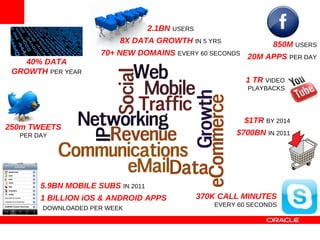
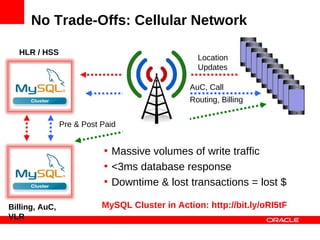
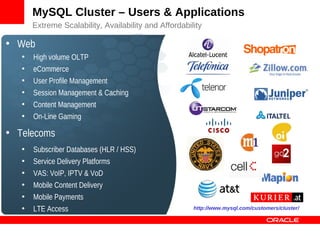
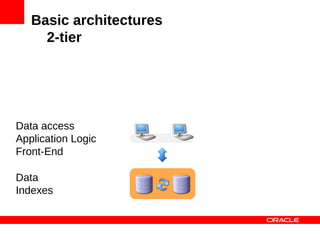
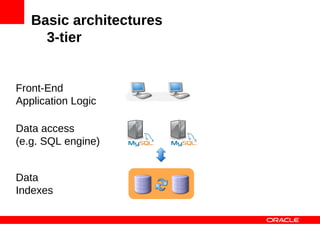
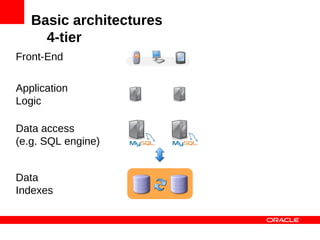
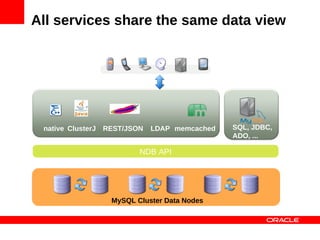
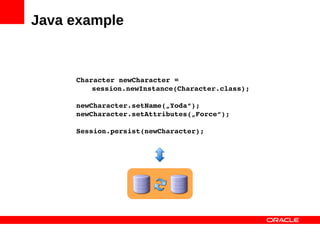
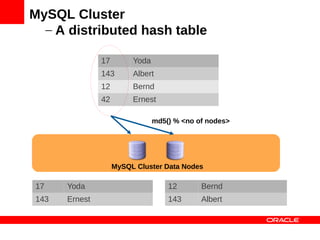
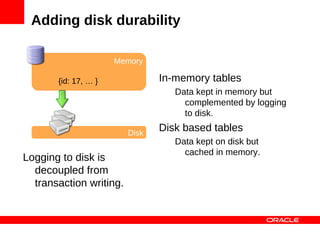
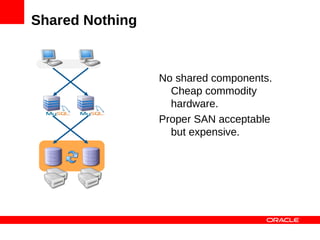
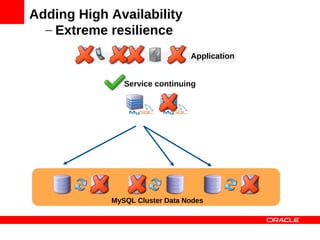
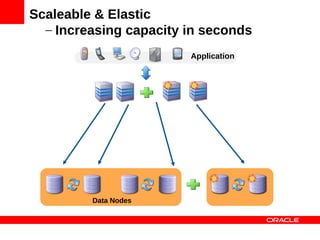
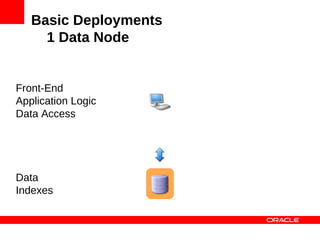
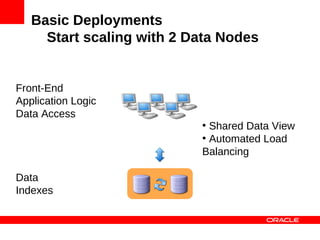
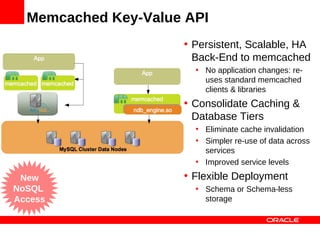
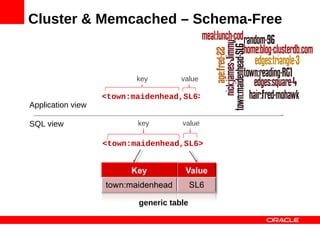
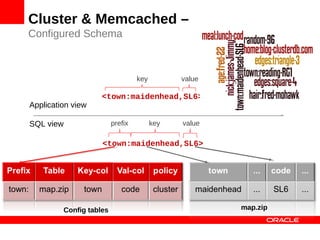
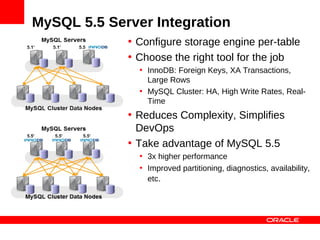
