
Downloaded 46 times




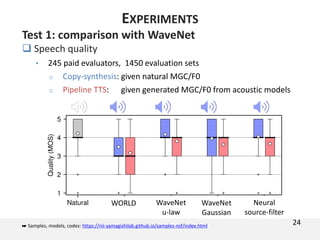
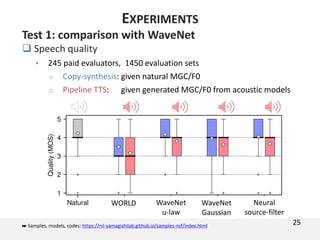
![Test 1: comparison with WaveNet
Data and feature
Models
23[1] Kawai, H., Toda, T., Ni, J., Tsuzaki, M., and Tokuda, K. (2004). Ximera: A new TTS from ATR based on corpus-based technologies. In Proc. SSW5, pages 179–184..
Corpus Size Note
ATR Ximera F009 [1] 15 hours 16kHz, Japanese, neutral style
Feature Dimension
Acoustic
Mel-generalized cepstrum coefficients (MGC) 60
F0 1
EXPERIMENTS](https://image.slidesharecdn.com/slp-l8-190521233946/85/Neural-source-filter-waveform-model-23-320.jpg)
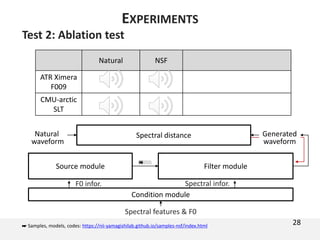
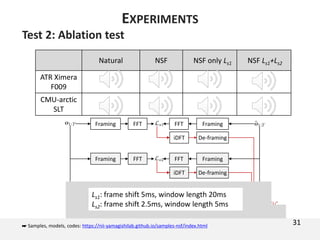
![Test 2: Ablation test
One more corpus
Copy-synthesis
27[2] J. Kominek and A. W. Black. The cmu arctic speech databases. In Fifth ISCA workshop on speech synthesis, 2004.
Corpus Size Note
CMU-arctic SLT [2] 0.83 hours 16kHz, English
Feature Dimension
Acoustic
Mel-spectrogram 80
F0 1
EXPERIMENTS](https://image.slidesharecdn.com/slp-l8-190521233946/85/Neural-source-filter-waveform-model-27-320.jpg)
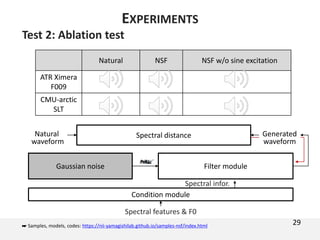

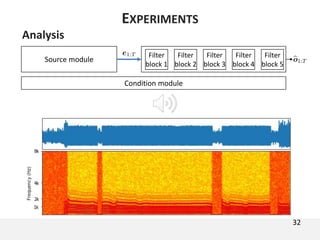
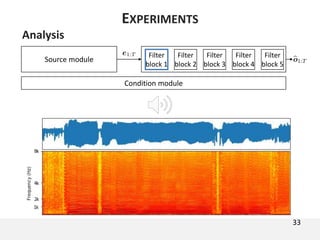
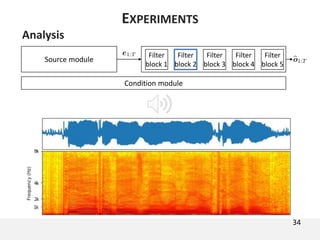
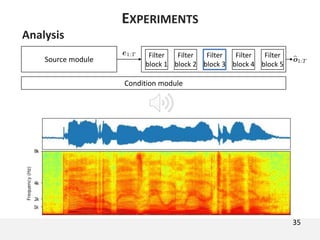
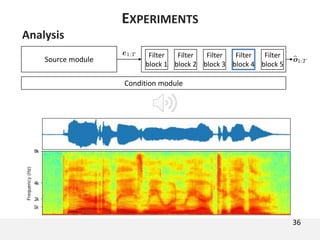
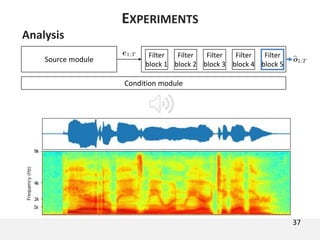

