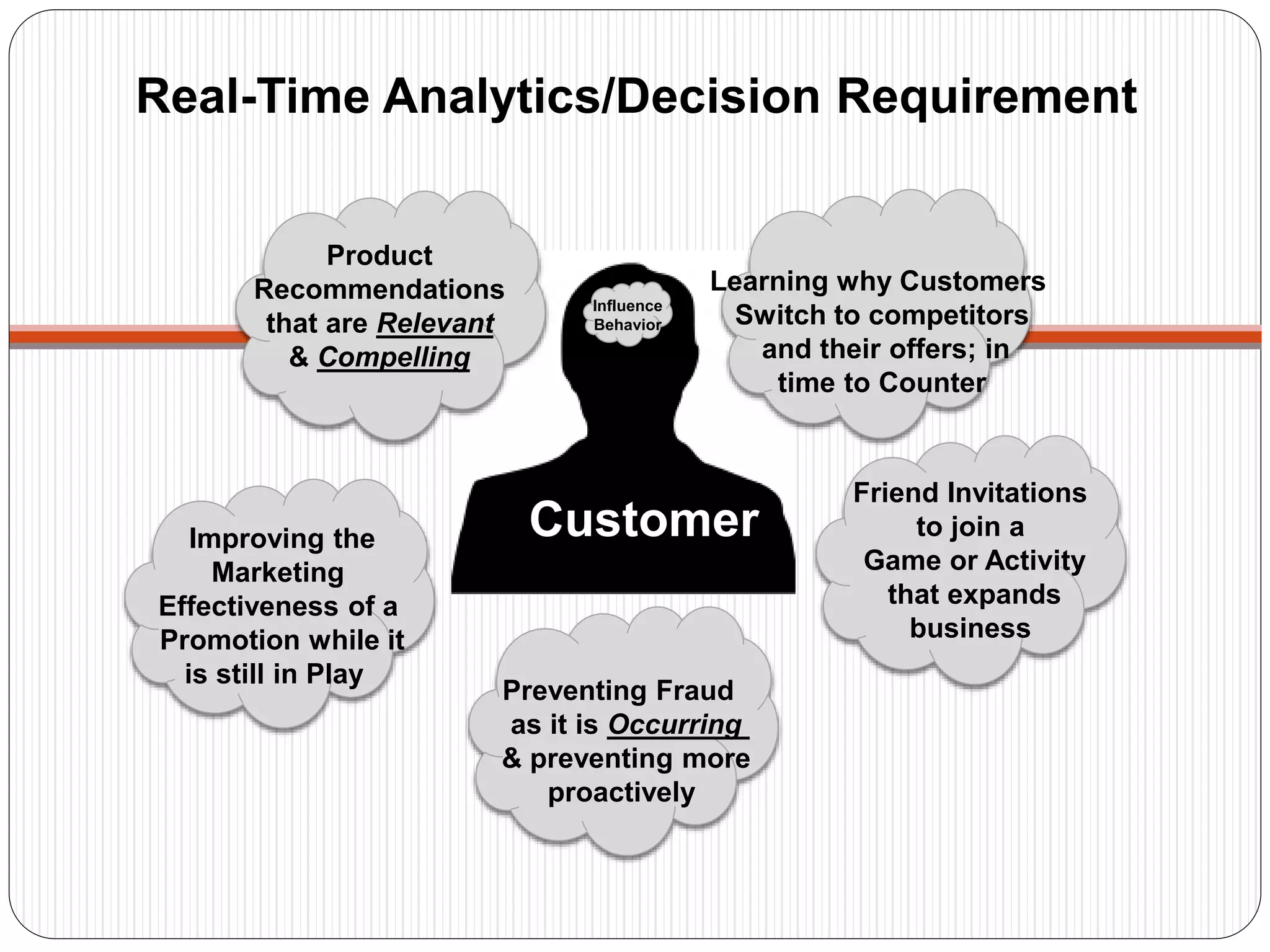
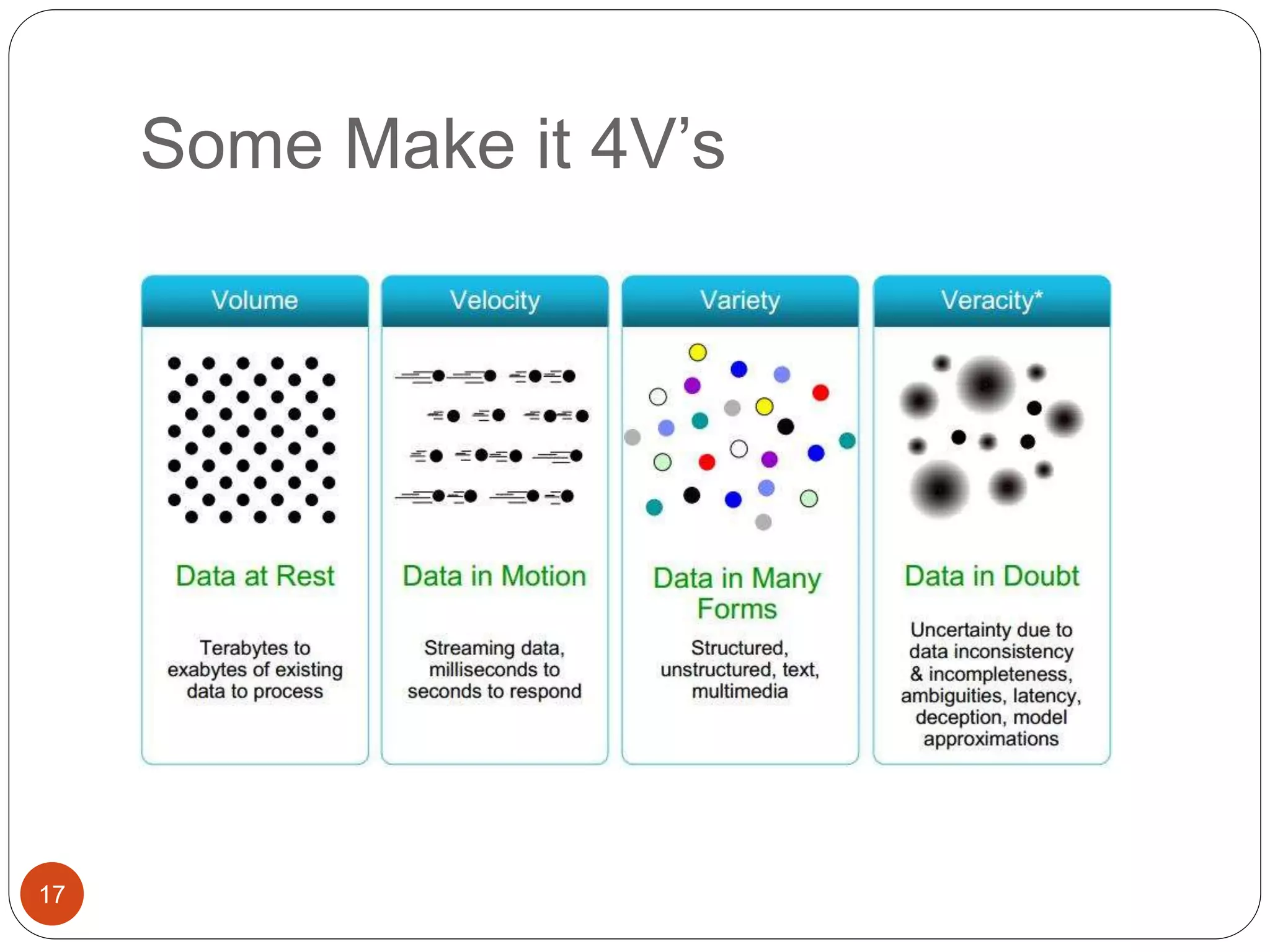


