Download as PDF, PPTX






















![Defining Features
● Each word: one-hot vector
● I = [0, 0, 0, 1, 0, 0, 0, …, 0]
● like = [1, 0, 0, 0, 0, 0, 0, …, 0]
● cookies = [0, 0, 0, 0, 0, 0, 1, …, 0]
● Number of dimensions = size of vocabulary
● Document: bag of words
● Order of words is lost
● Count of words can be added
● Term frequency / inverse document frequency
"I like cookies" = [1, 0, 0, 1, 0, 0, 1, …, 0]](https://image.slidesharecdn.com/20150122-sentiment-150521210911-lva1-app6891/85/Sentiment-Analysis-26-320.jpg)
![Feature Engineering
● Ngrams (as one-hot)
● I, like, cookies - unigrams
● “I like” = [0, 0, 0, 0, 1, 0, …, 0] - bigrams
● “I like cookies” - trigrams
● Character n-grams:
● li, ik, ke, lik, ike
● Dictionaries:
● Great value for sentiment analysis
● Very good for domain specific text
If document contains any of:
{love, like, good, cool}
add this one: [0, 0, 1, 0, …, 0]](https://image.slidesharecdn.com/20150122-sentiment-150521210911-lva1-app6891/85/Sentiment-Analysis-27-320.jpg)






![Still not convinced?
● Context issues
● Narrowing the domain helps
● “beer is cool”, “soup is cool”
● “No babies yet!” - condoms / fertility drugs
● “Obama goes full Bush on Syria”
● User generated content SUCKS!
● “Polynesian sauce from chik fila a be so bomb”
● Common sense
“I tried the banana slicer and found it unacceptable. […] the
slicer is curved from left to right. All of my bananas are bent
the other way.”](https://image.slidesharecdn.com/20150122-sentiment-150521210911-lva1-app6891/85/Sentiment-Analysis-34-320.jpg)






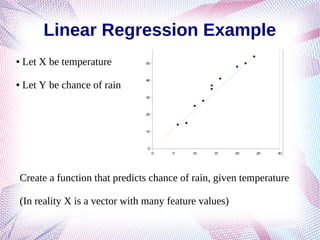
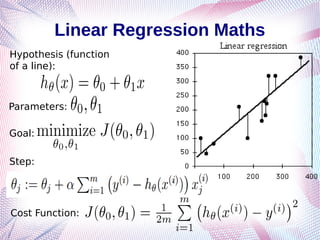
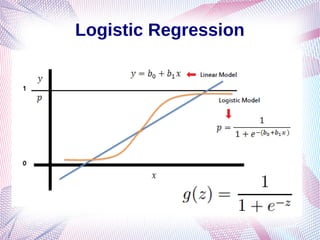
The document explores Natural Language Processing (NLP) and its applications, particularly focusing on text classification and sentiment analysis using supervised machine learning techniques. It covers topics such as feature engineering, linear and logistic regression, and challenges faced in sentiment analysis like context issues and annotation guidelines. Additionally, the document discusses various methods for classifying text, including one-hot encoding and advanced word embeddings.




































































![[Data Meetup] Data Science in Finance - Factor Models in Finance](https://cdn.slidesharecdn.com/ss_thumbnails/factormodelsinfinance-metodinikolov-191009091837-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Data Meetup] Data Science in Finance - Building a Quant ML pipeline](https://cdn.slidesharecdn.com/ss_thumbnails/buildingaquantmlpipeline-191009091209-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Data Meetup] Data Science in Journalism - Tanbih, QCRI and MIT](https://cdn.slidesharecdn.com/ss_thumbnails/dsspreslavnakov2019-08-222-190901181352-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)