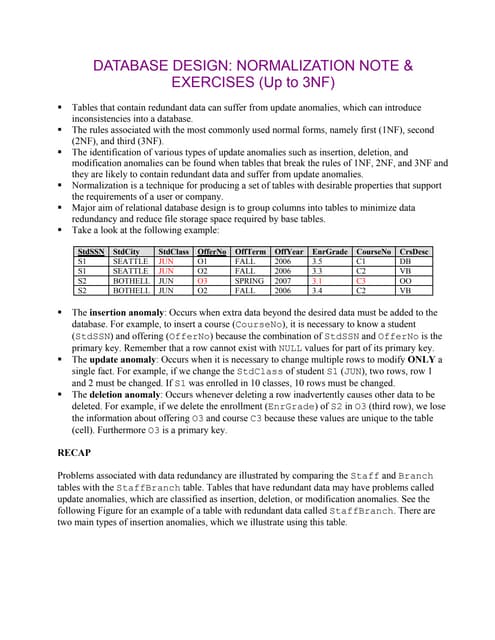
The document outlines four informal design guidelines for creating high-quality relation schemas in databases, focusing on clear semantics, reducing redundancy, minimizing null values, and preventing spurious tuples. It emphasizes that clear attribute interpretation and a proper structure are essential to avoid inconsistencies and anomalies, while methods to mitigate these issues include normalization and using appropriate constraints. Overall, adhering to these guidelines promotes data integrity, clarity, and efficient database management.