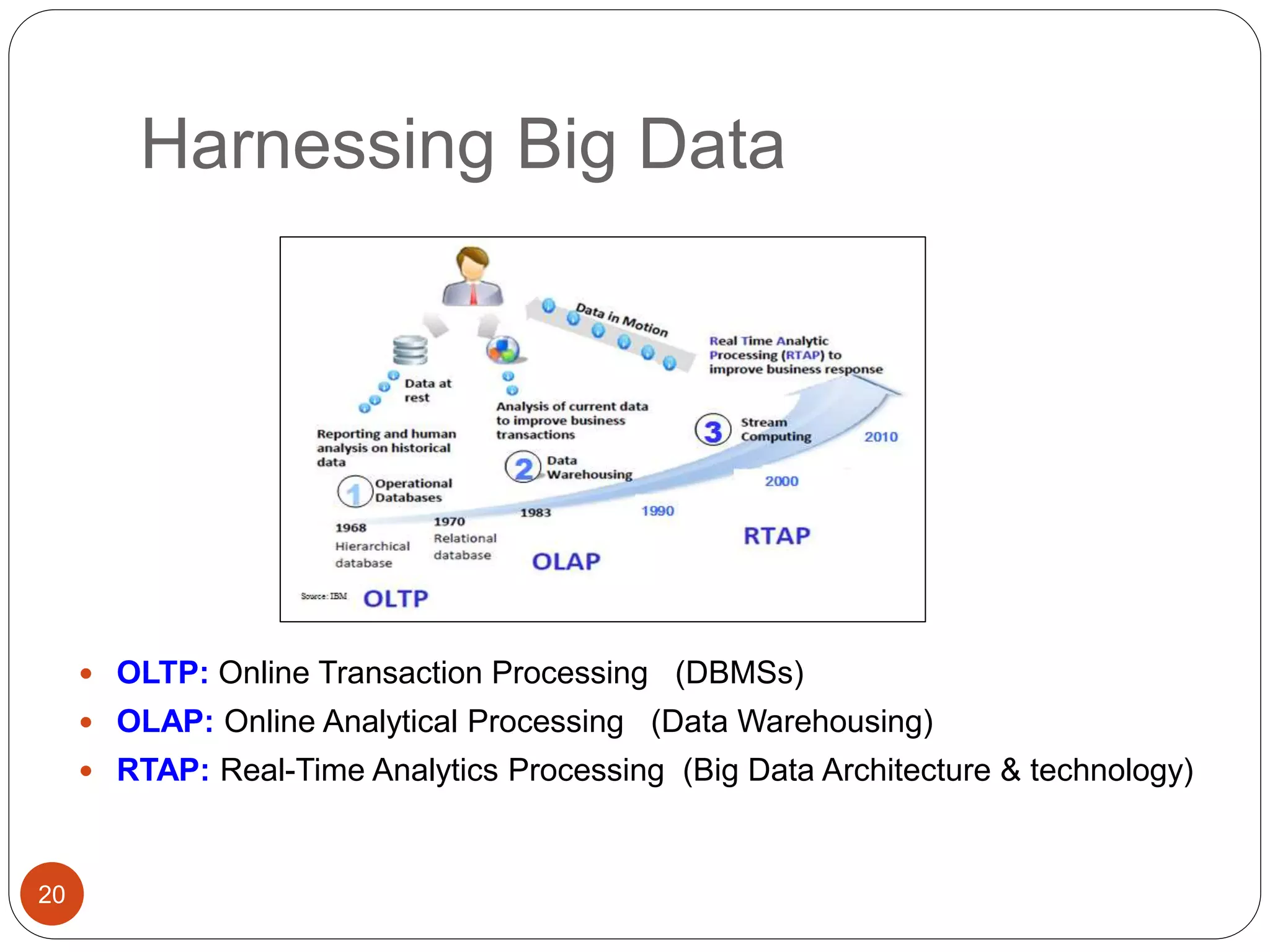

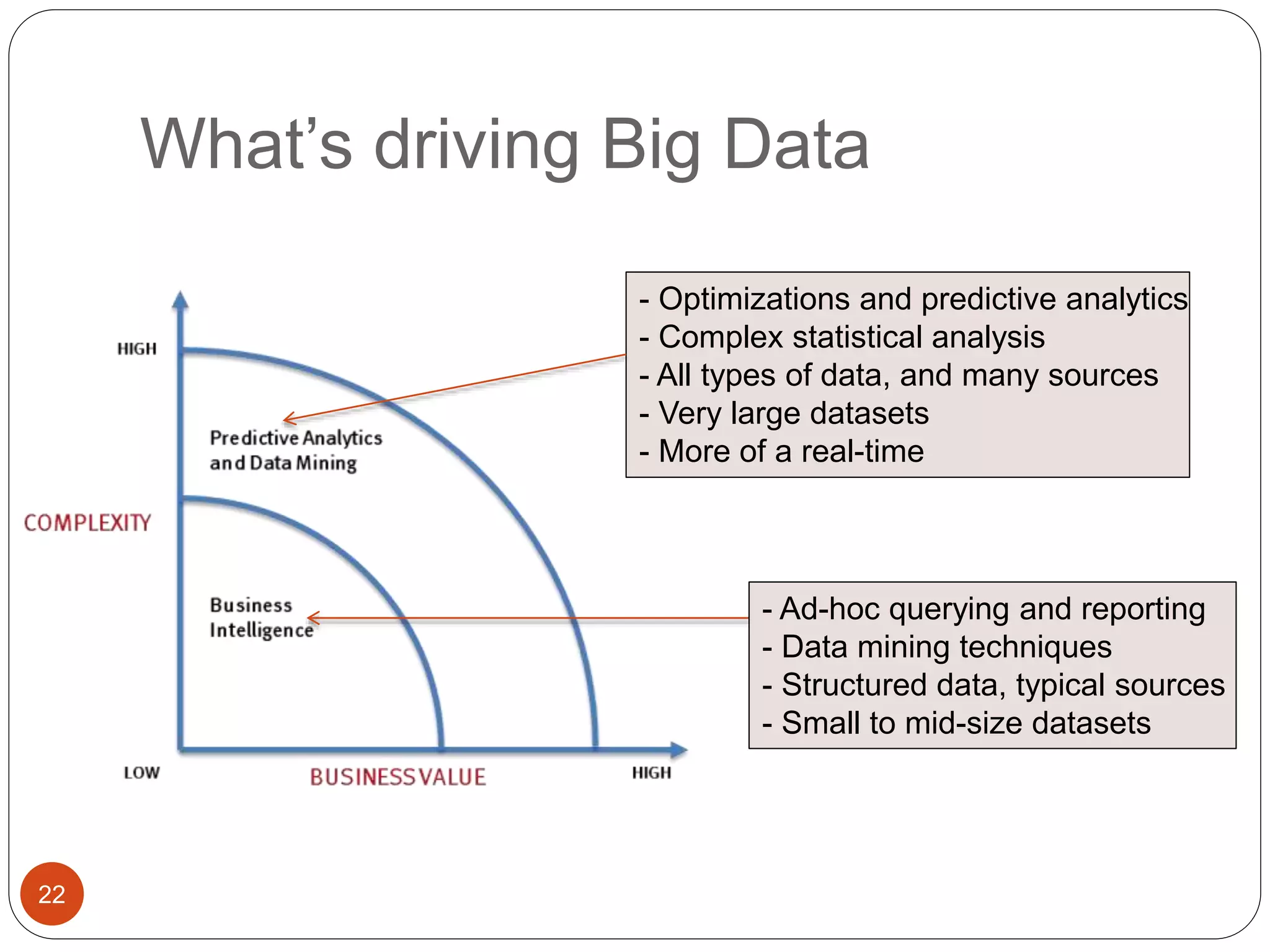
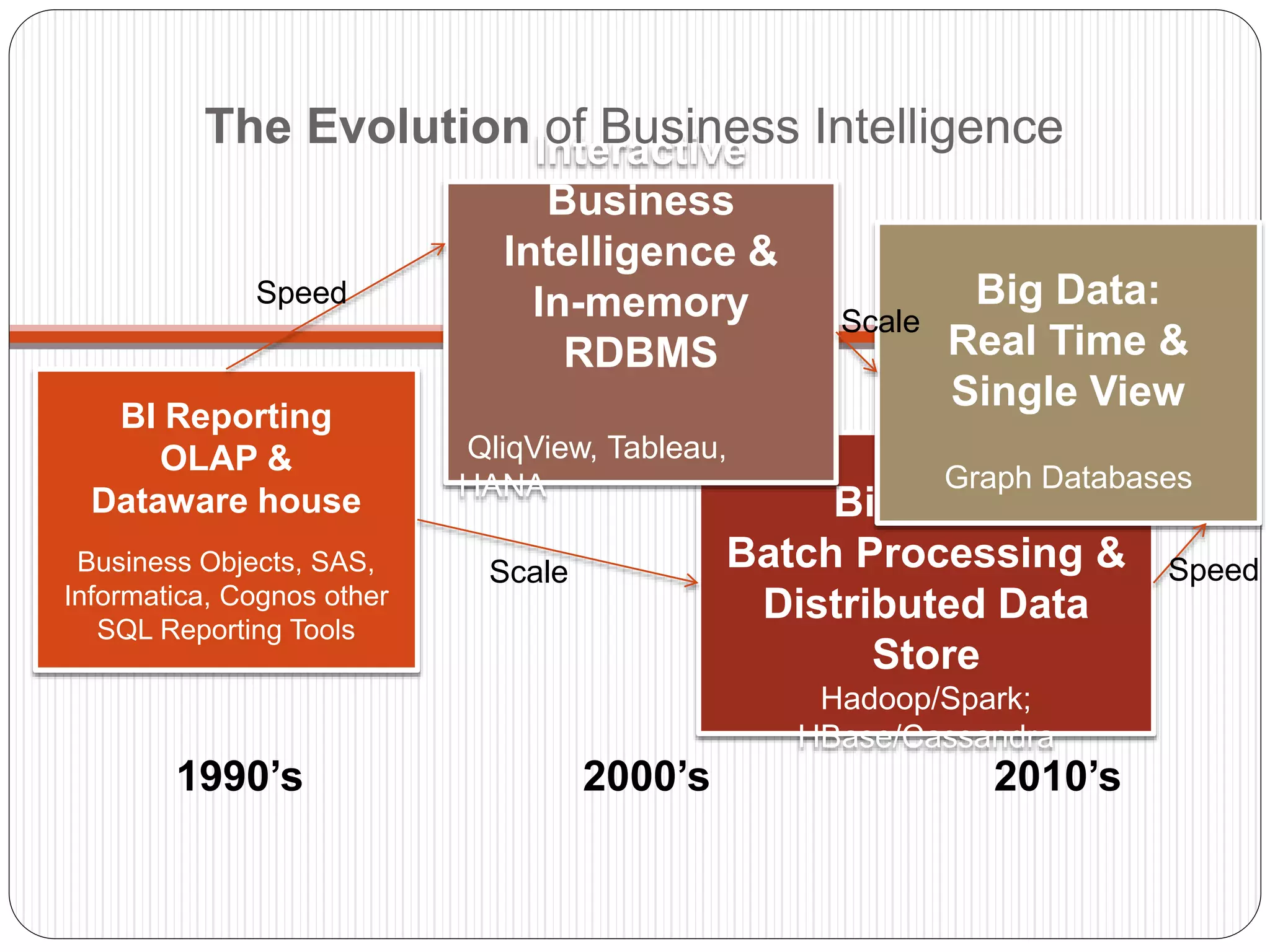
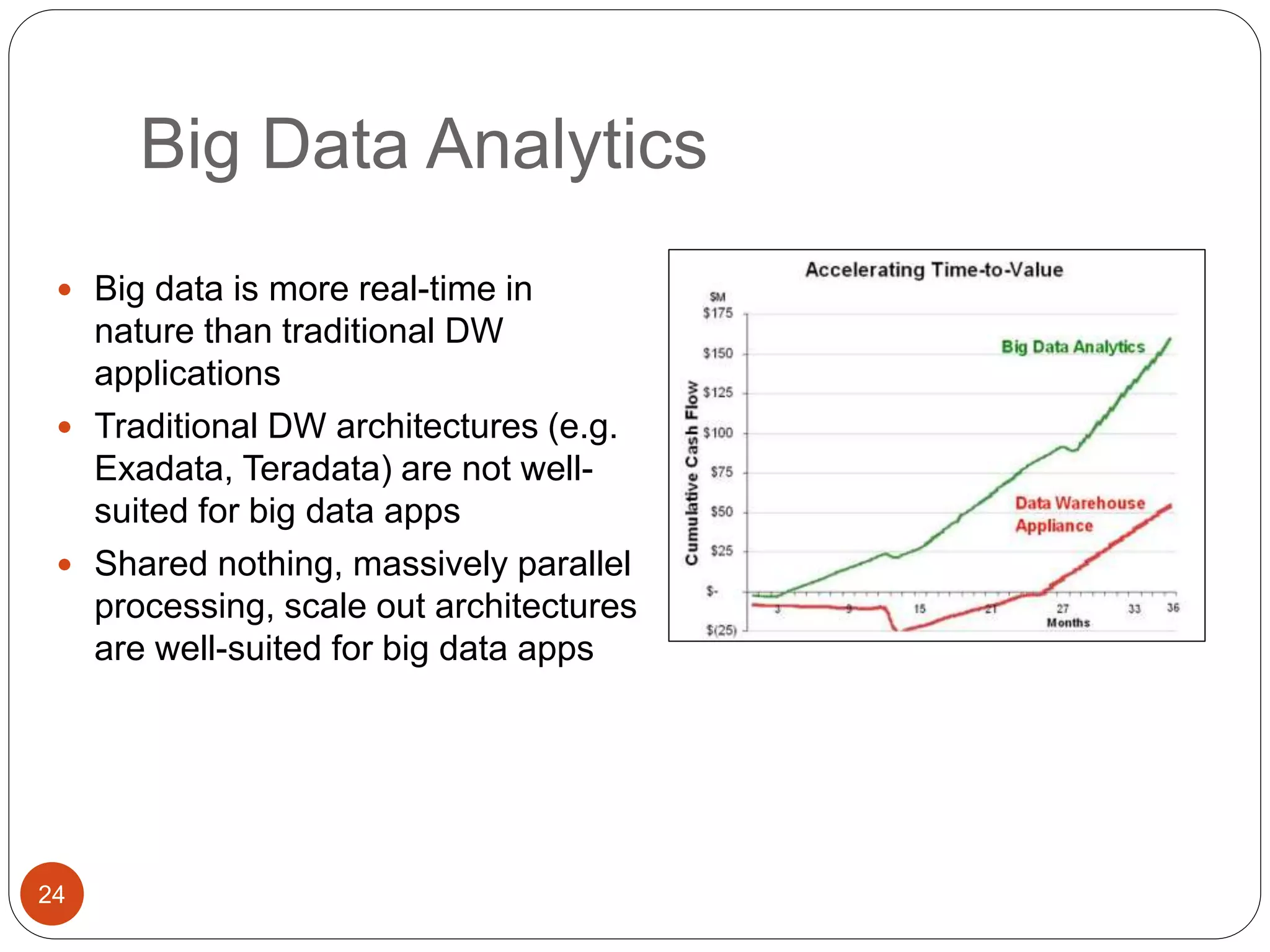
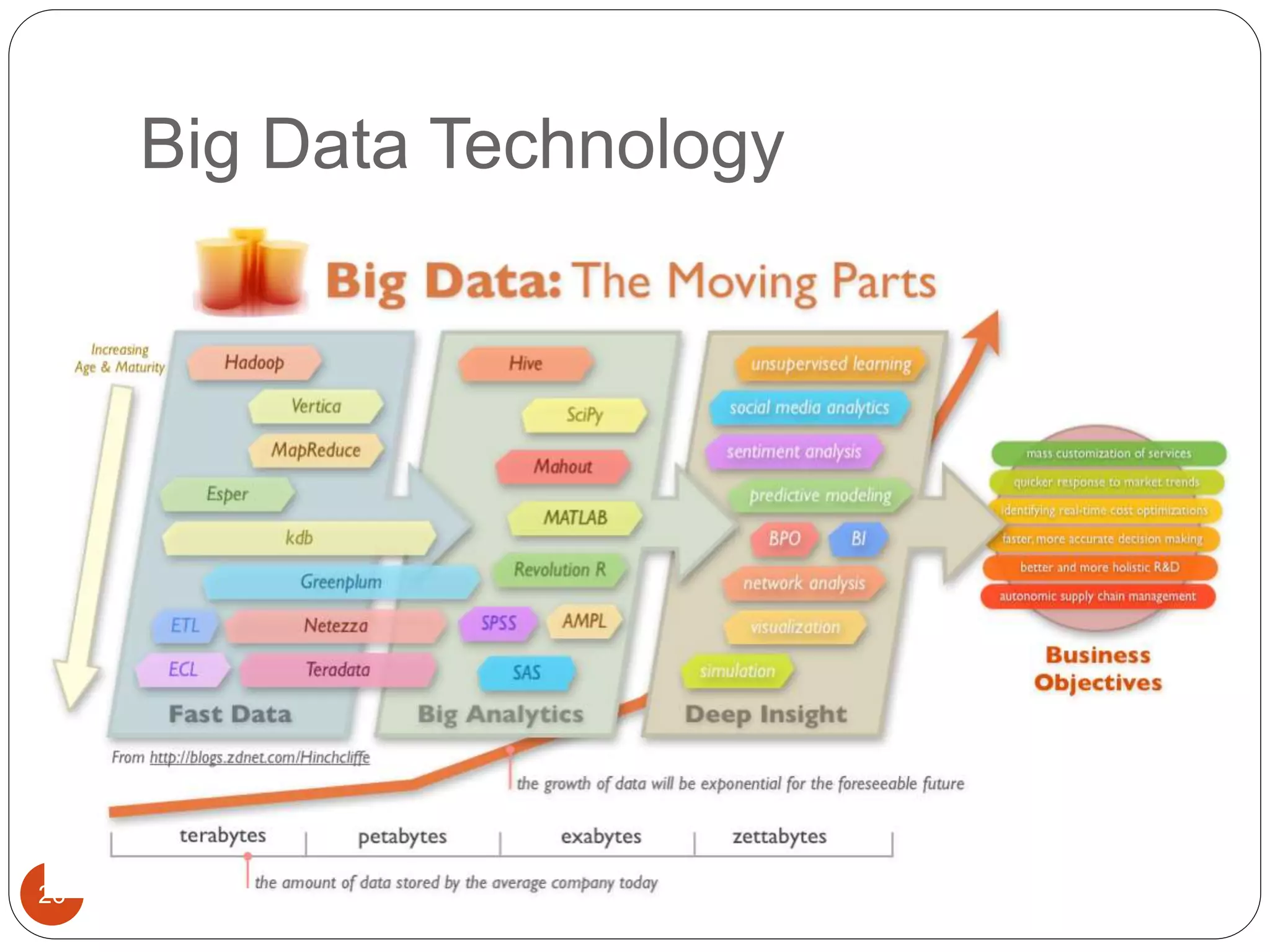