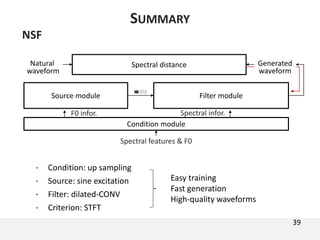
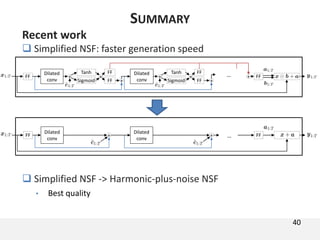

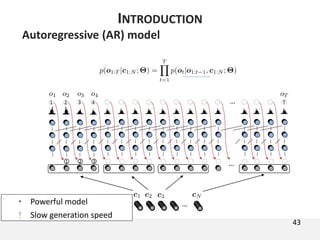
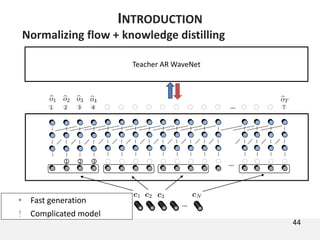
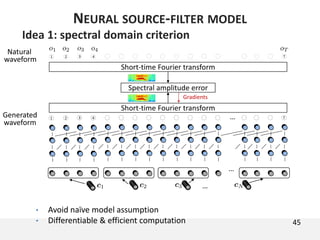
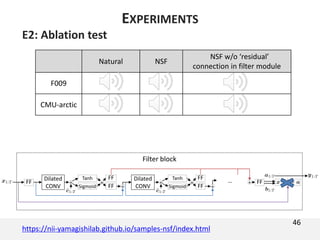

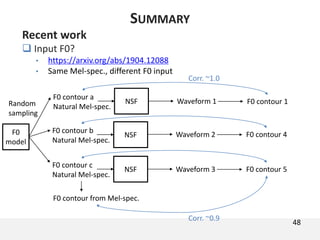
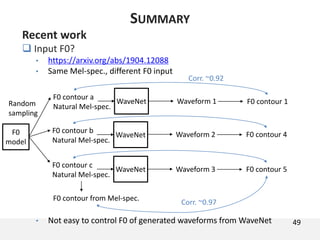
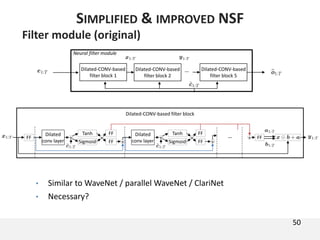
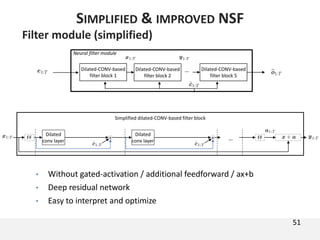
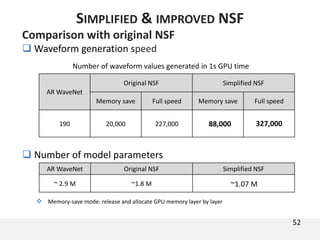
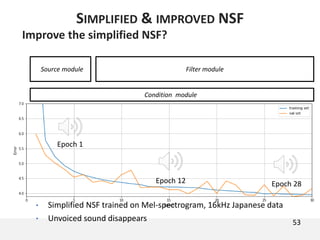
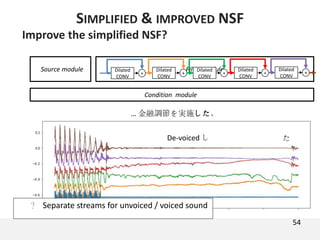
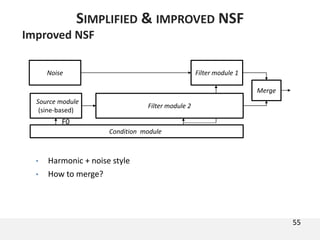
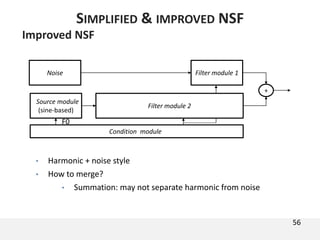
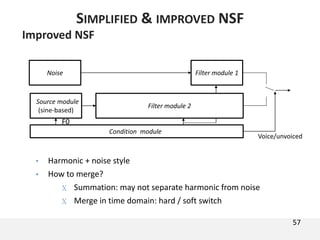
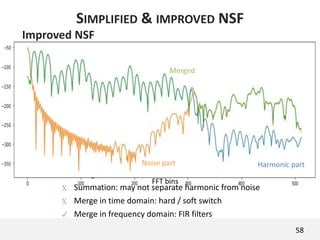
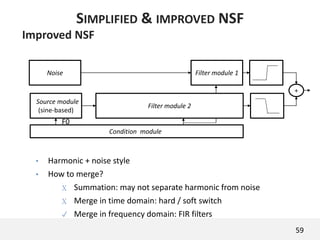
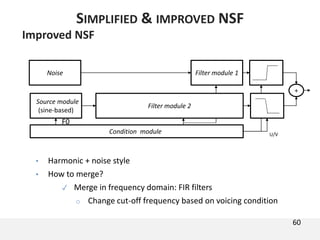
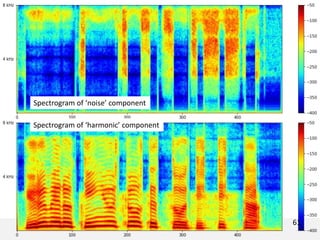
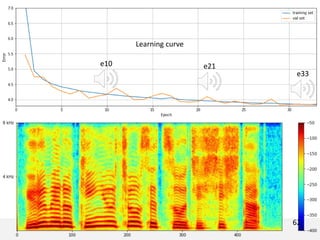
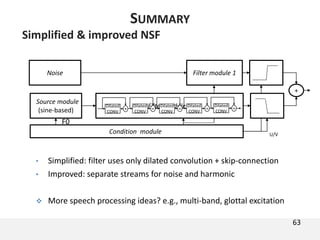


