Download as PDF, PPTX



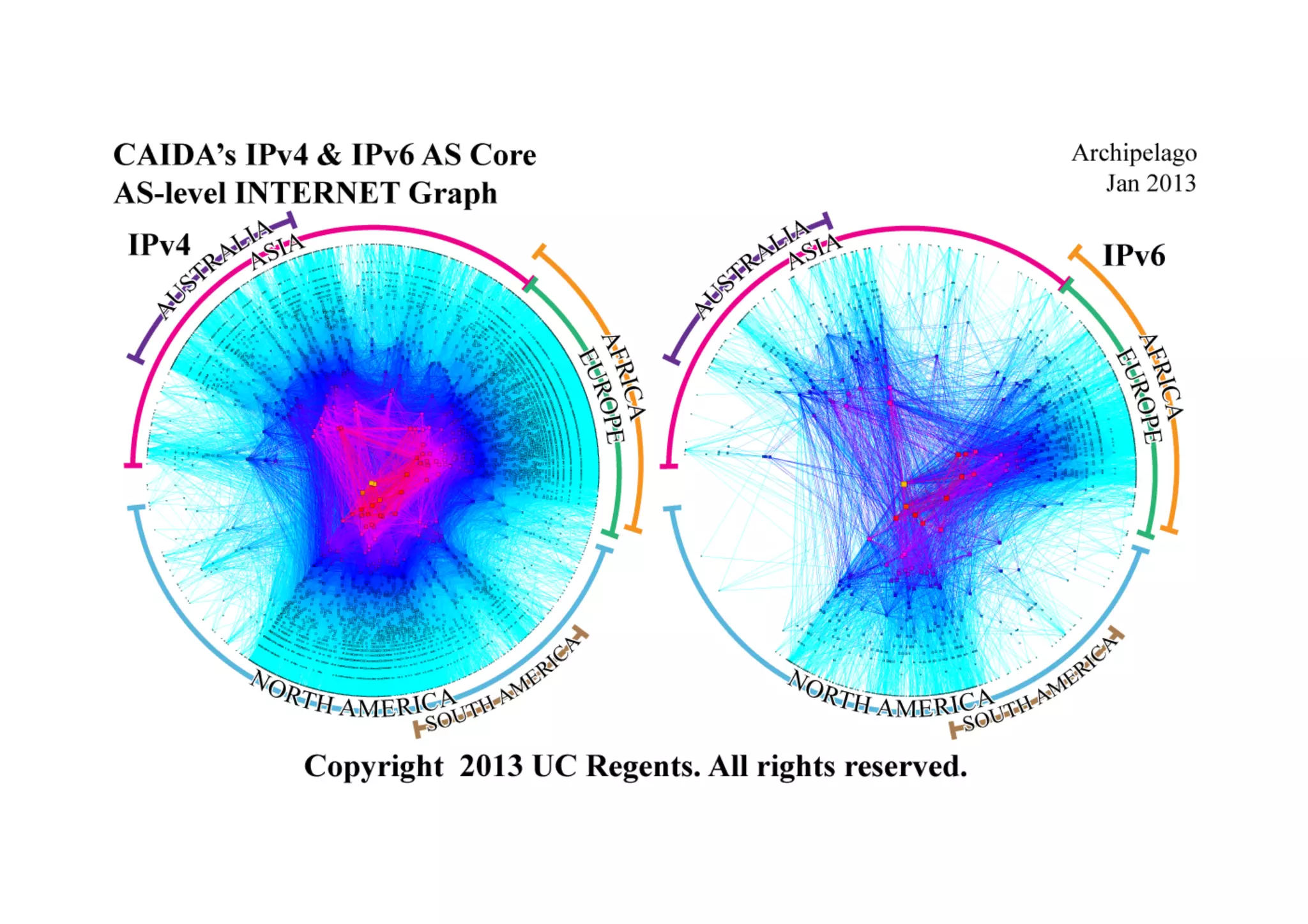

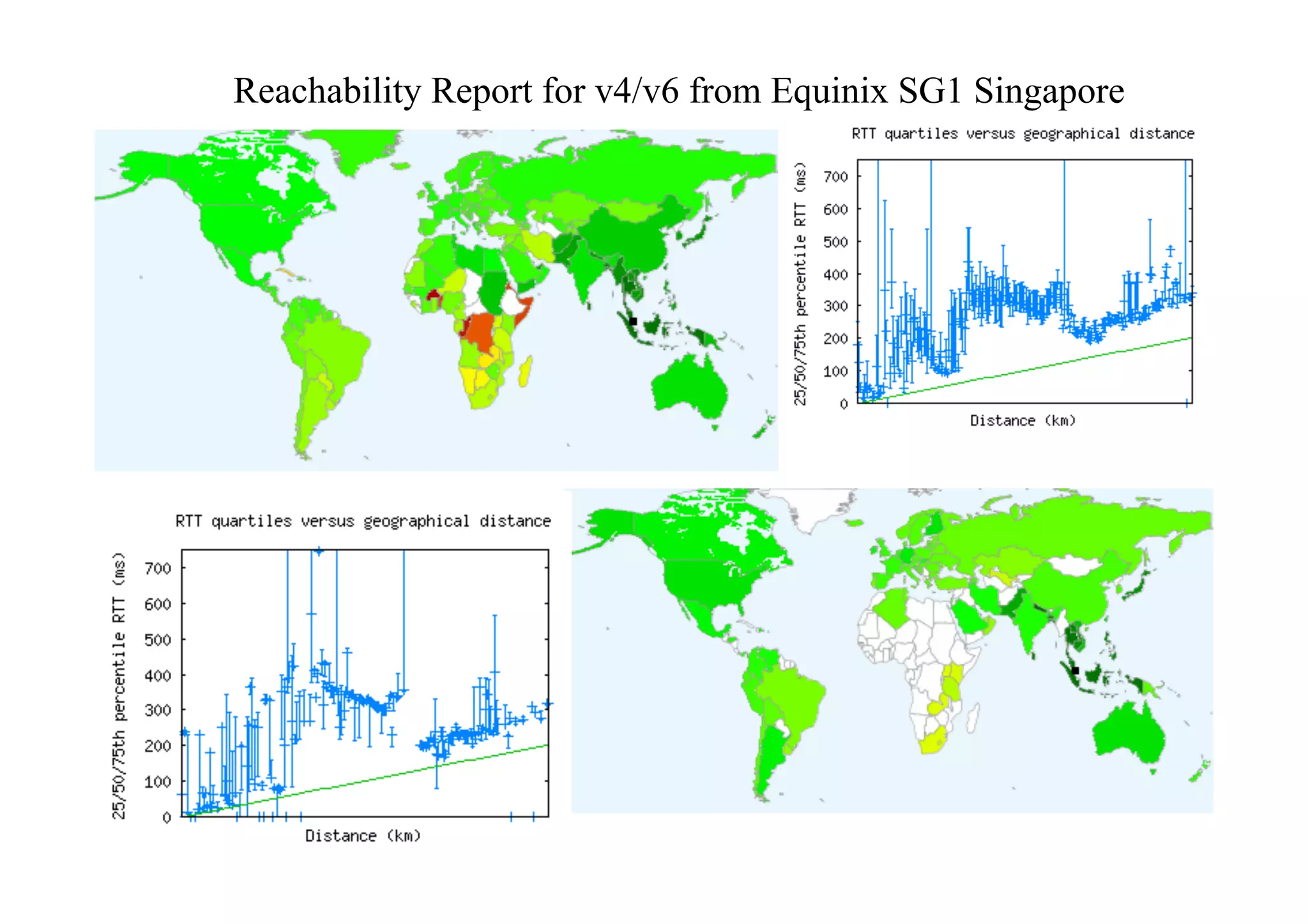