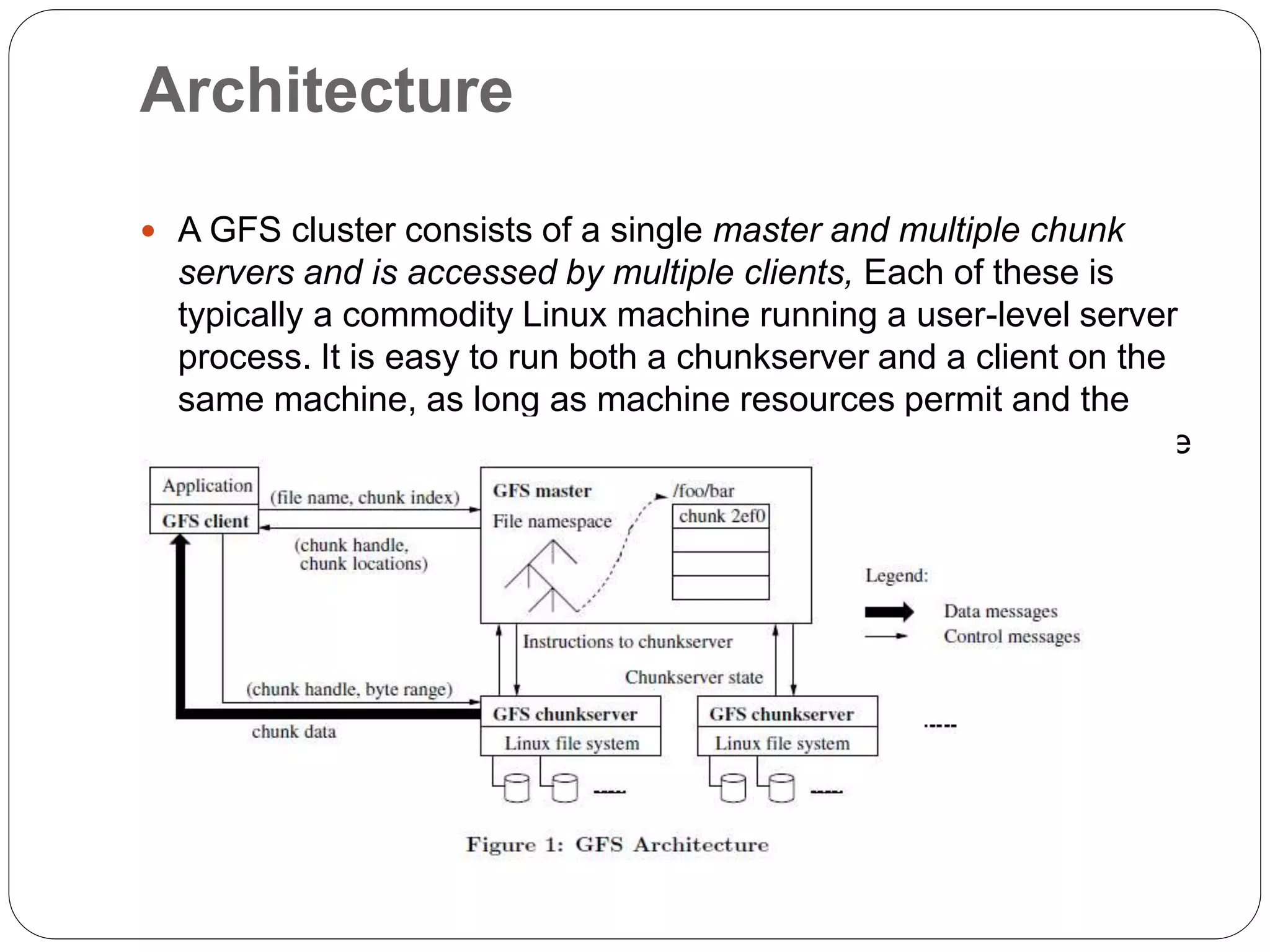


















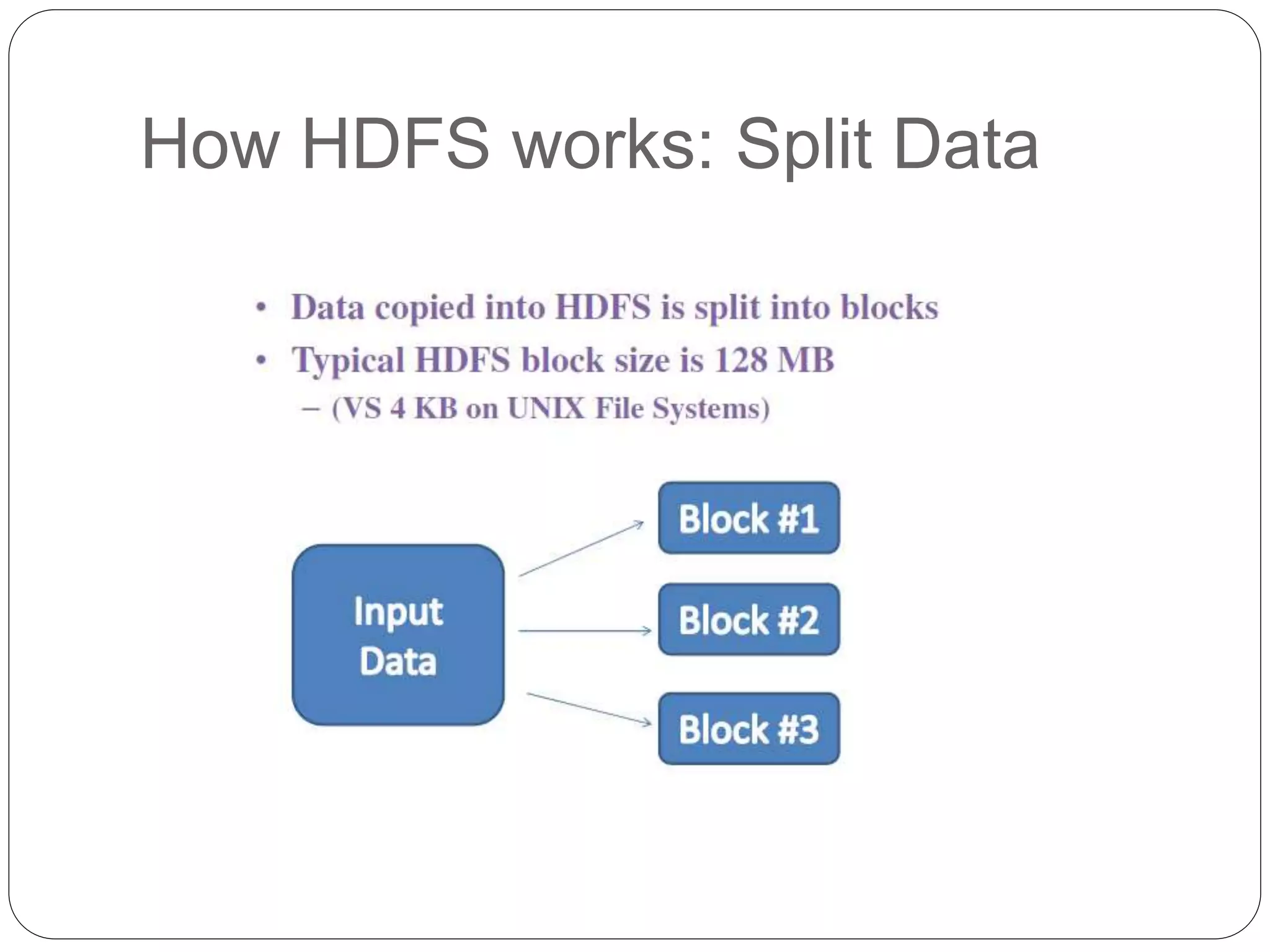

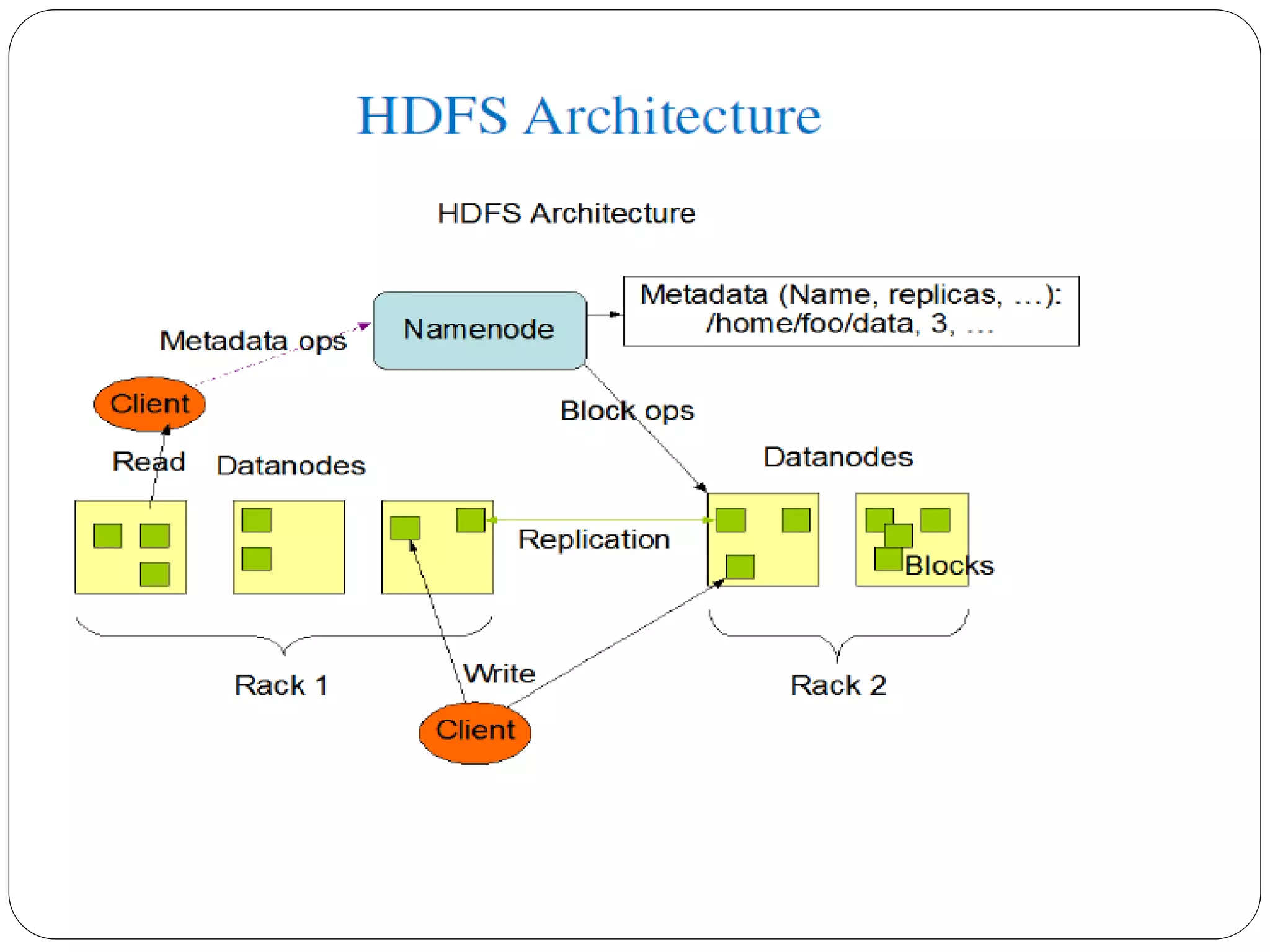