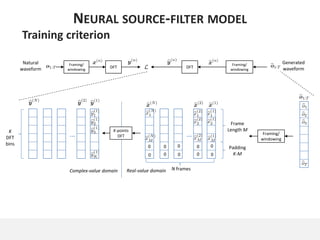
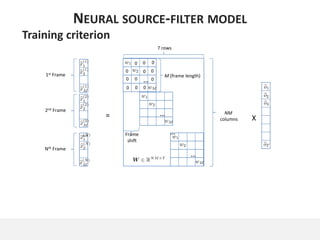
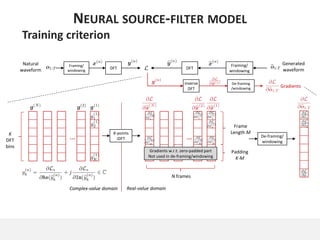
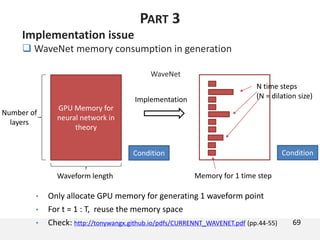
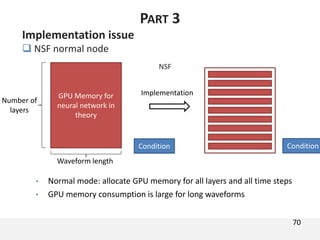
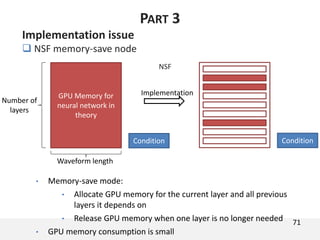


