Download as PDF, PPTX




























![Trigram Features: Merging
features ← {};
for L ∈ L do
trigrams ← ∅;
for file ∈ FilesL do
T ← computeTrigrams(file) ; // Str → IN
T ← mostOccurring(T) ; // Top 30 trigrams
for t ∈ keys(T) do
trigrams[t] ← trigrams[t] + 1;
T ← mostOccurring(T) ;
features ← features ∪ keys(trigrams);
Alberto Simões, José João Almeida, Simon D. Byers Language Iden fica on: a Neural Network approach](https://image.slidesharecdn.com/presentation-140614153833-phpapp02/75/Language-Identification-A-neural-network-approach-30-2048.jpg)
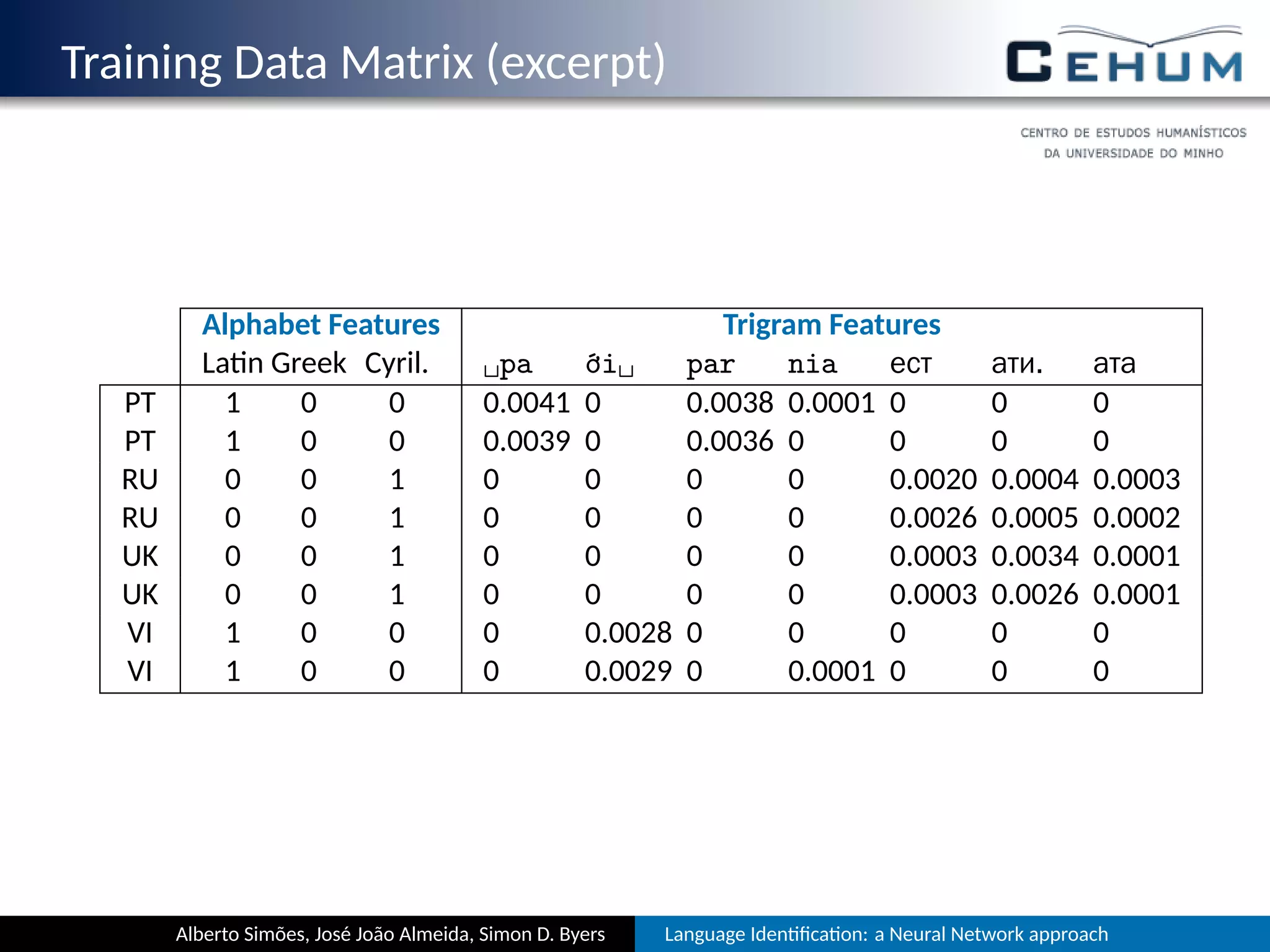

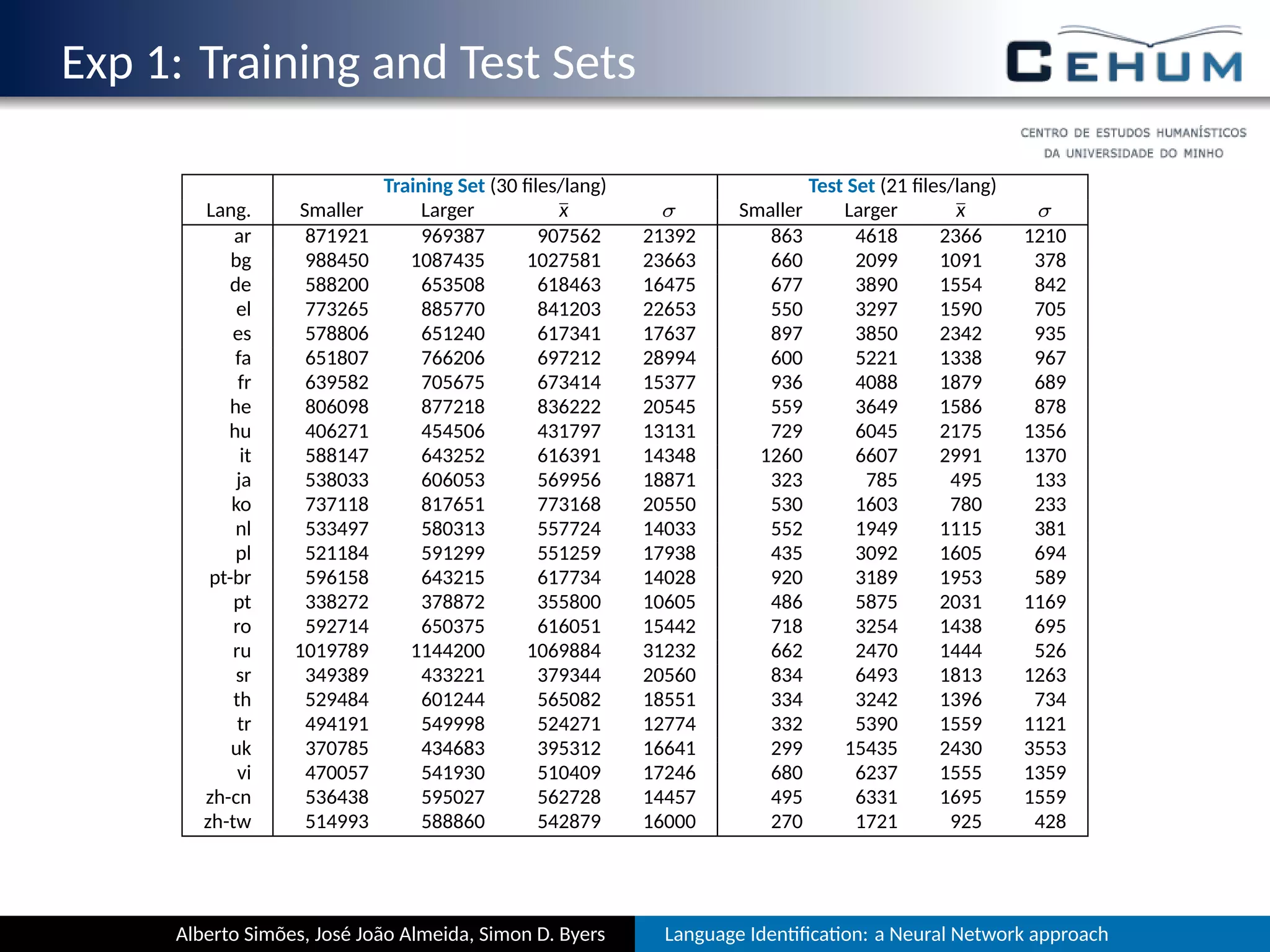
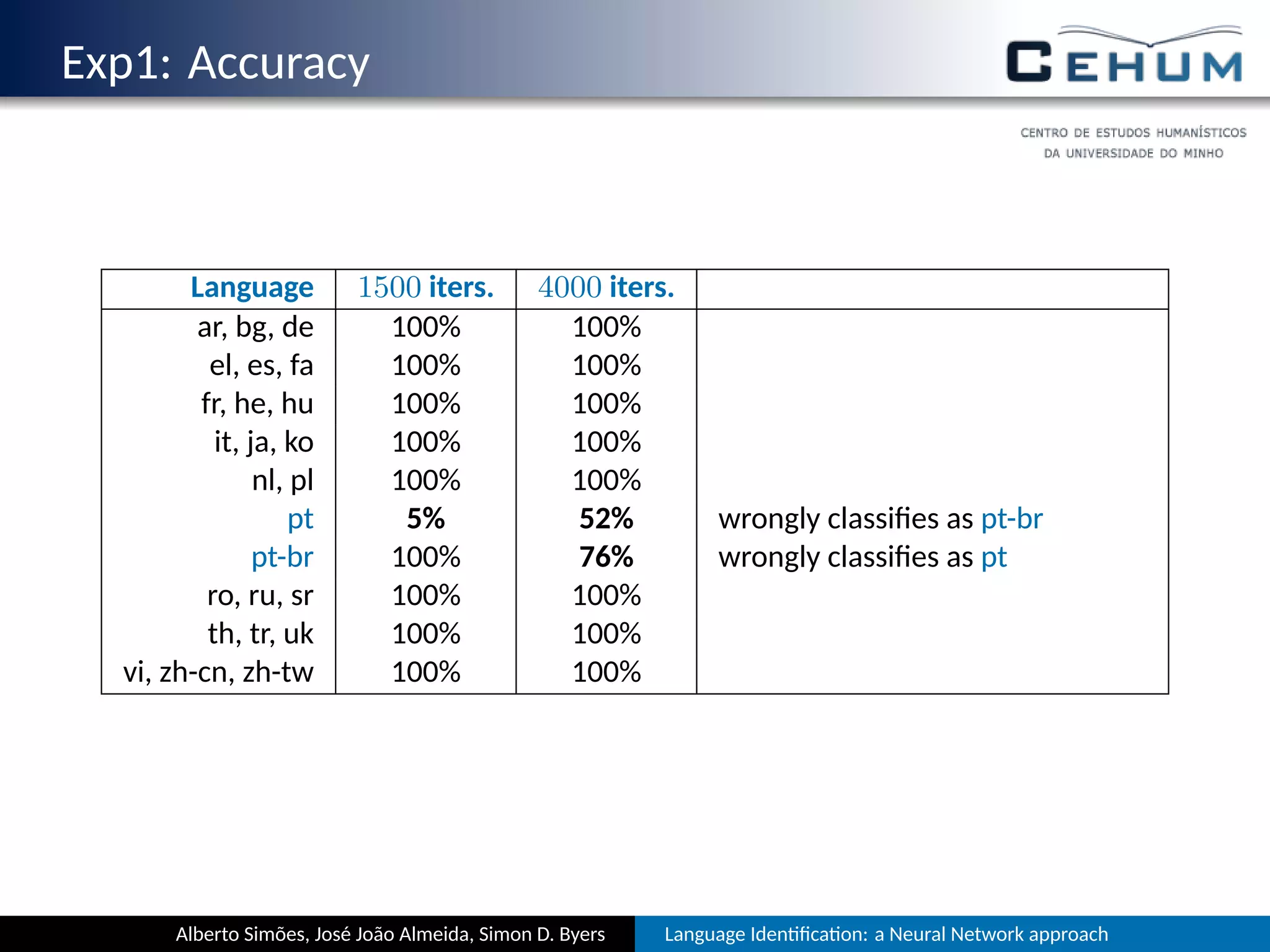
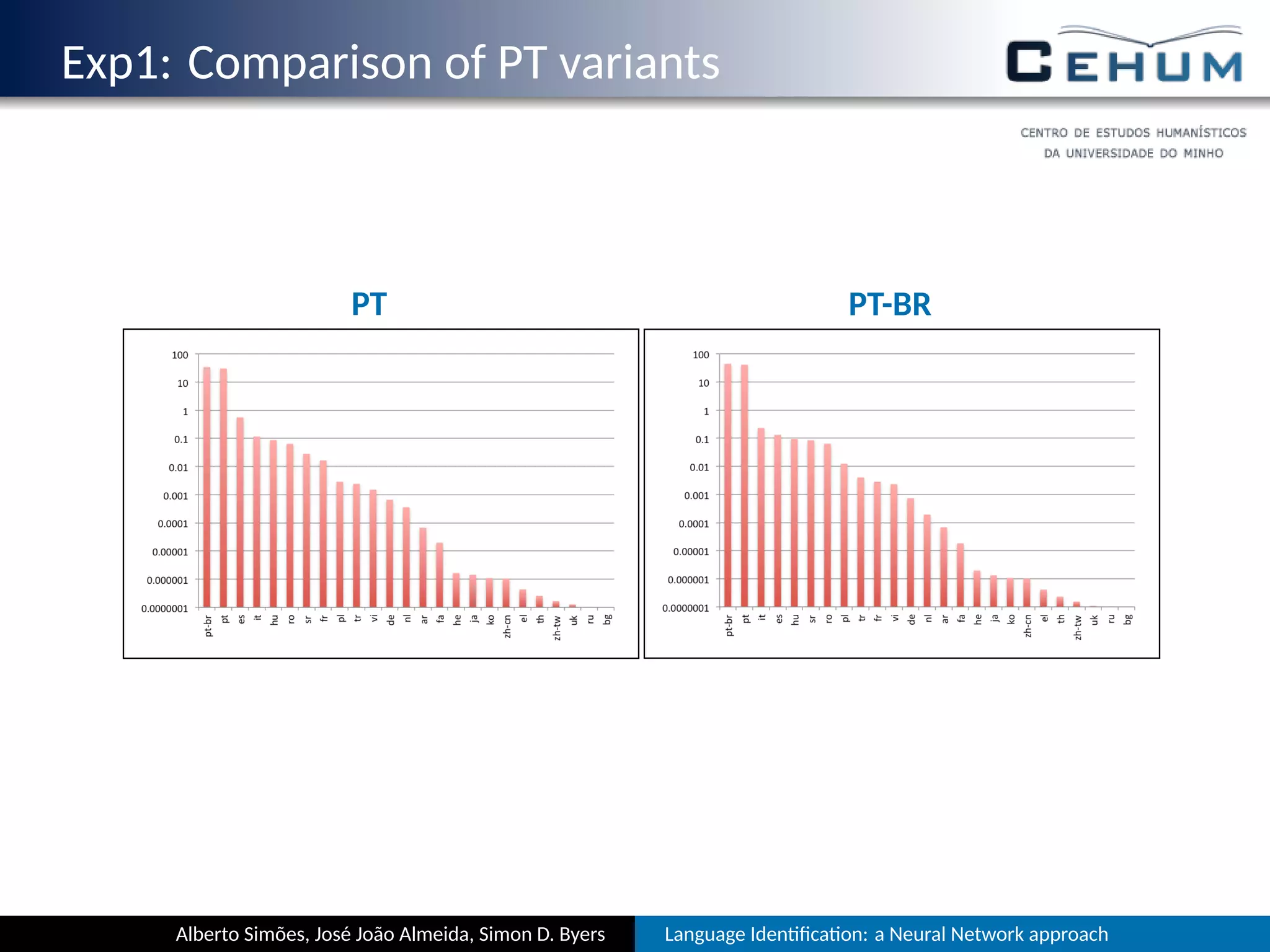
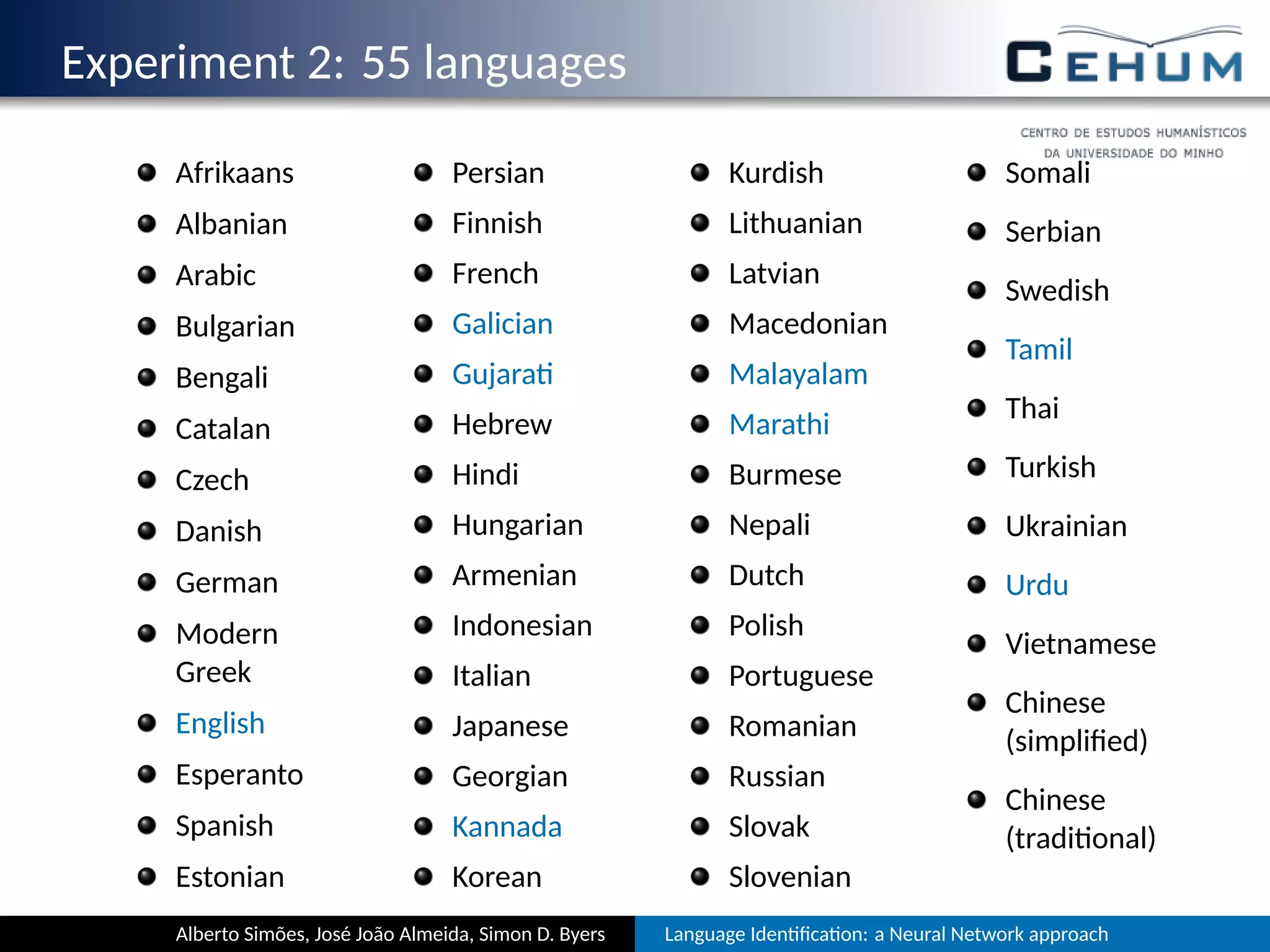





This document describes a neural network approach for language identification. It discusses extracting features from text such as alphabet characters and character sequences (unigrams, bigrams, trigrams) that are common in different languages. Training data is prepared from texts of over 105 languages on the TED website, with out-of-vocabulary words removed. The neural network architecture has an input layer for features, hidden layers, and an output layer for language predictions. Alphabet features count Unicode character classes and are binarized. Trigrams are used as sequence features to aid comparisons between languages.