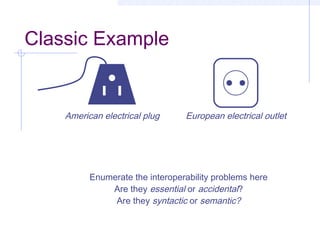
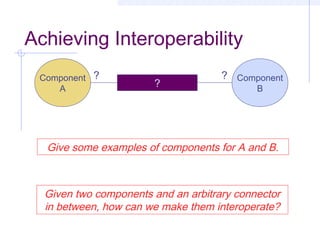
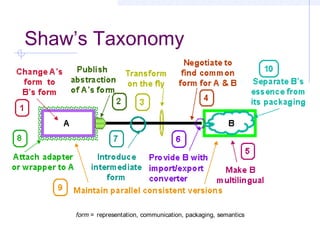
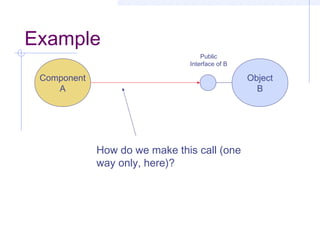
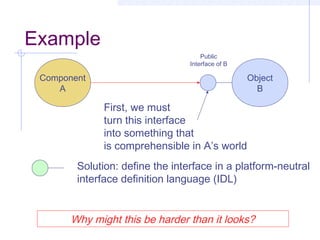
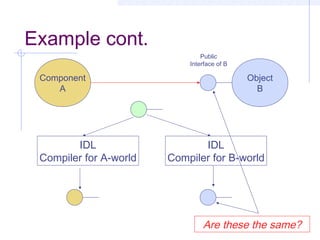
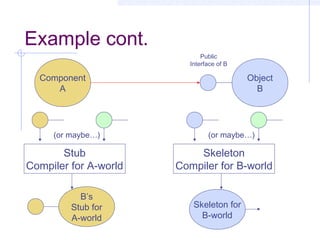
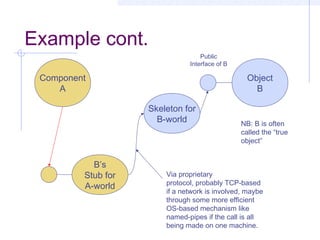
This document discusses interoperability between software components. It defines interoperability as the ability of independently developed components to interact meaningfully by communicating and exchanging data or services. Achieving interoperability is challenging due to heterogeneity between components in terms of programming languages, platforms, data formats, and assumptions. Common Object Request Broker Architecture (CORBA) and XML are examined as approaches to enabling interoperability, but both make assumptions that can limit their effectiveness and even introduce new interoperability issues in some cases. Shaw's taxonomy of interoperability solutions is also referenced.






![Another Characterization
Architectural Mismatch [GAO95]
Components have difficulty interoperating because
of mismatching assumptions
About the world they run in
About who is in control, and when
About data formats and how they’re manipulated
Also assumptions about connectors
About protocols (who says what when)
About data models (what is said)
Also assumptions about the global configuration
(topology)
…and the construction process (mostly
instantiation)](https://image.slidesharecdn.com/interoperability-150305002820-conversion-gate01/85/Interoperability-6-320.jpg)


















![What is XML?
From the spec:
Extensible Markup Language, abbreviated XML, describes a class
of data objects called XML documents and partially describes the
behavior of computer programs which process them. XML is an
application profile or restricted form of SGML, the Standard
Generalized Markup Language [ISO 8879]. By construction, XML
documents are conforming SGML documents.
XML documents are made up of storage units called entities, which
contain either parsed or unparsed data. Parsed data is made up of
characters, some of which form character data, and some of which
form markup. Markup encodes a description of the document's
storage layout and logical structure. XML provides a mechanism to
impose constraints on the storage layout and logical structure.
What assumptions are implicit in the W3C
discussion?](https://image.slidesharecdn.com/interoperability-150305002820-conversion-gate01/85/Interoperability-33-320.jpg)





































































