Download as PDF, PPTX





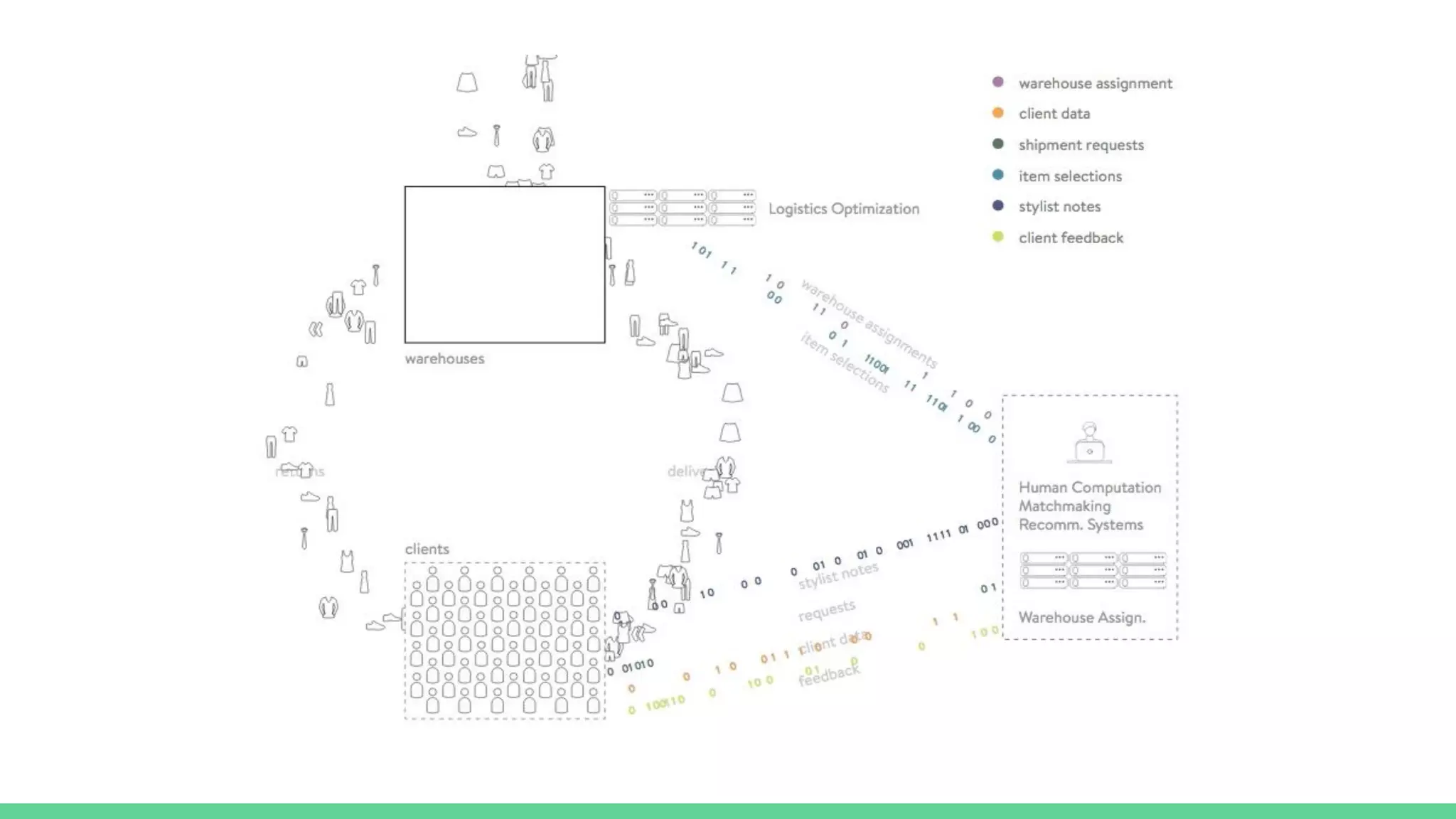



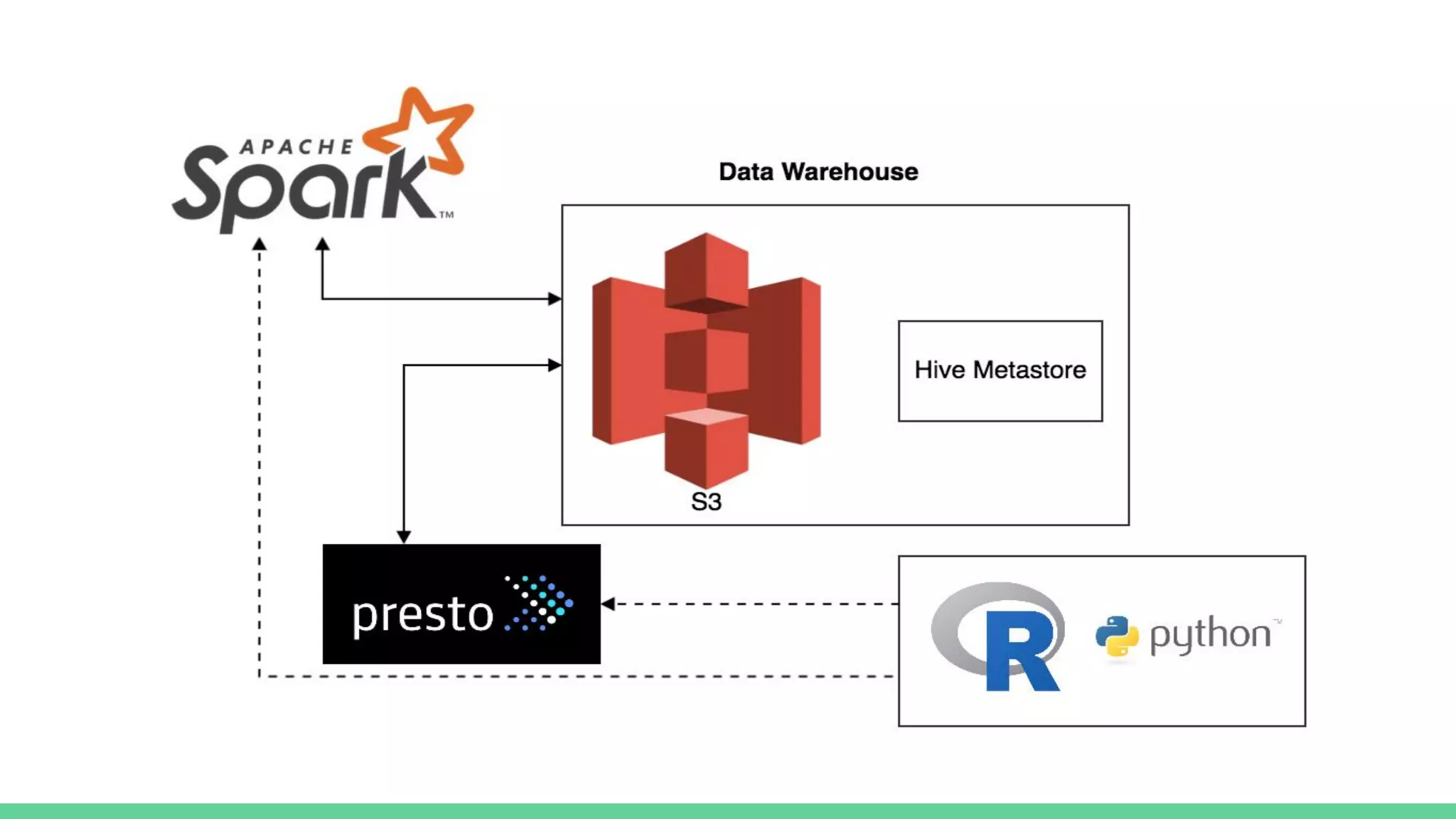



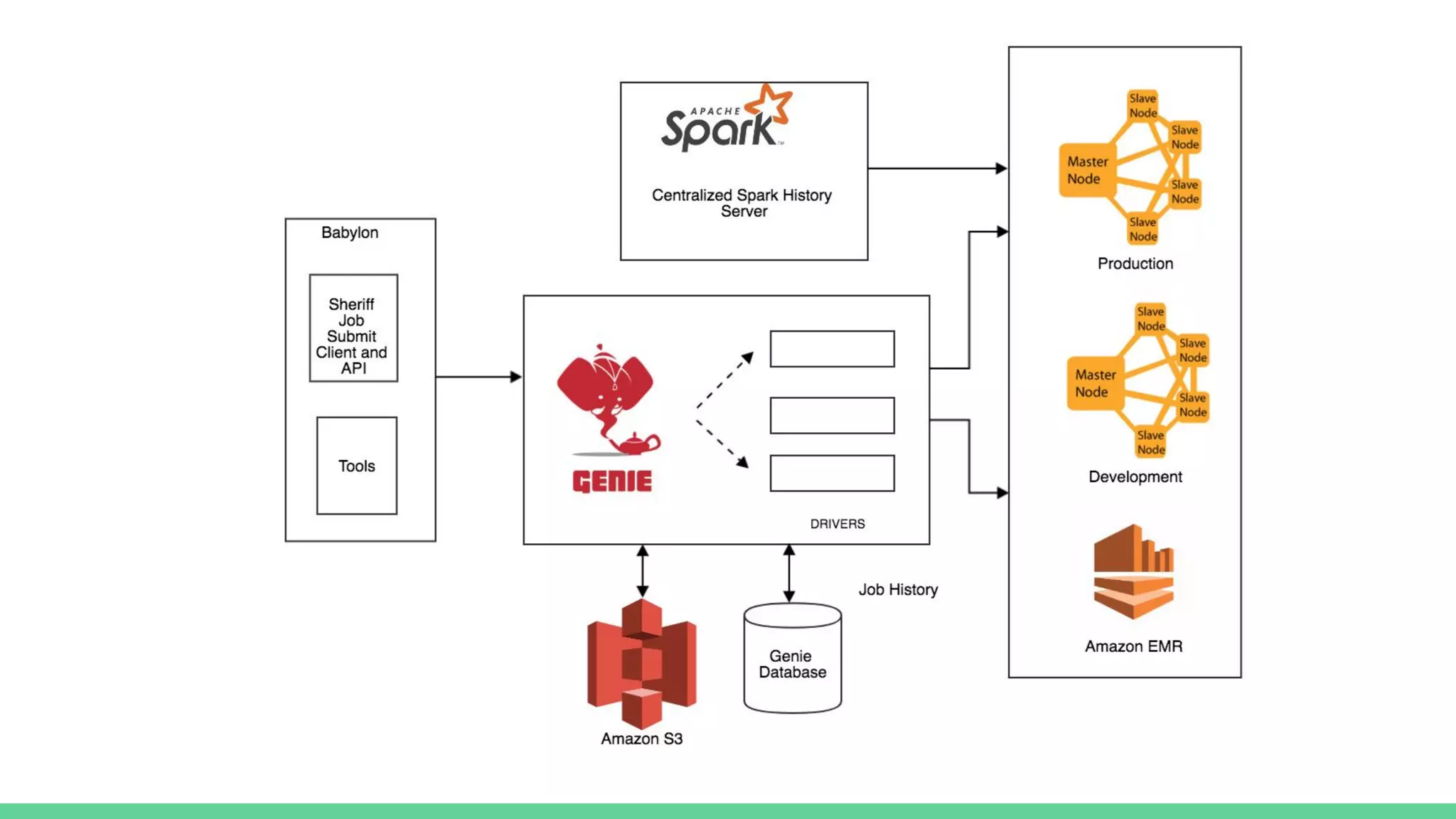