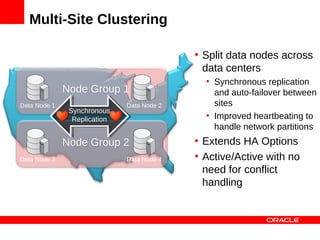
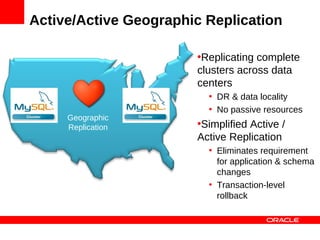
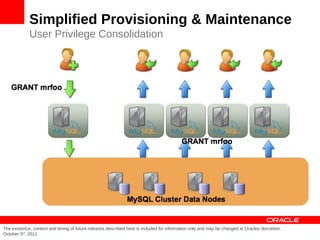
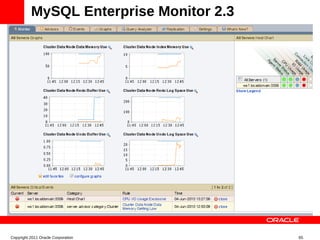
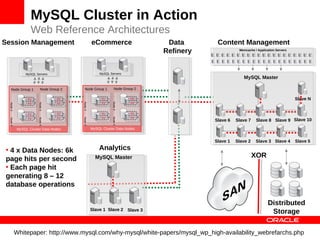
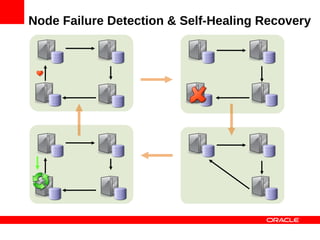
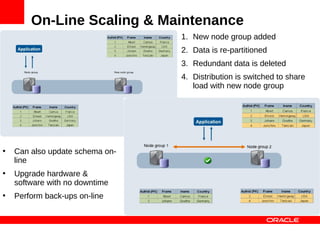
MySQL Cluster is a distributed database that provides extreme scalability, high availability, and real-time performance. It uses an auto-sharding and auto-replicating architecture to distribute data across multiple low-cost servers. Key benefits include scaling reads and writes, 99.999% availability through its shared-nothing design with no single point of failure, and real-time responsiveness. It supports both SQL and NoSQL interfaces to enable complex queries as well as high-performance key-value access.