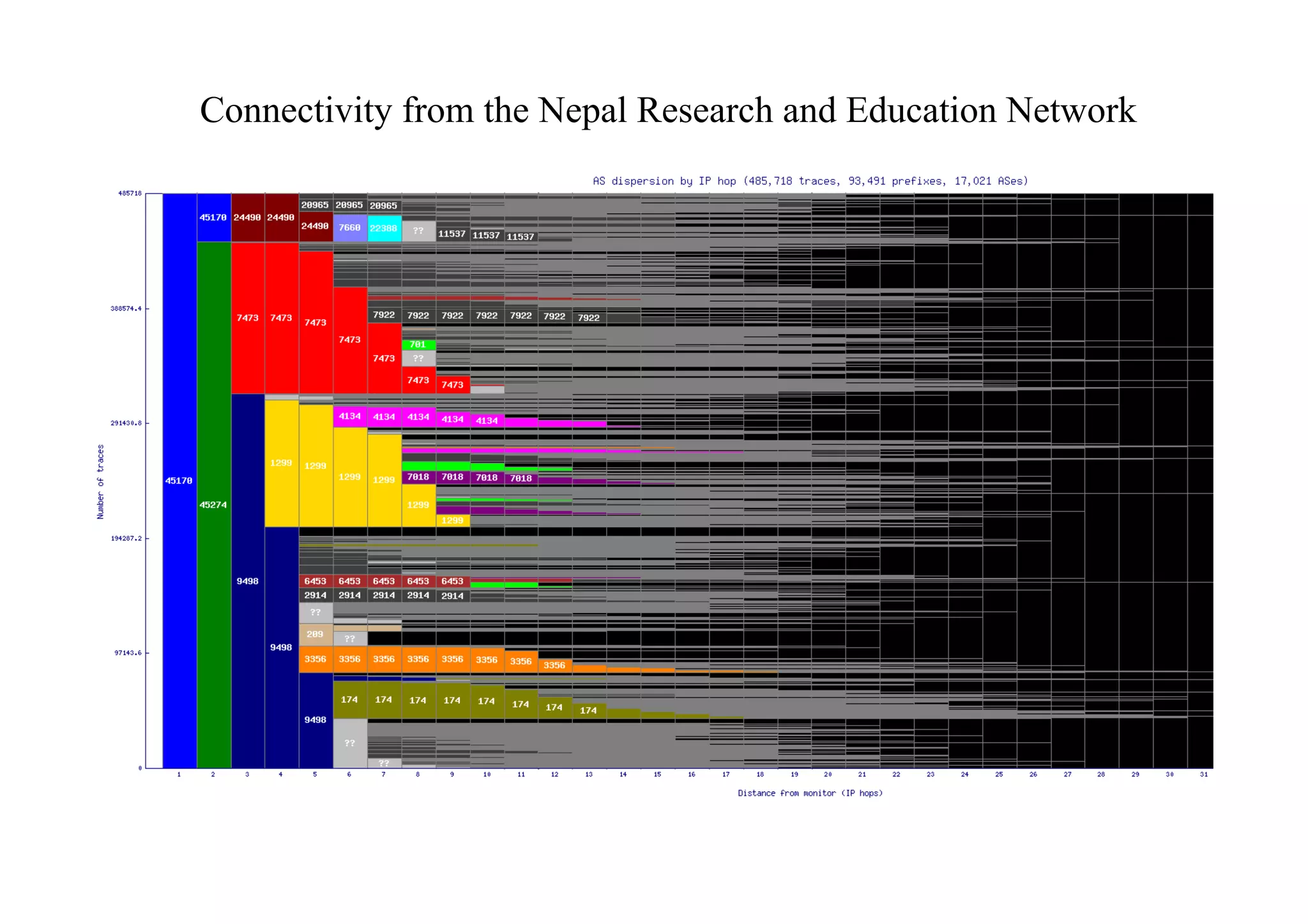
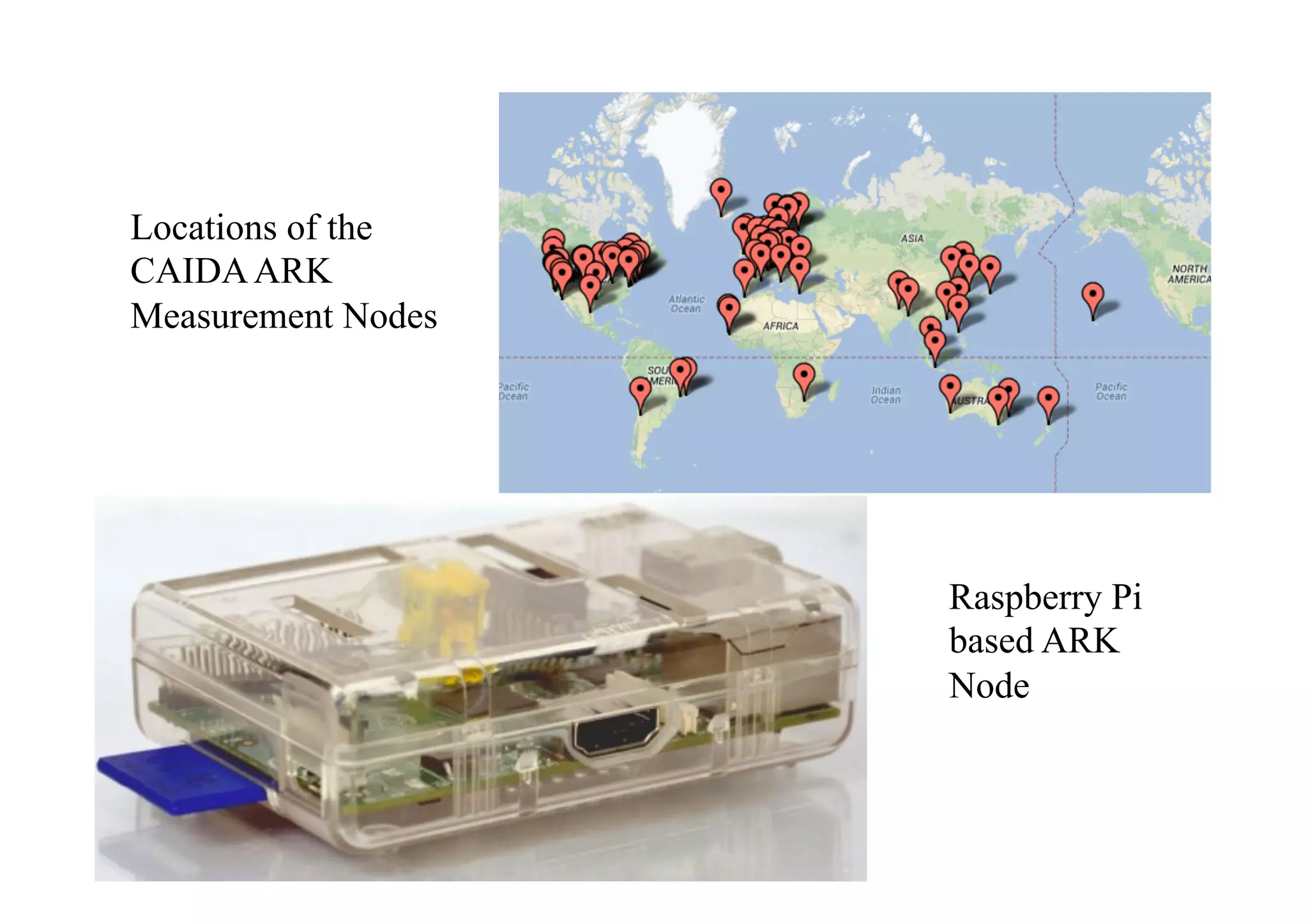


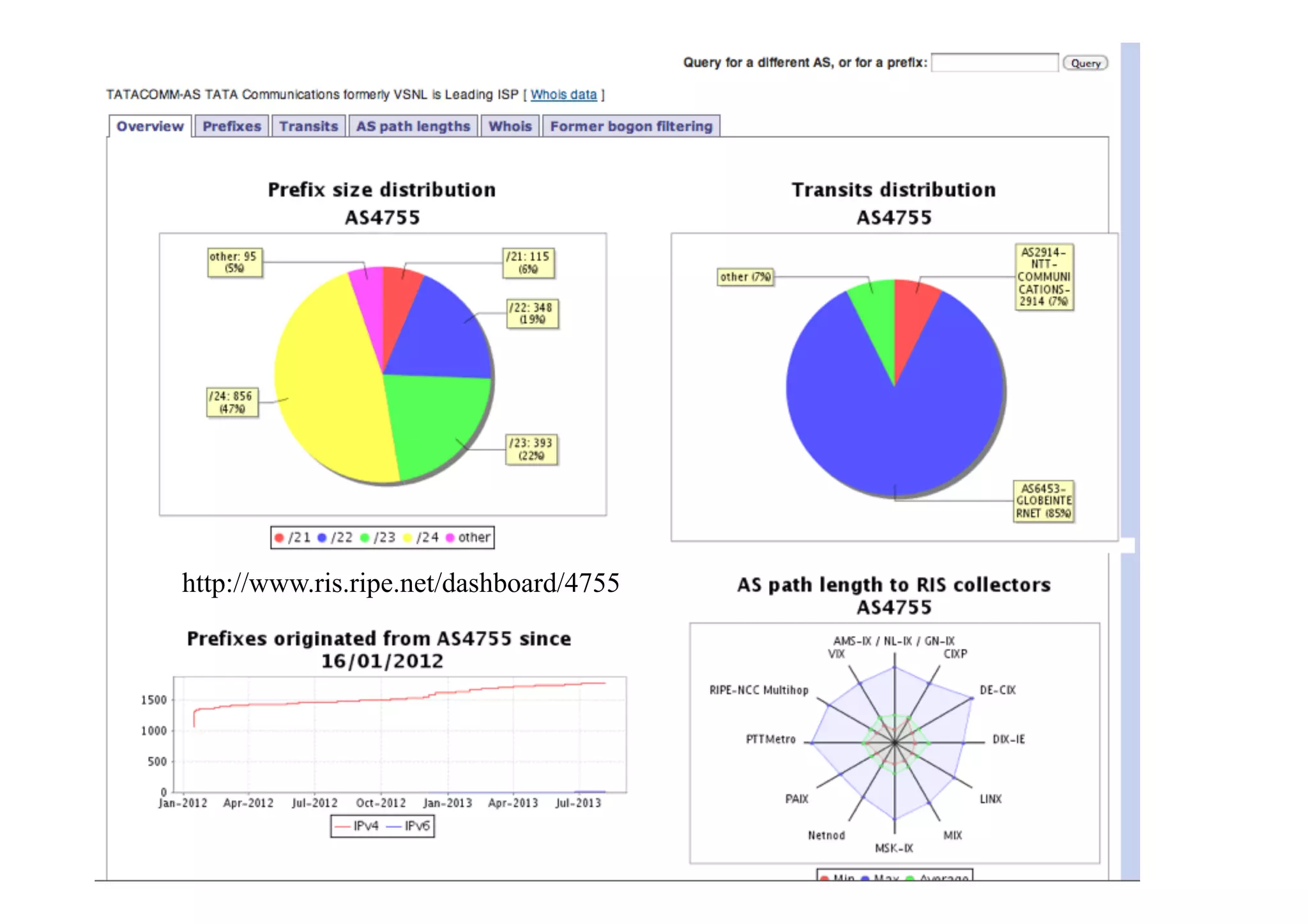


