Downloaded 18 times


















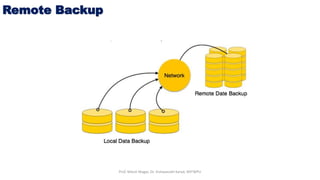



The document discusses database crash recovery. It explains that crash recovery is needed to restore the database to a consistent state after failures like system crashes or hardware errors. It describes the log-based recovery process used by database management systems, including writing log records, undo/redo operations, and using checkpoints to optimize the recovery process. The sources of failures and the need for backup and recovery from catastrophic failures are also covered.












































































