Downloaded 25 times








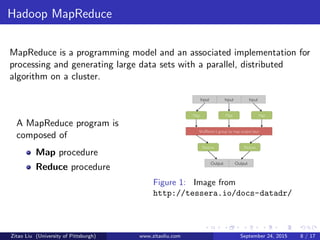

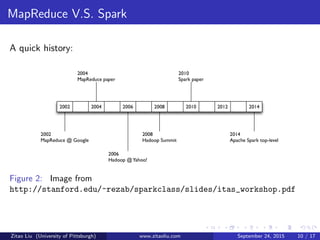



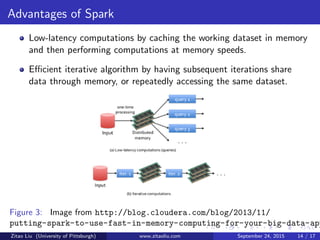




The document discusses Hadoop and Spark frameworks for big data analytics. It describes that Hadoop consists of HDFS for distributed storage and MapReduce for distributed processing. Spark is faster than MapReduce for iterative algorithms and interactive queries since it keeps data in-memory. While MapReduce is best for one-pass batch jobs, Spark performs better for iterative jobs that require multiple passes over datasets.































![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