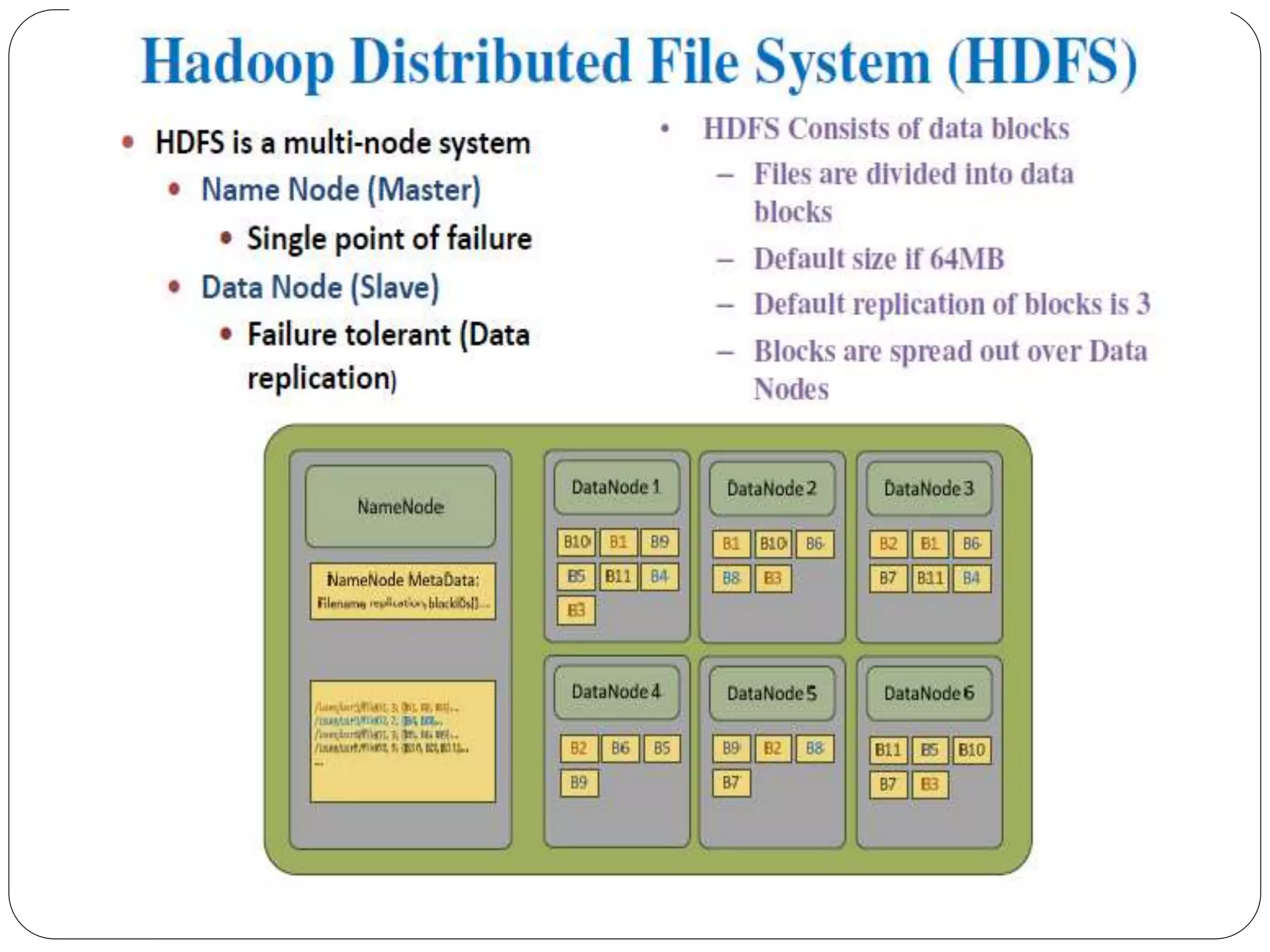
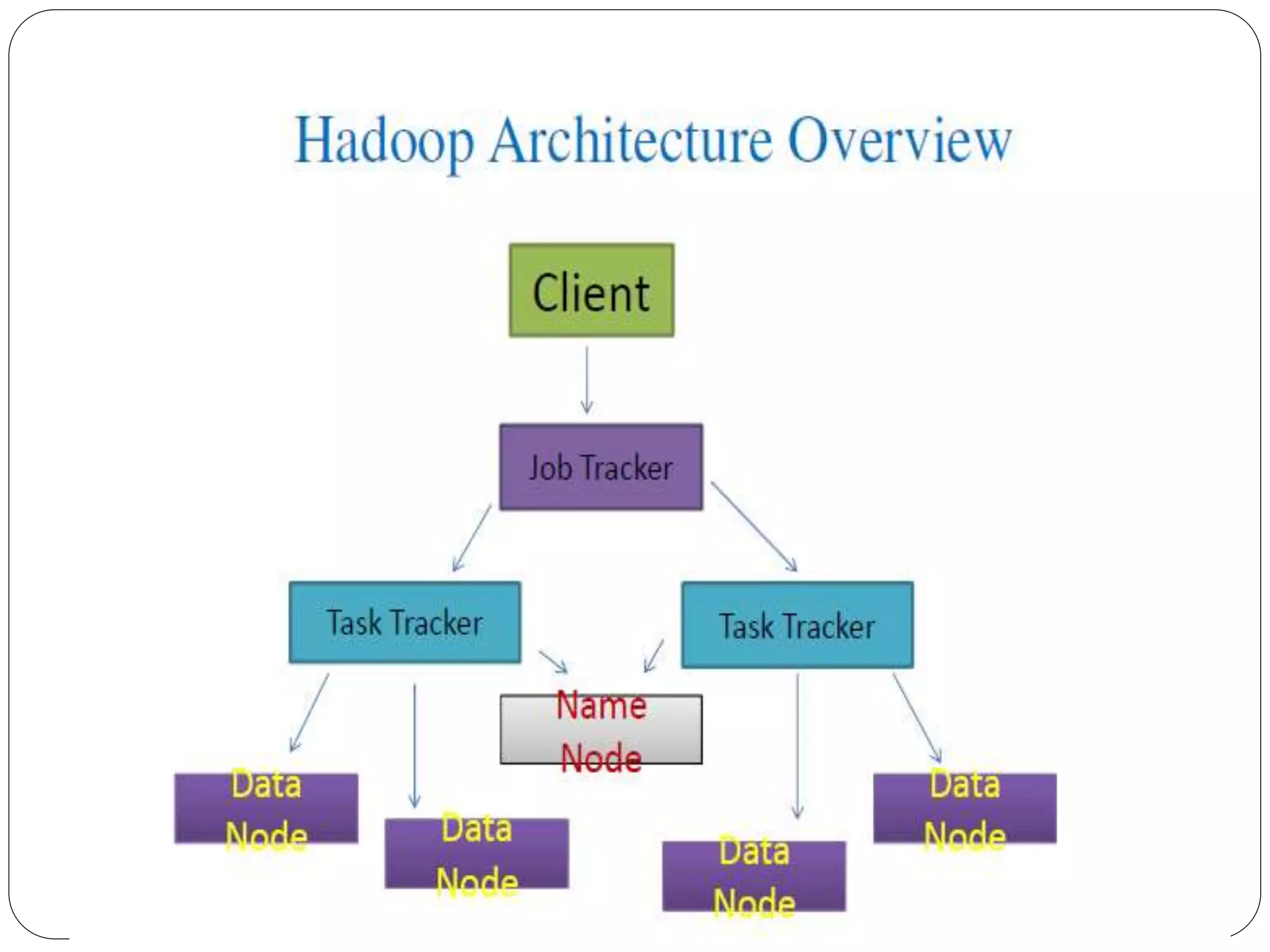
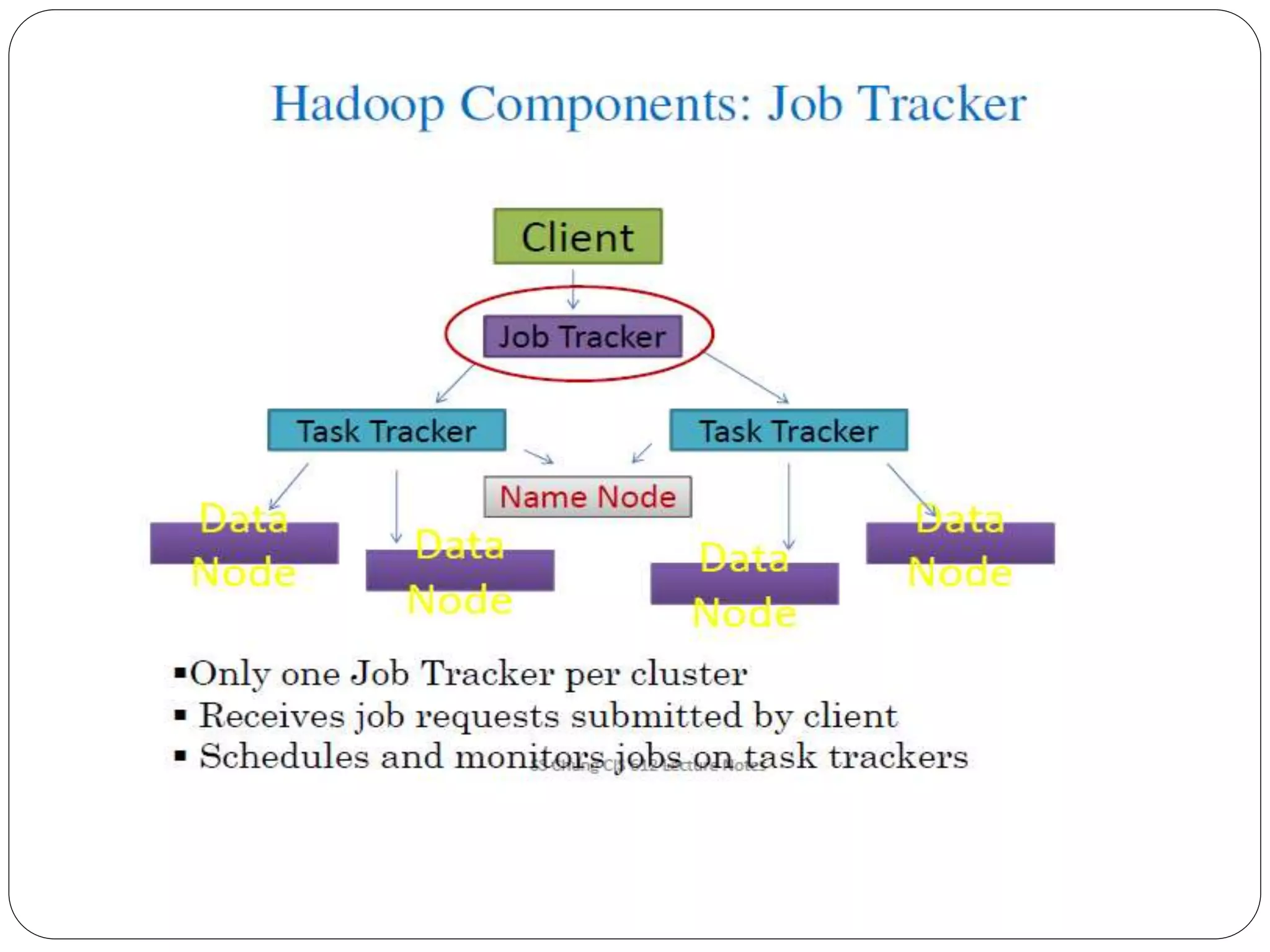
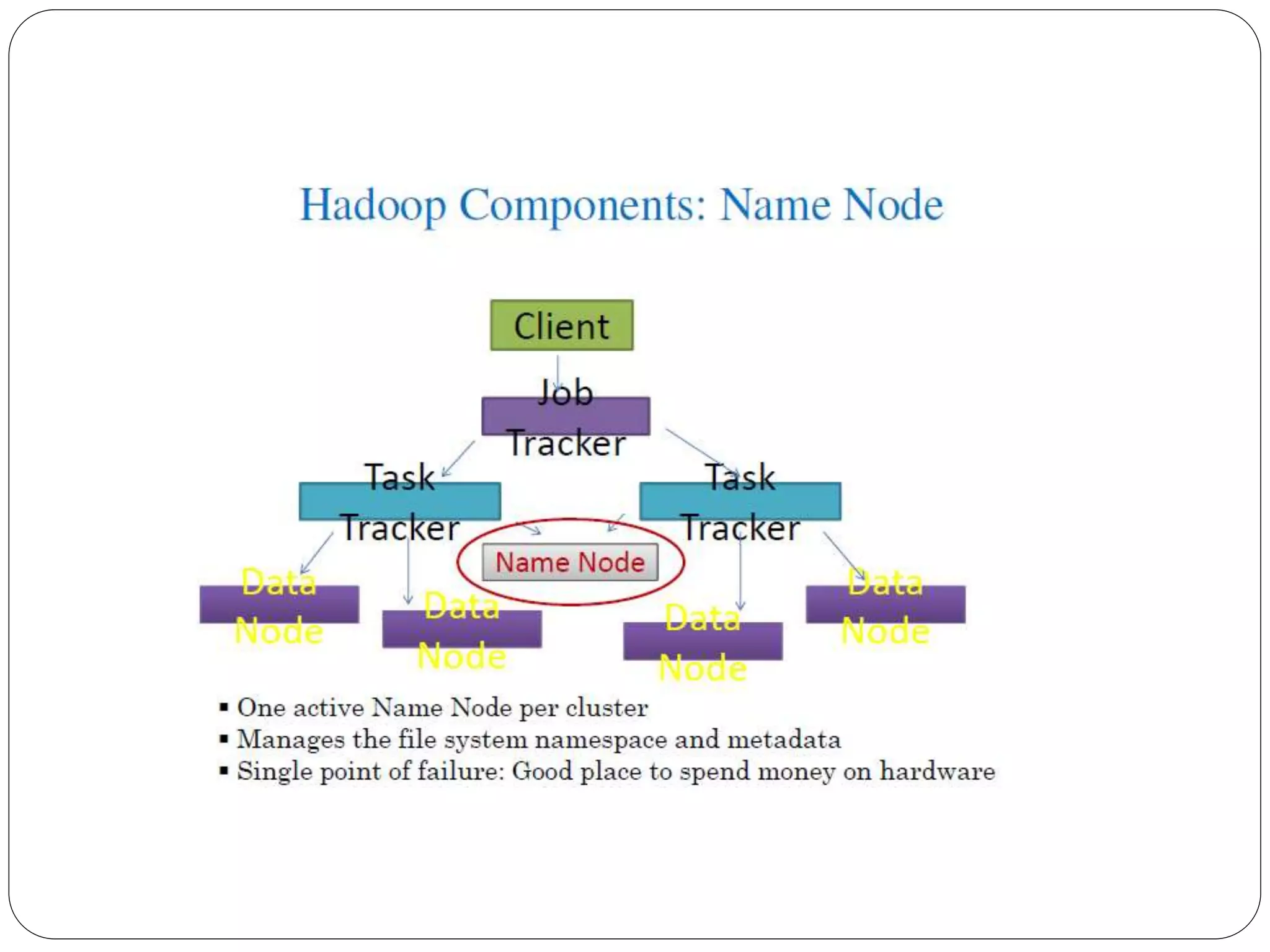

