Download to read offline












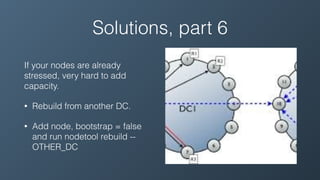




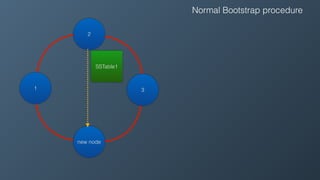
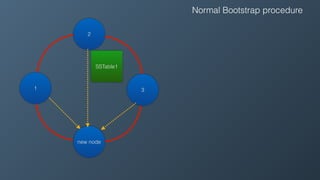
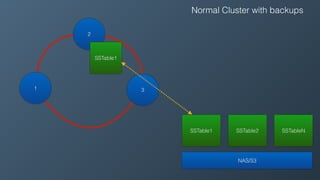
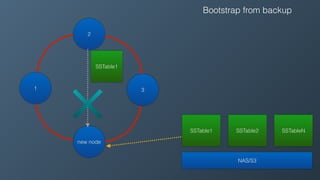
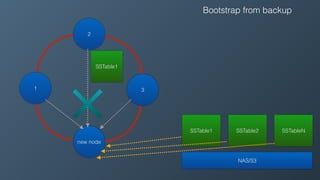
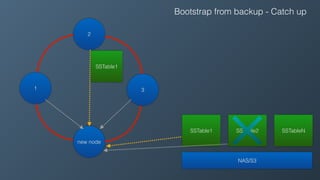

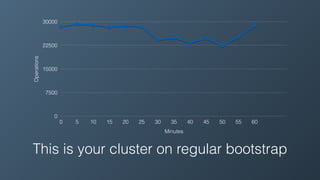
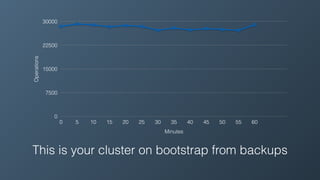




Ben Bromhead, co-founder and CTO of Instaclustr, discusses the challenges of scaling Cassandra clusters through traditional bootstrapping processes that can stress existing nodes and increase load. He proposes a solution to bootstrap from backups by streaming immutable sstables from backup locations, which could optimize performance and reduce side effects. This method is currently in beta with select customers and aims to enhance operational efficiency and cost-effectiveness for managed Cassandra services.





















































