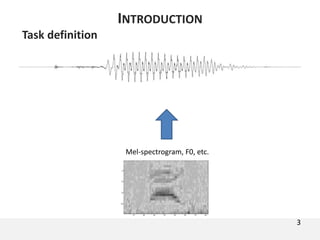
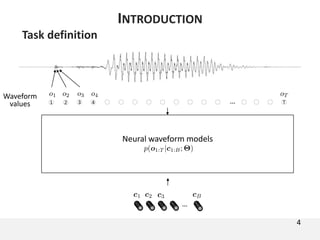
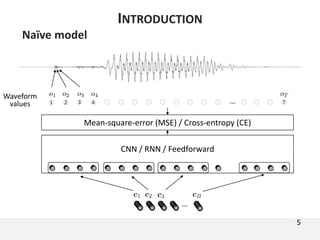
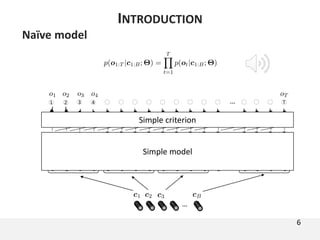
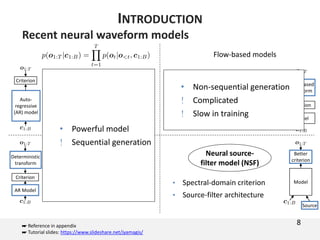
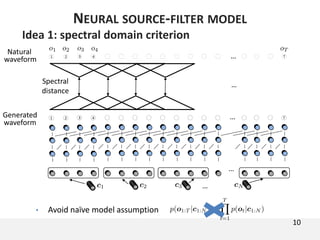
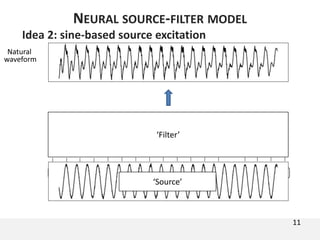
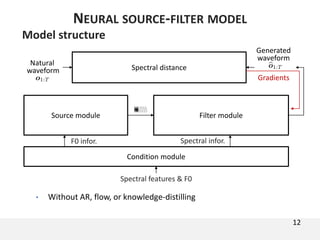
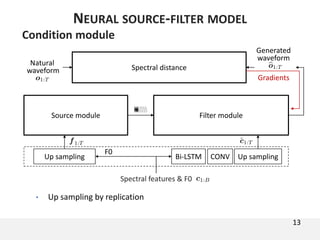
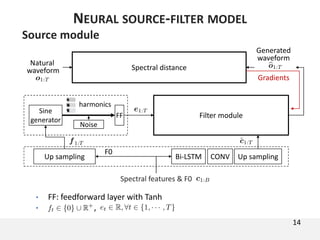
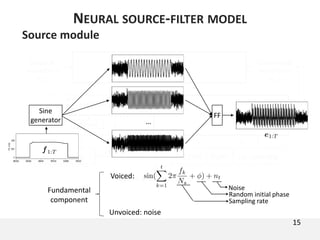
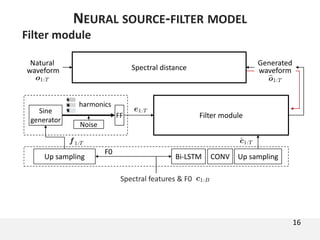
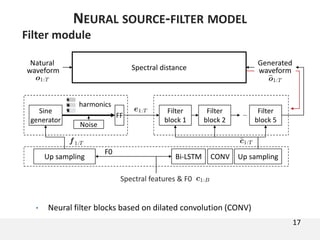
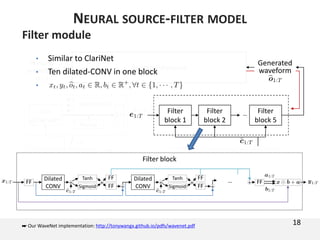
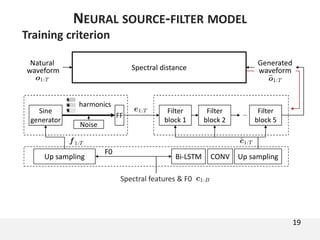
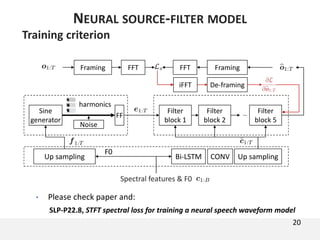
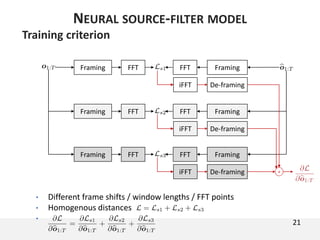
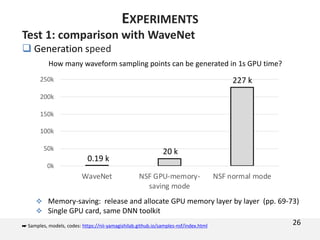
The document proposes a neural source-filter waveform model (NSF) for speech synthesis. The NSF model consists of three modules: a condition module that upsamples spectral features and F0, a source module that generates a sine excitation signal, and a filter module with dilated convolutional blocks. The model is trained directly on waveforms using a spectral distance criterion in the STFT domain. Experiments show the NSF model generates high quality waveforms comparable to WaveNet, with faster generation speed. Ablation tests analyze the importance of the sine excitation source and different spectral loss terms. The NSF provides a simpler alternative to autoregressive models for neural speech synthesis.













![[論文紹介] LSTM (LONG SHORT-TERM MEMORY)](https://cdn.slidesharecdn.com/ss_thumbnails/2018-181019021803-thumbnail.jpg?width=640&height=640&fit=bounds)


































