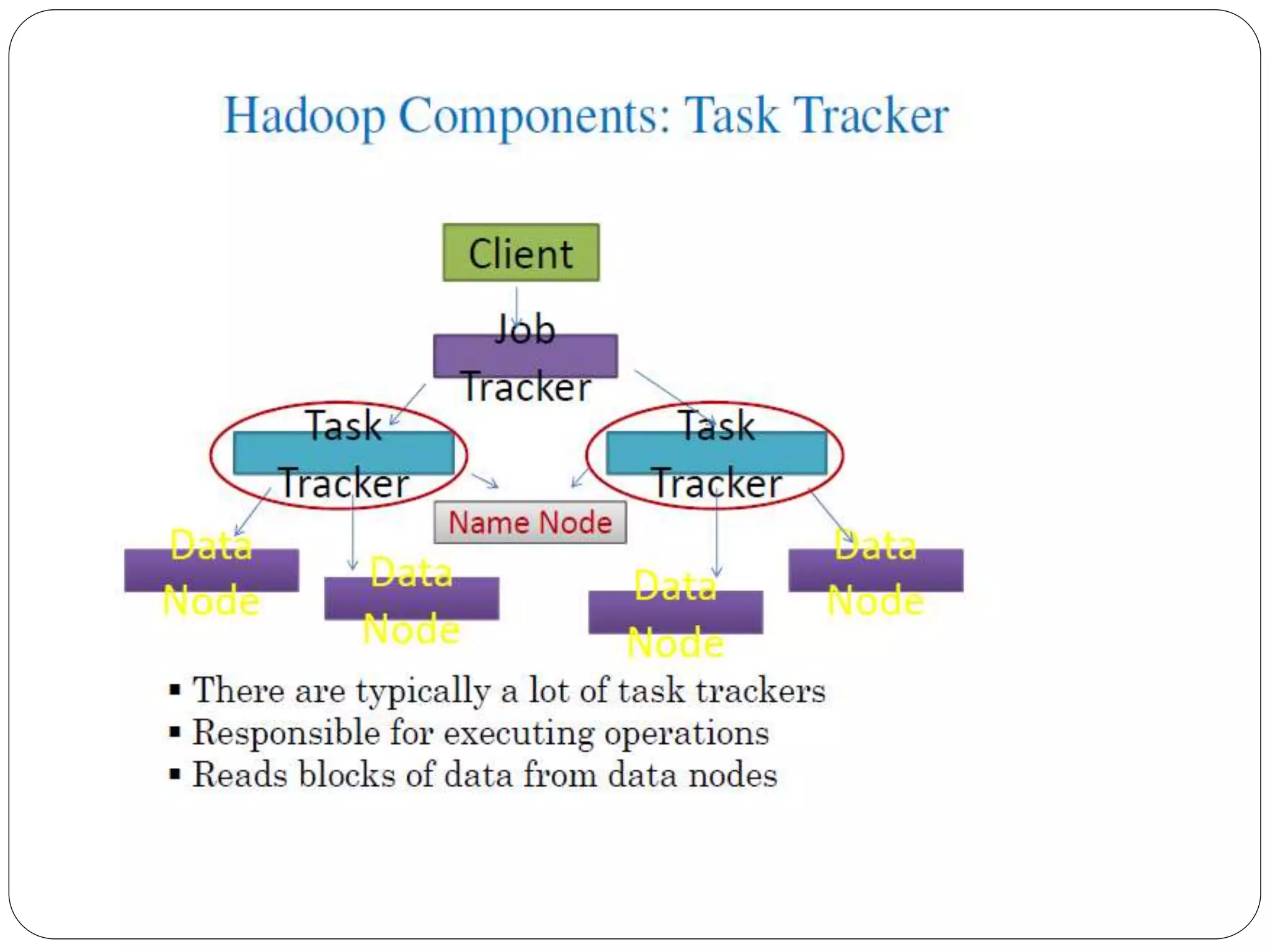
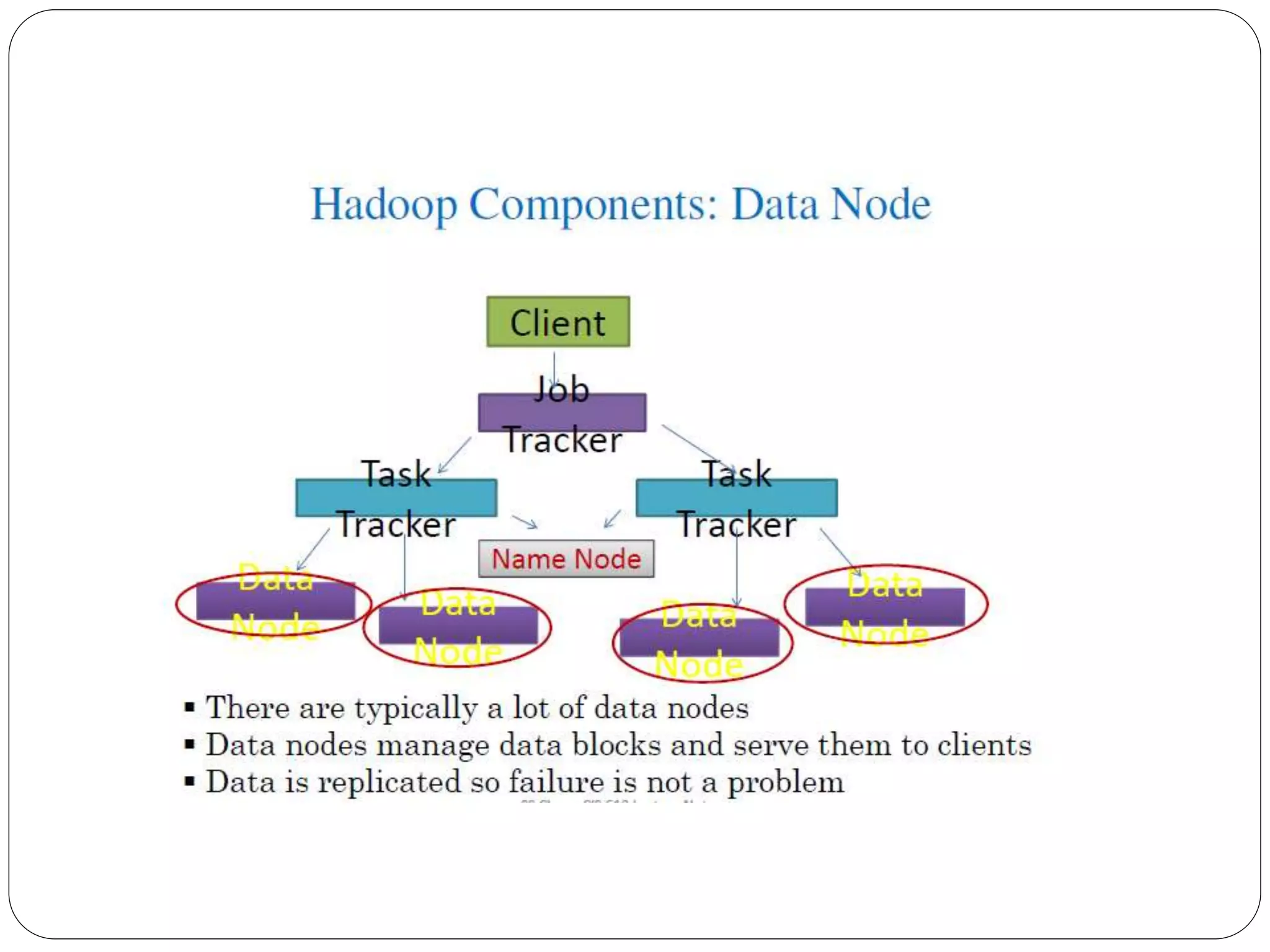