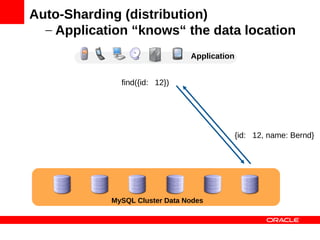
![Auto-Sharding (distribution)
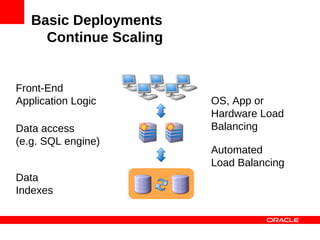
Application
[ {id: 12, name: Bernd}, {id: 143, name: Albert},
{id: 42, name: Ernest}, …, {id: 17, name: Yoda}]
{id: 17, … } {id: 143, … } {id: 42, … } {id: 12, … }
MySQL Cluster Data Nodes](https://image.slidesharecdn.com/mysqlclusterscalingnosqlmatters-120604140550-phpapp01/85/MySQL-Cluster-Scaling-to-a-Billion-Queries-24-320.jpg)

![Adding High Availability
– Introducing Node Groups
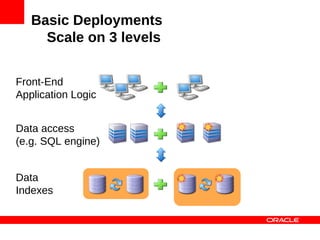
Application
[ {id: 12, name: Bernd}, {id: 143, name: Albert},
{id: 42, name: Ernest}, …, {id: 17, name: Yoda}]
{id: 17, … } {id: 143, … } {id: 42, … } {id: 12, … }
MySQL Cluster Data Nodes](https://image.slidesharecdn.com/mysqlclusterscalingnosqlmatters-120604140550-phpapp01/85/MySQL-Cluster-Scaling-to-a-Billion-Queries-27-320.jpg)
![Adding High Availability
- Synchronous Replication
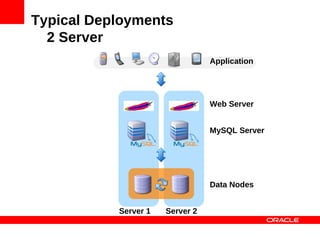
Application
[ {id: 12, name: Bernd}, {id: 143, name: Albert},
{id: 42, name: Ernest}, …, {id: 17, name: Yoda}]
{id: 17, … } {id: 143, … } {id: 42, … } {id: 12, … }
MySQL Cluster Data Nodes](https://image.slidesharecdn.com/mysqlclusterscalingnosqlmatters-120604140550-phpapp01/85/MySQL-Cluster-Scaling-to-a-Billion-Queries-28-320.jpg)


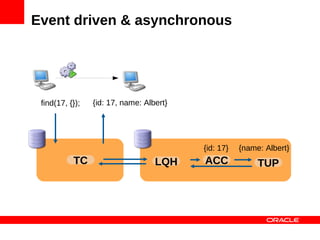
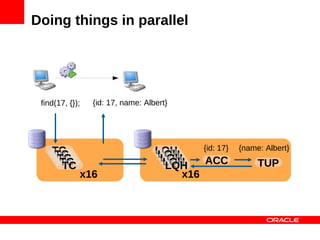
![Doing things in parallel
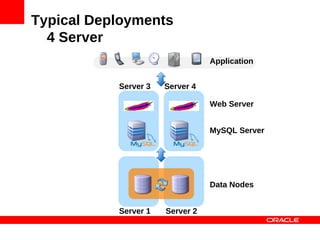
find(17, {}); find([12, 17], {});
MySQL Cluster Data Nodes](https://image.slidesharecdn.com/mysqlclusterscalingnosqlmatters-120604140550-phpapp01/85/MySQL-Cluster-Scaling-to-a-Billion-Queries-35-320.jpg)























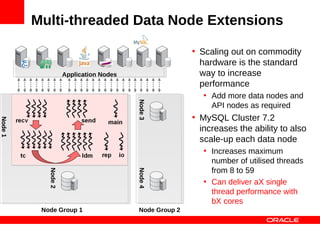
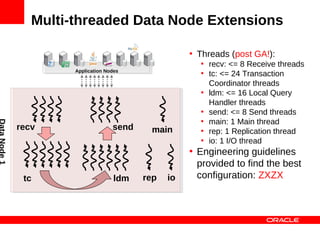
![Multi-threaded Data Node Extensions
ThreadConfig :=<entry> [ ,<entry> ] +
entry :=<type>={ [<param> ]+ }
• Note that extra send,
param := count = N |
cpubind = L |
recv & tc threads
cpuset = L will be part of post-
type := ldm | main | recv | rep | GA maintenance
maint | send | tc | io release.
Example:
ThreadConfig=ldm={count=2,cpubind=1,2},
ldm={count=2,cpuset=6-9},
main={cpubind=12},rep={cpubind=11}](https://image.slidesharecdn.com/mysqlclusterscalingnosqlmatters-120604140550-phpapp01/85/MySQL-Cluster-Scaling-to-a-Billion-Queries-87-320.jpg)


















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)









