Download as PDF, PPTX







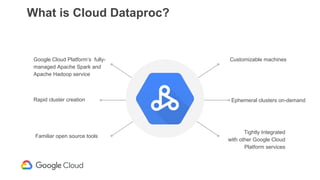
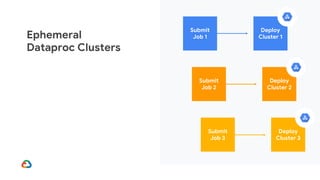



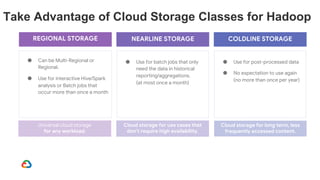
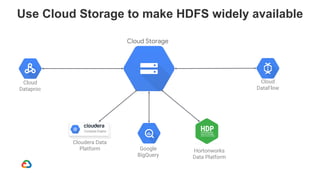
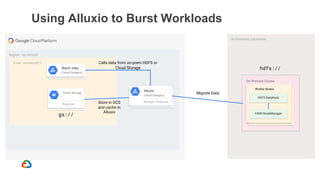




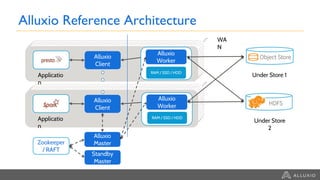
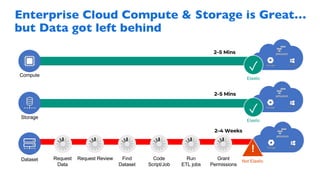
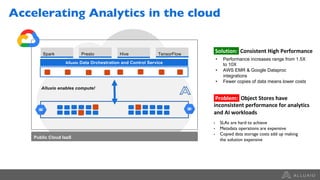
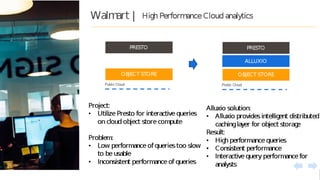


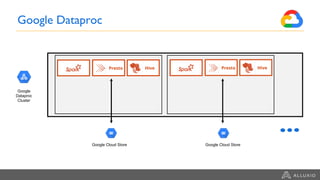
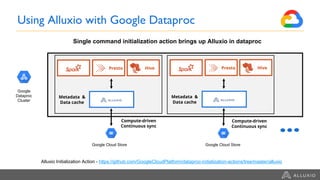

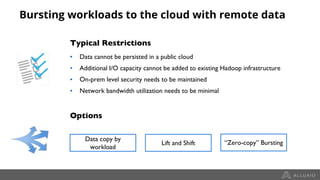
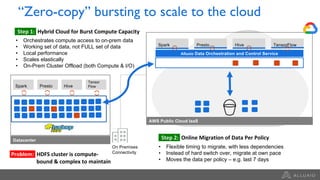
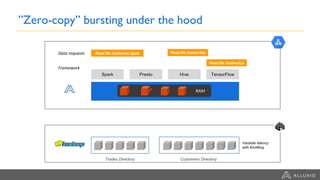

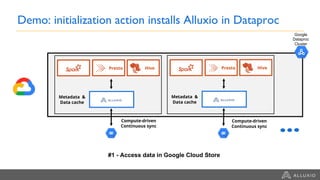
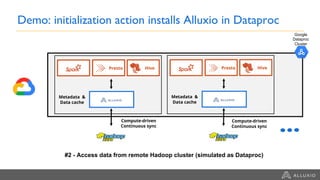
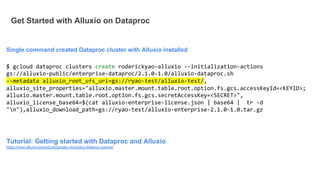



Google Dataproc is Google Cloud's fully managed Apache Spark and Apache Hadoop service. Alluxio is an open source data orchestration platform that can be used with Dataproc to accelerate analytics workloads. With a single initialization action, Alluxio can be installed on a Dataproc cluster to cache data from Cloud Storage for faster queries. Alluxio also enables "zero-copy bursting" of workloads to the cloud by allowing frameworks to access data directly from remote HDFS without needing to copy it. This provides elastic compute capacity while avoiding high network latency and bandwidth costs of copying large datasets.























































