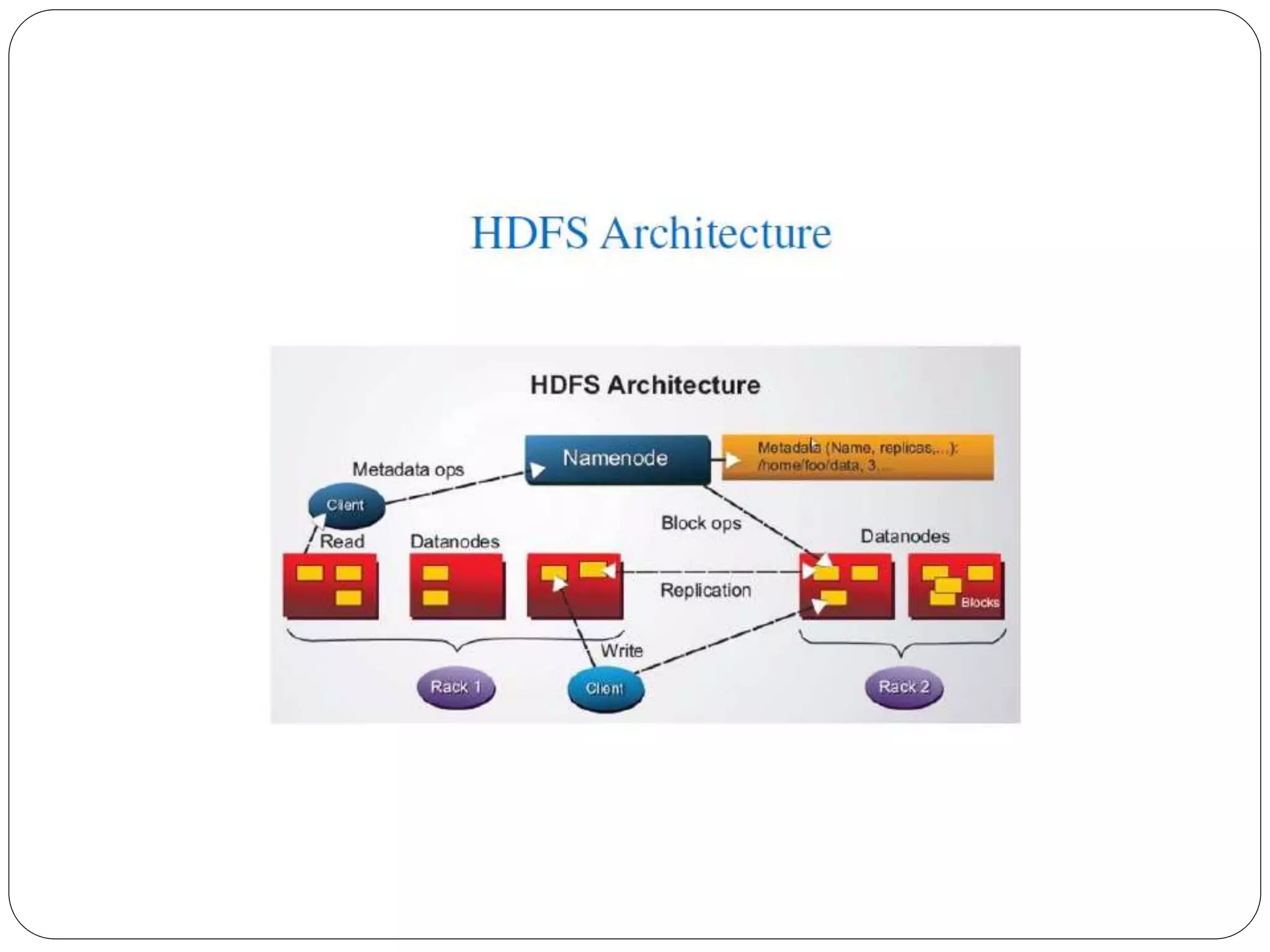

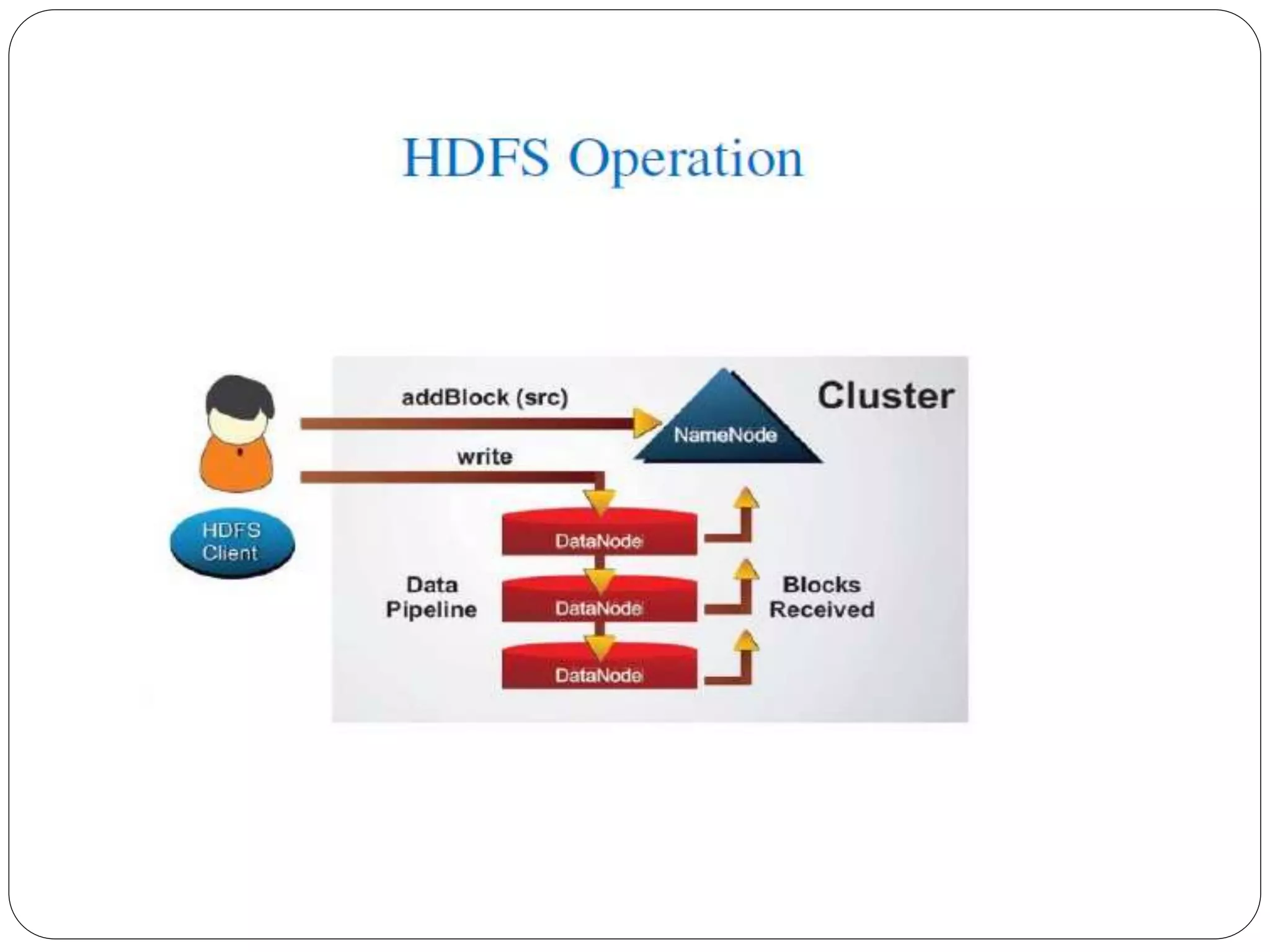


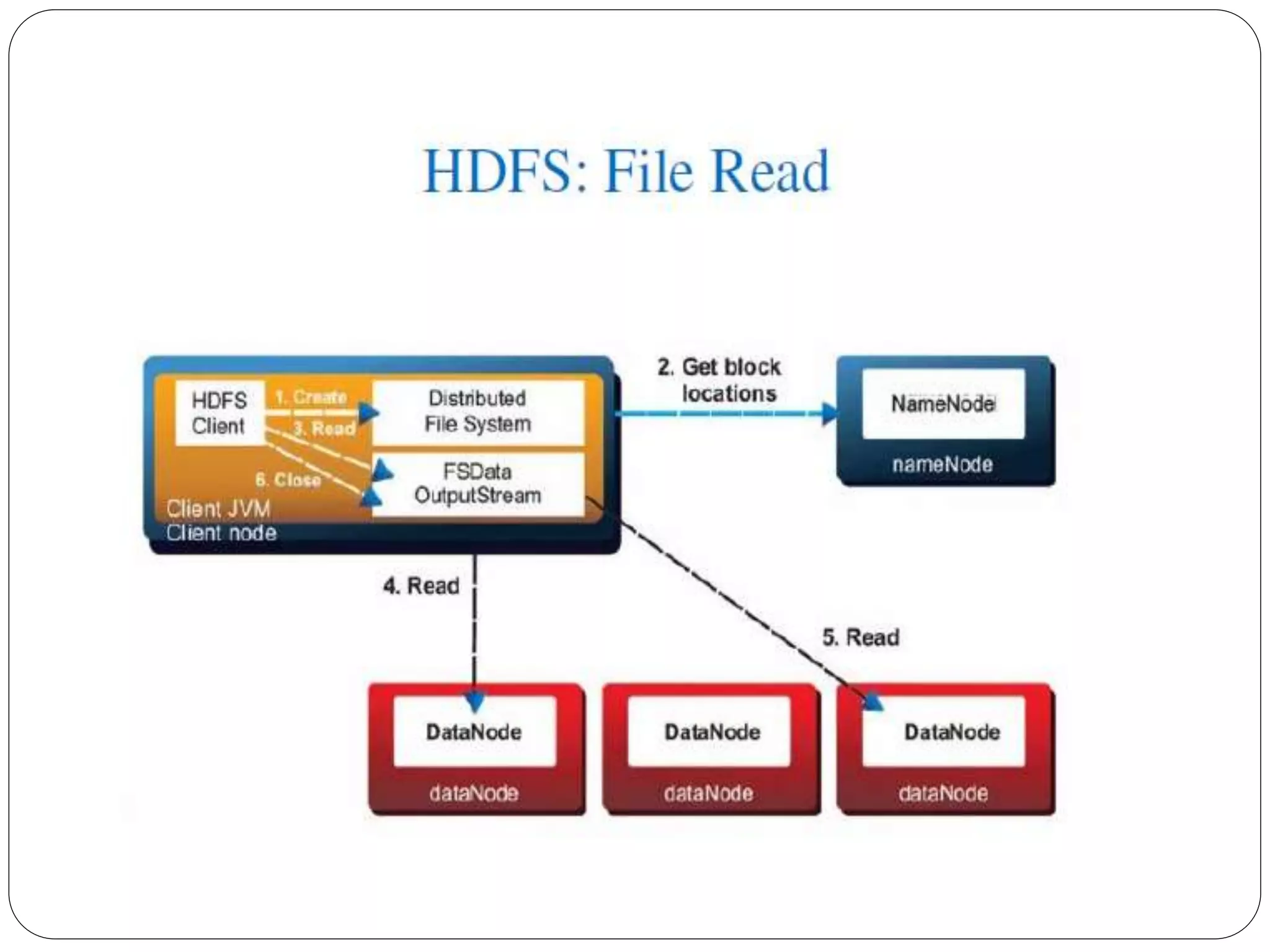