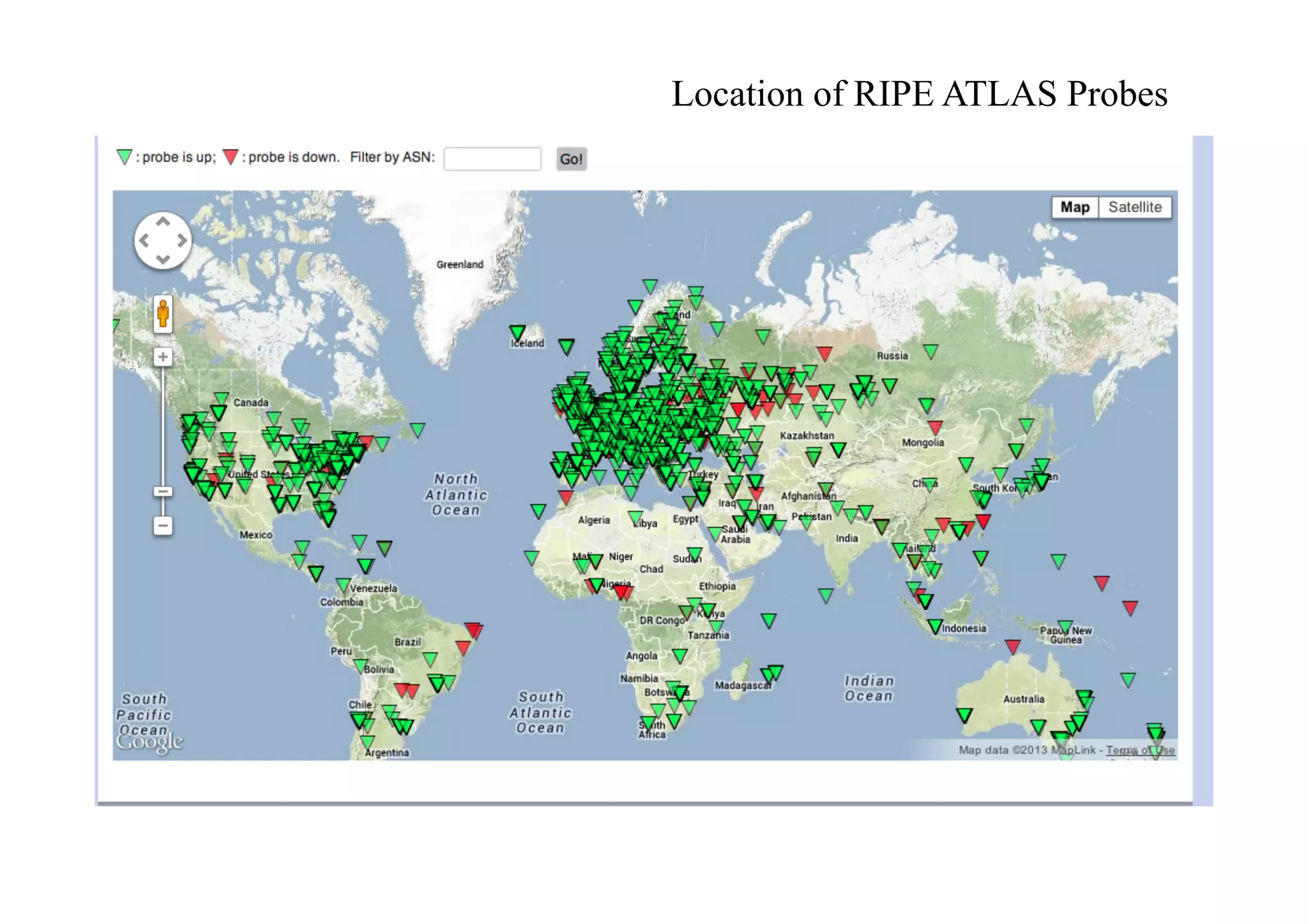


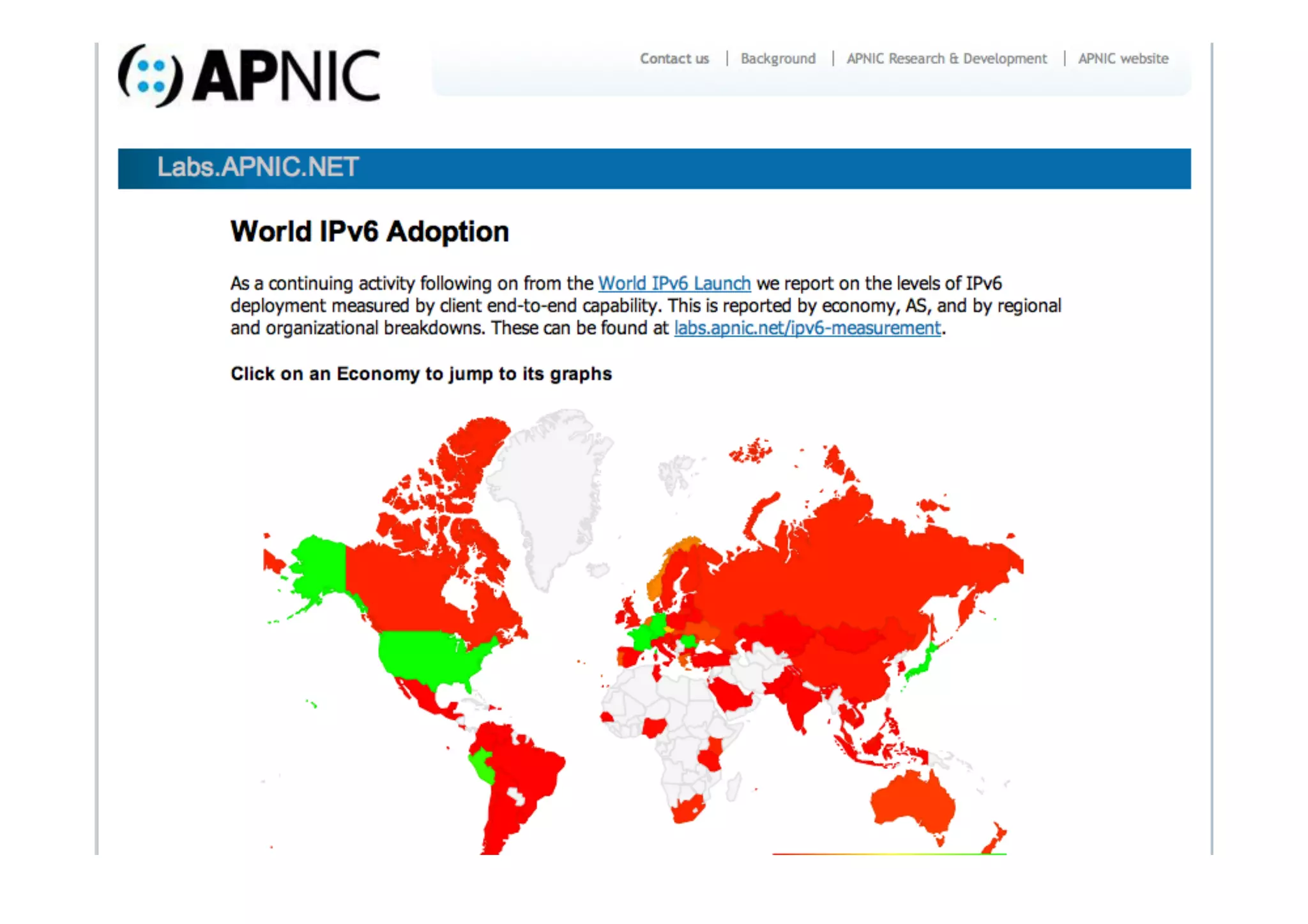

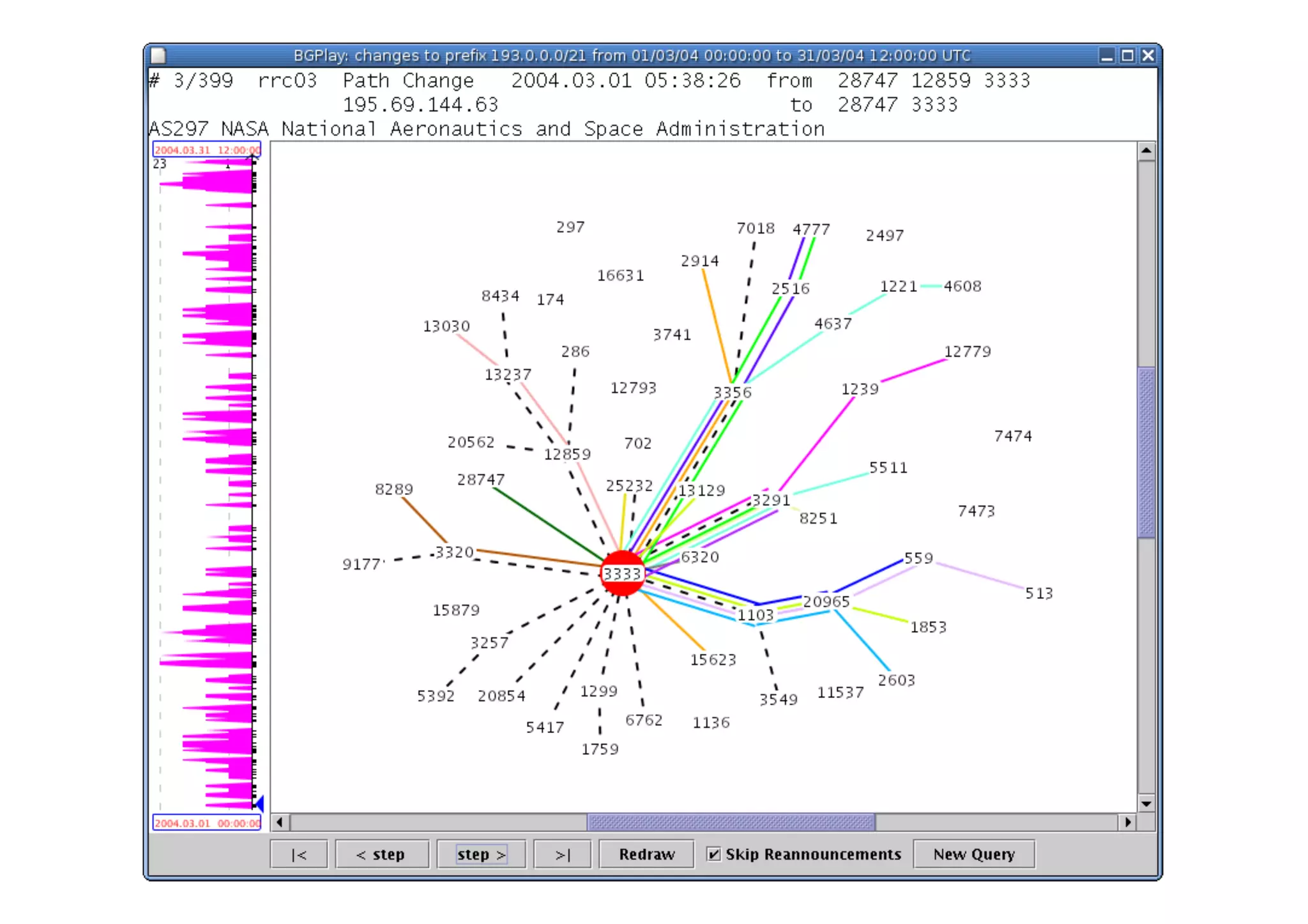


