Downloaded 14 times



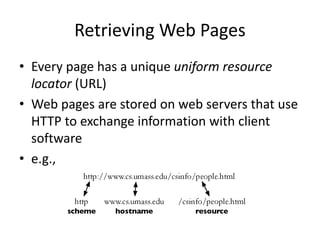

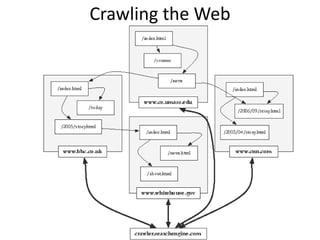







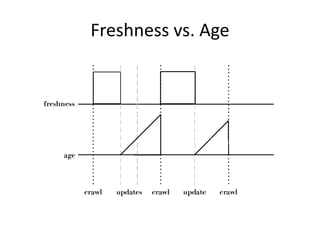

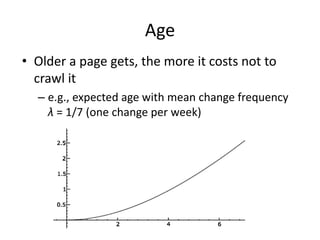






















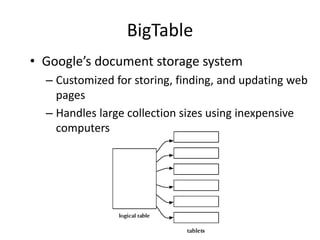


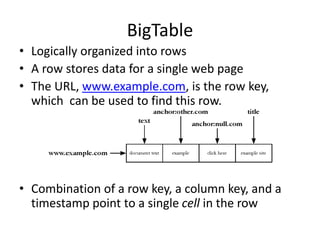







This document provides information about building a basic web crawler, including: - Crawlers find and download web pages to build a collection for search engines by starting with seed URLs and following links on downloaded pages. - Crawlers use techniques like multiple threads, politeness policies, and robots.txt files to efficiently and politely crawl the web at scale. - Crawlers must also handle challenges like duplicate pages, updating freshness, focused crawling of specific topics, and accessing deep web or private pages.



































































![How Big Brands are Taking Your Traffic in Alberta [Data Inside].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/howbigbrandsaretakingyourtrafficinalbertadatainside-260123180142-42d276f3-thumbnail.jpg?width=640&height=640&fit=bounds)