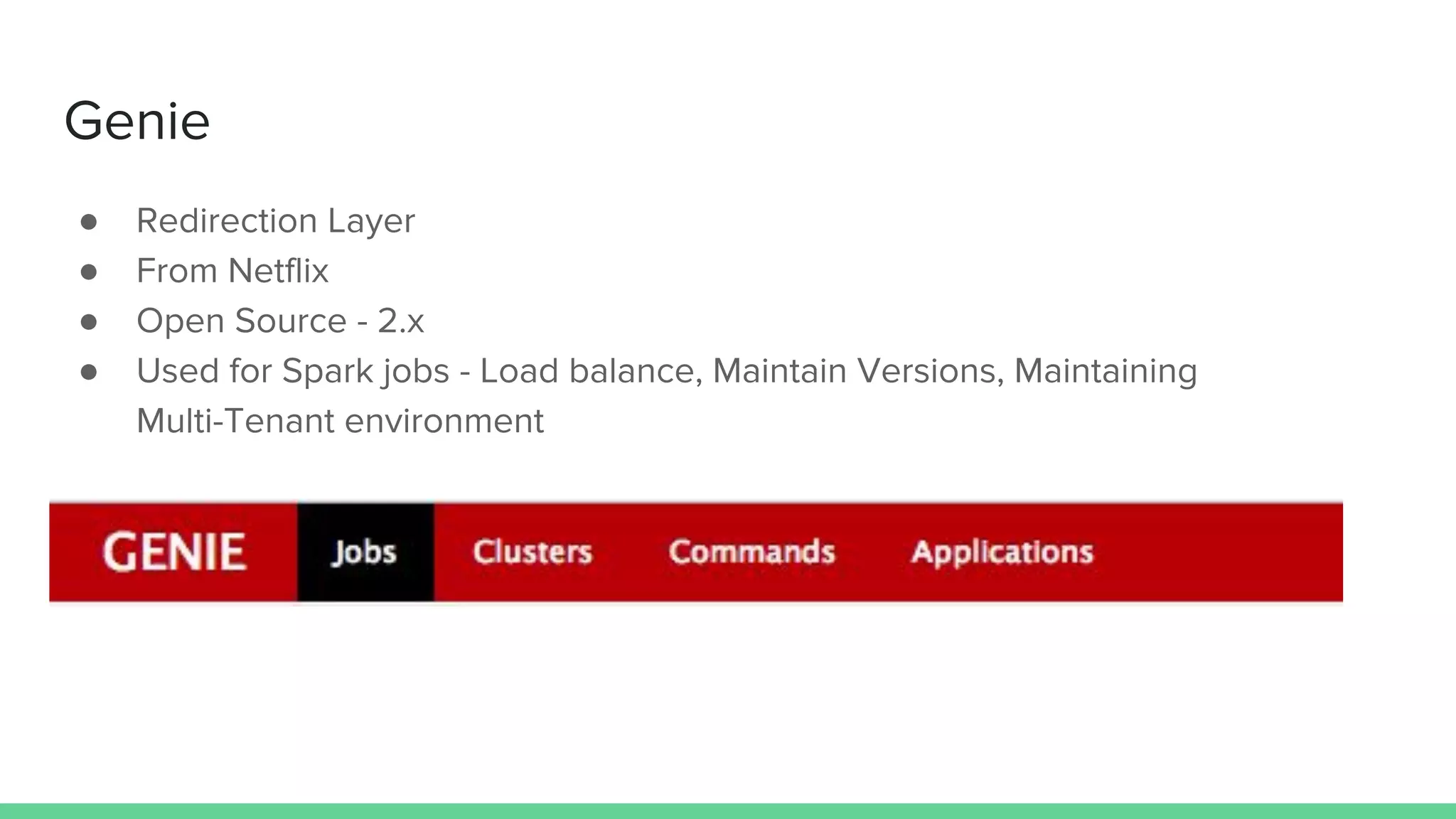



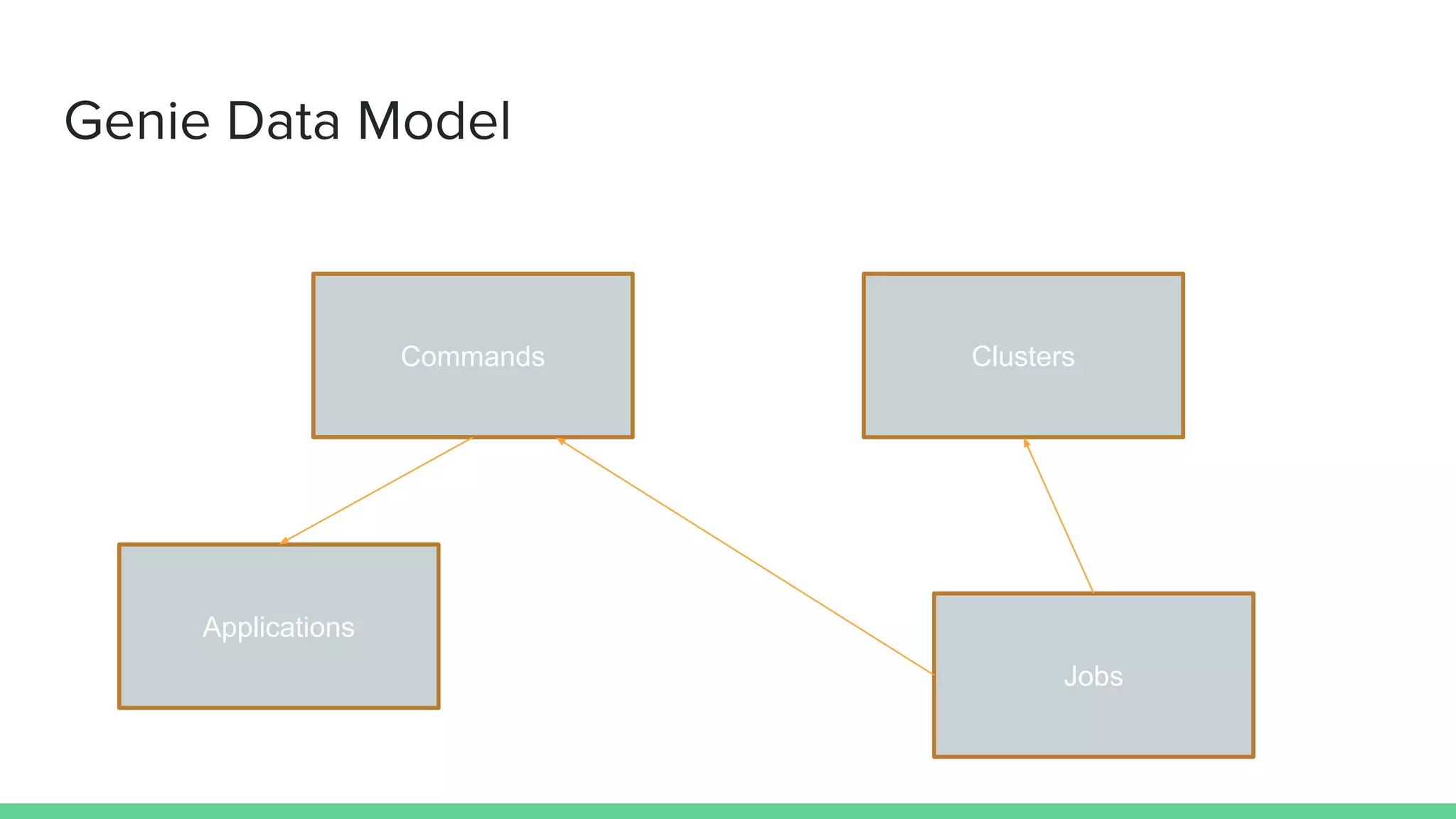






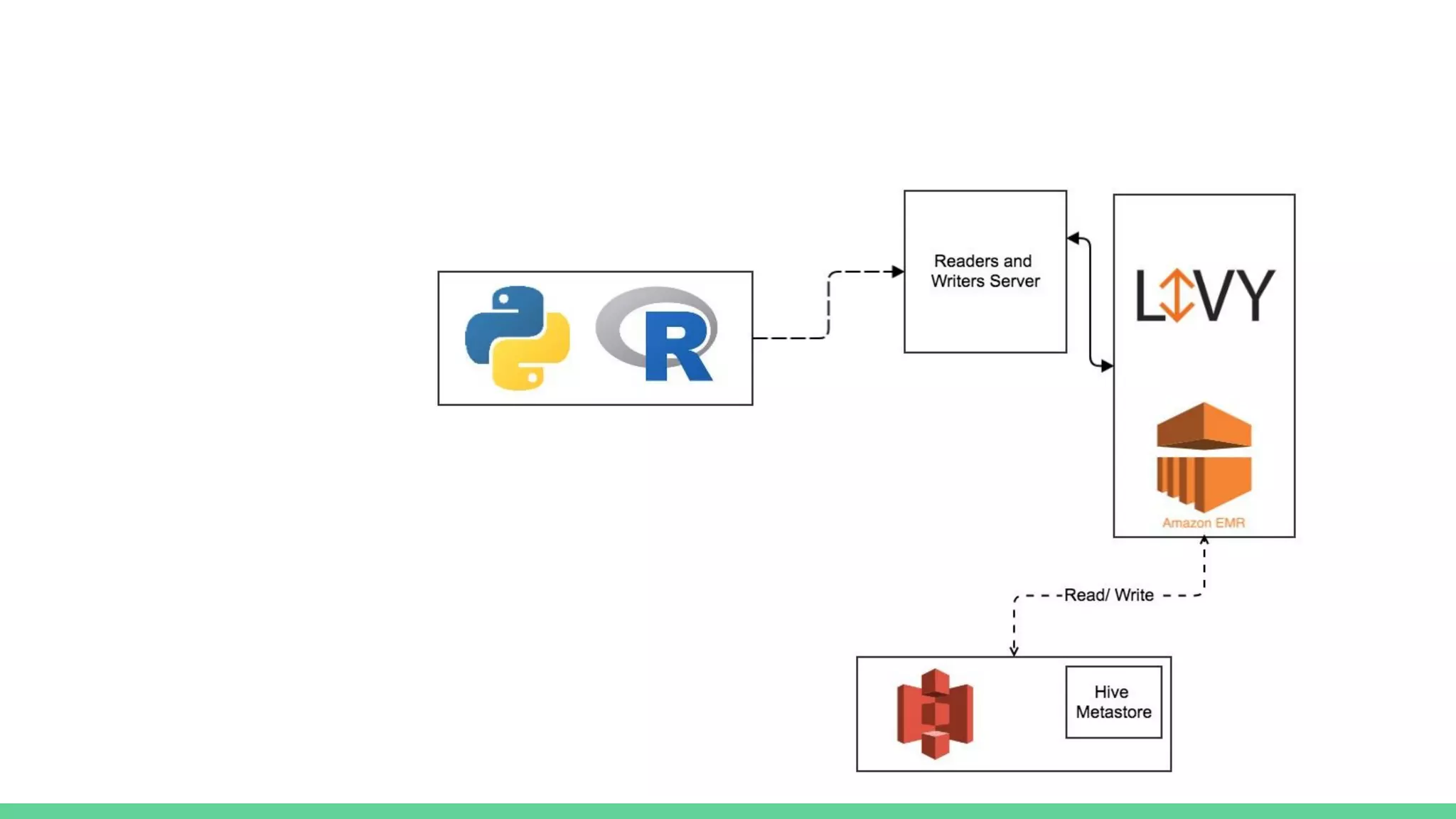


The document discusses the compute infrastructure at Stitch Fix, emphasizing the integration of algorithms and data science in their operations since 2011. It outlines the components of the data warehouse, the utilization of Spark and Genie for managing jobs and workloads, and the training needs for data scientists. Additionally, it highlights the importance of tools for data access and processing, such as Python and R clients, and the centralized Spark history server called Spaceman.









































