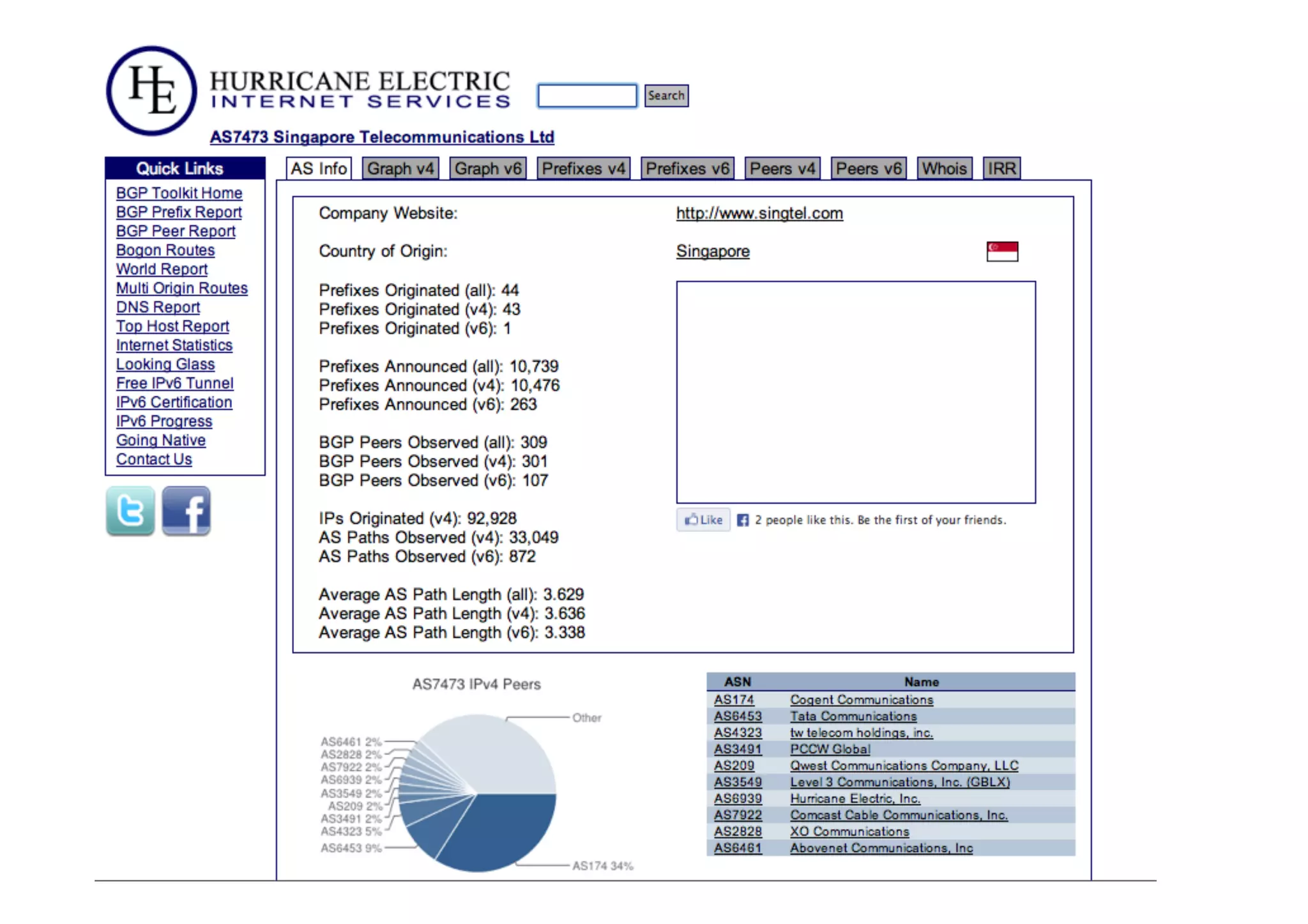
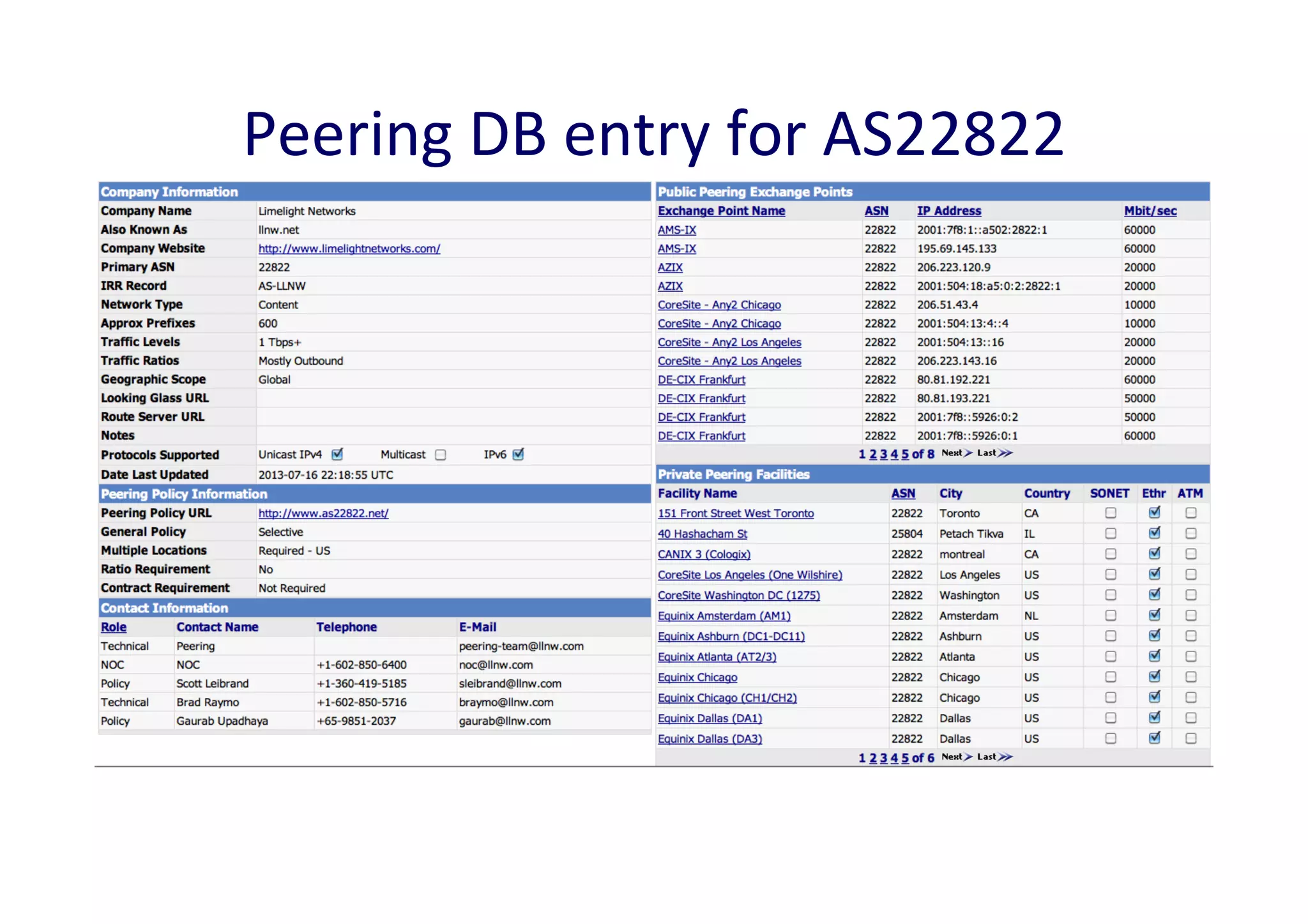





This document discusses various internet measurement tools and their usefulness for network engineers. It describes tools run by academic groups like CAIDA and RIPE, as well as community/industry tools like Routeviews, CIDR Report, and looking glasses. These tools provide continuous measurements of reachability, routing tables, latency, and BGP updates to help monitor and understand internet performance and stability.





















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