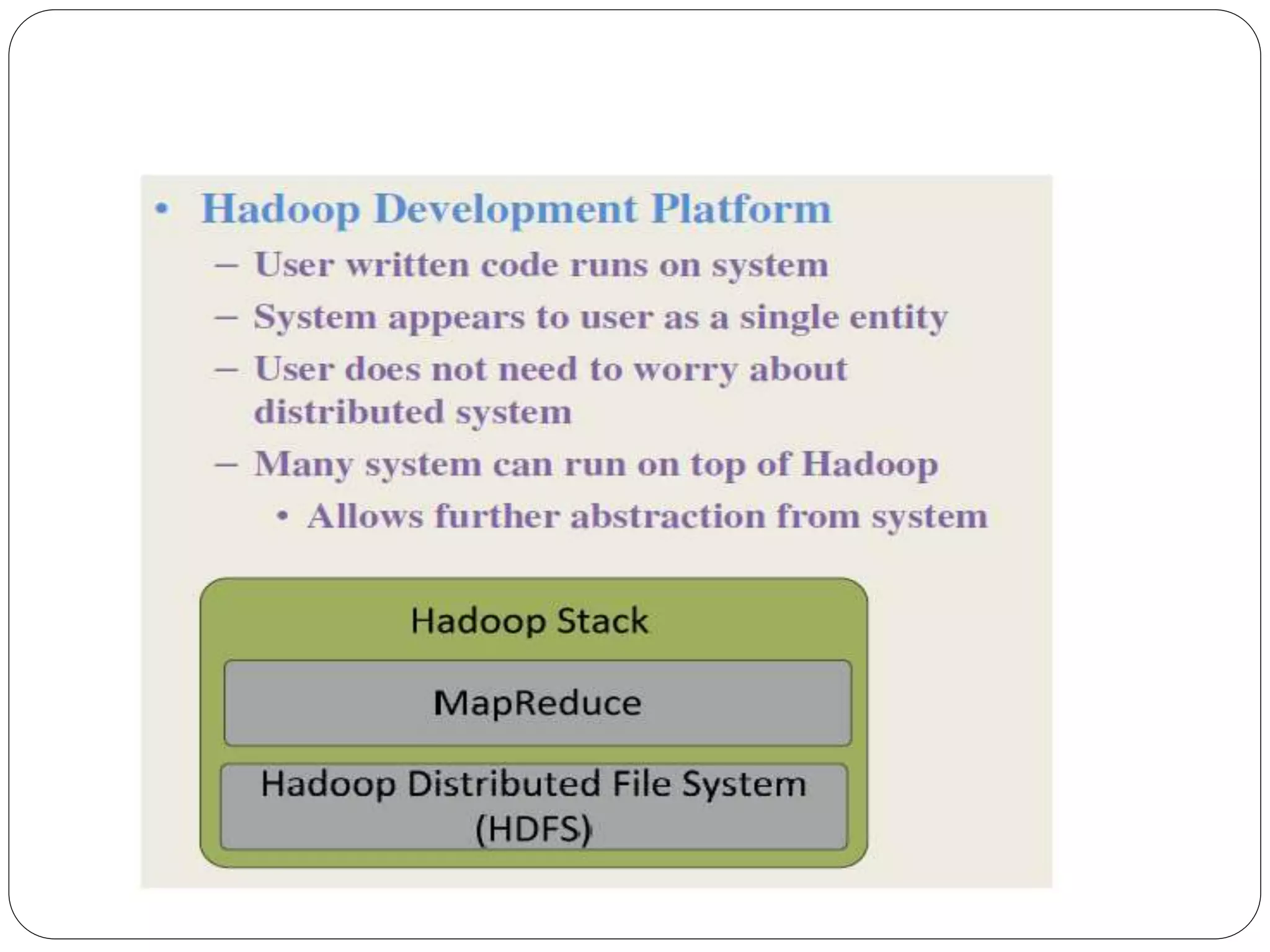
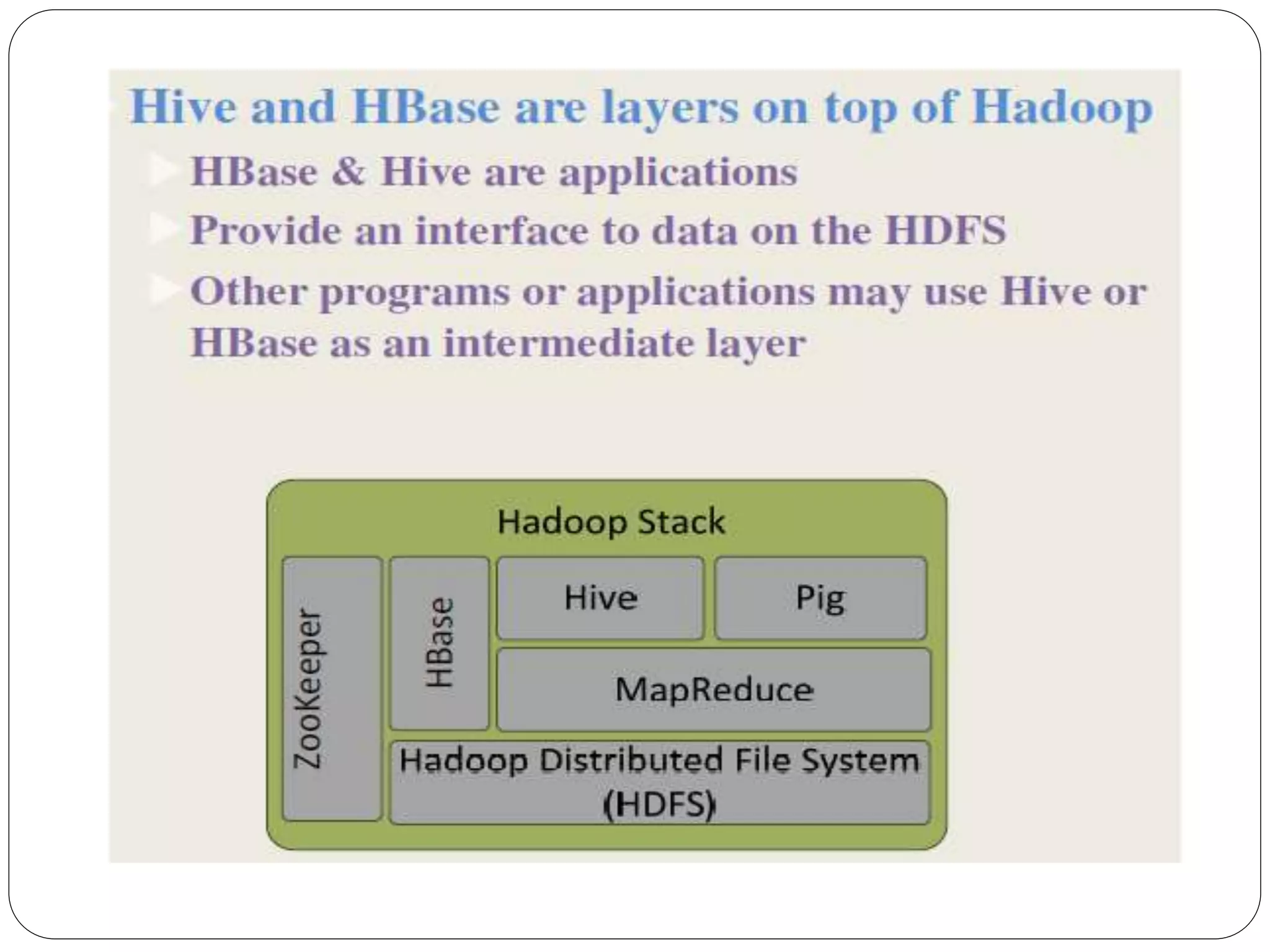







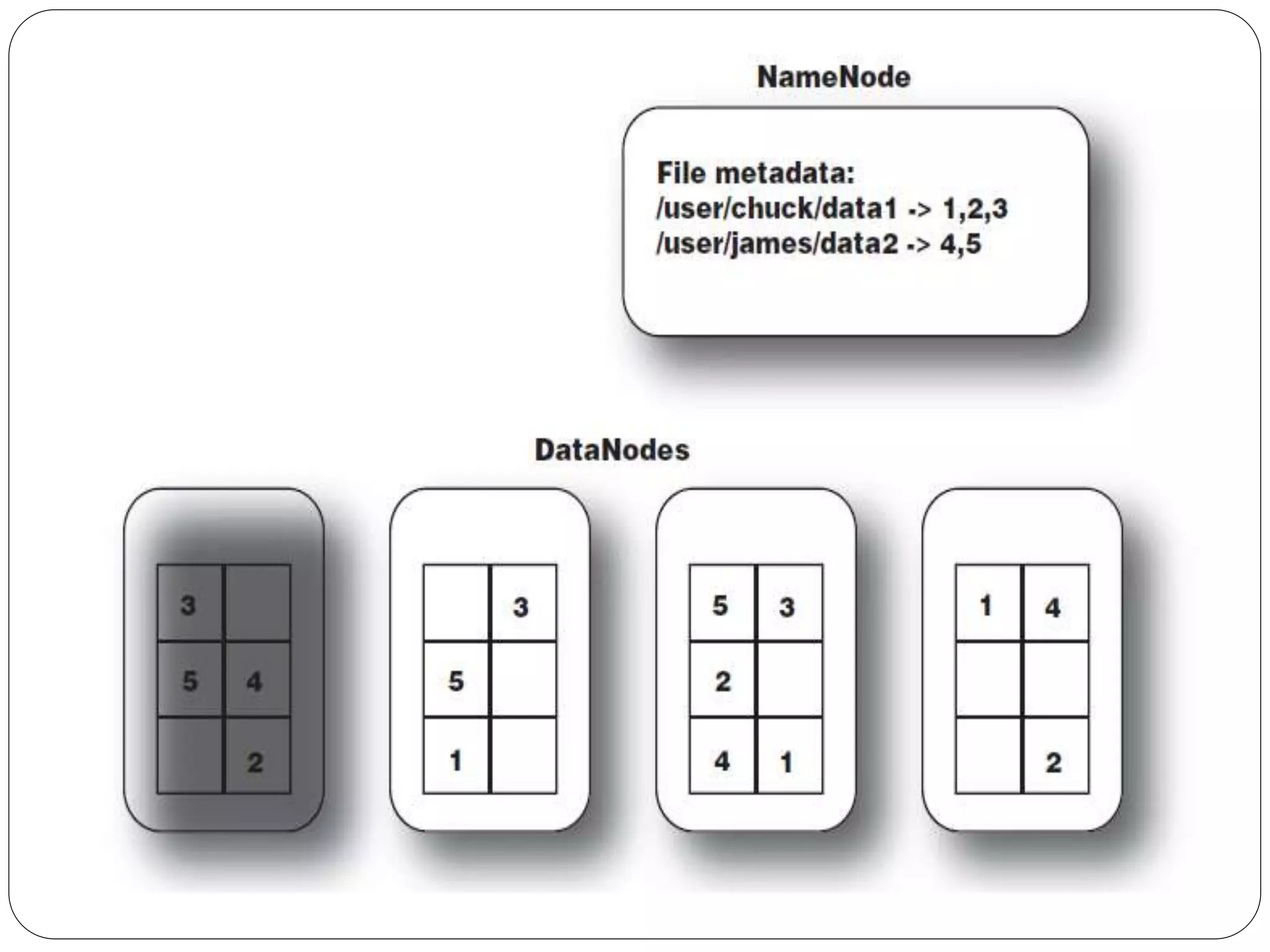


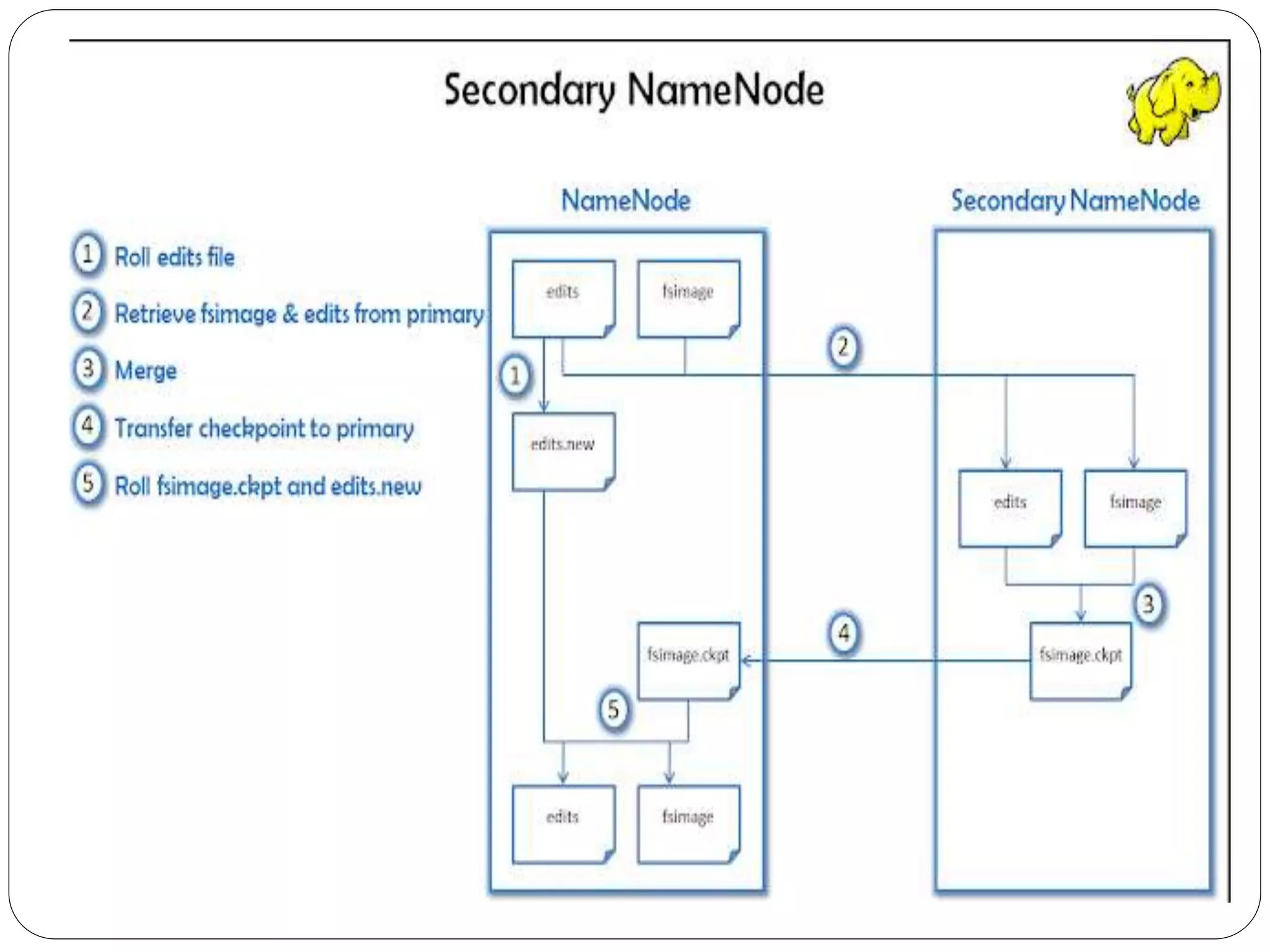



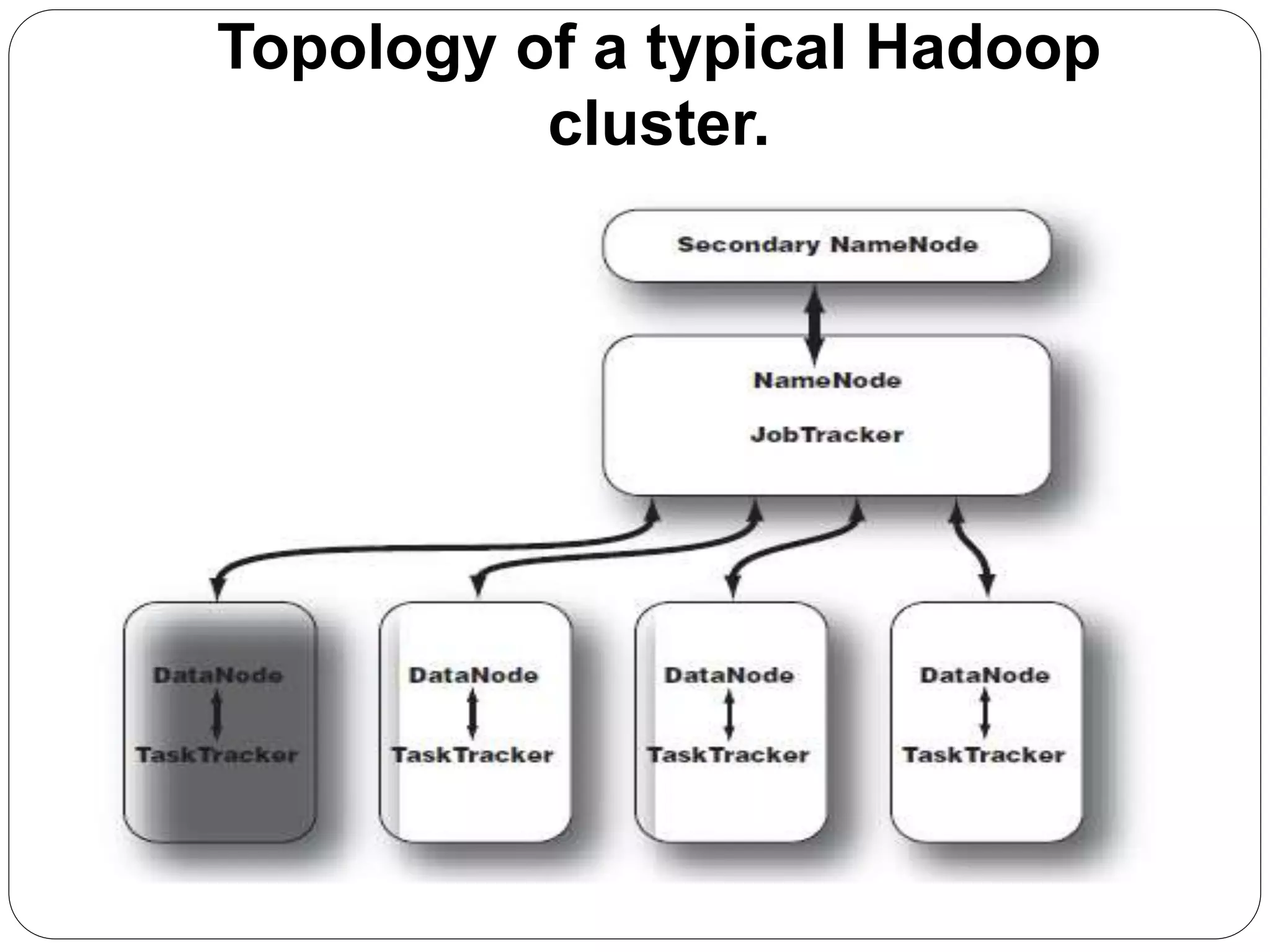

The document provides an introduction to big data, including definitions and characteristics. It discusses how big data can be described by its volume, variety, and velocity. It notes that big data is large and complex data that is difficult to process using traditional data management tools. Common sources of big data include social media, sensors, and scientific instruments. Challenges in big data include capturing, storing, analyzing, and visualizing large and diverse datasets that are generated quickly. Distributed file systems and technologies like Hadoop are well-suited for processing big data.






















![What the [bleep] is "The Cloud'?](https://cdn.slidesharecdn.com/ss_thumbnails/thecloudpresentation-120202081923-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






























































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)

