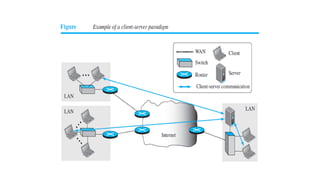
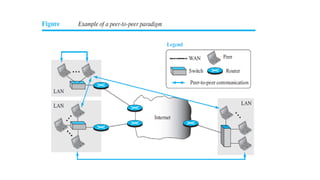
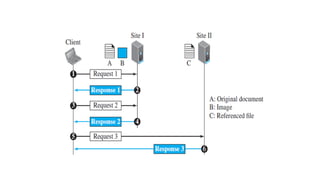
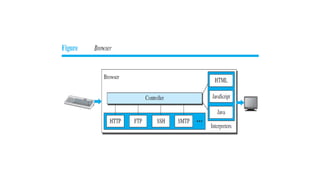
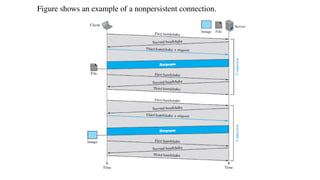
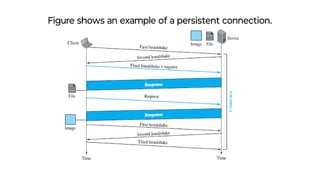
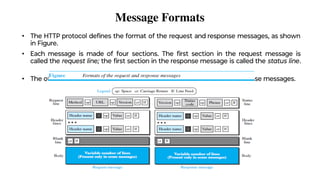
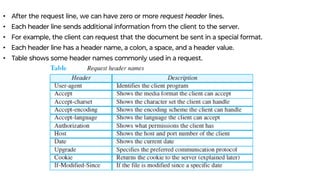
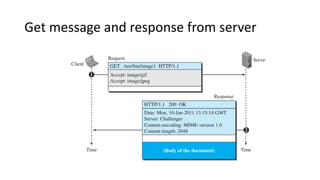
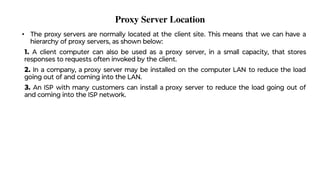
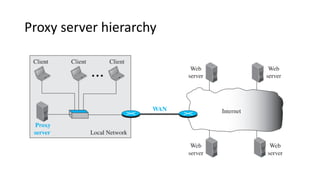
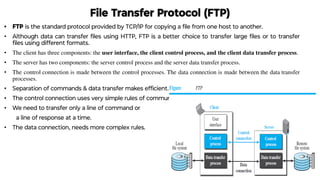
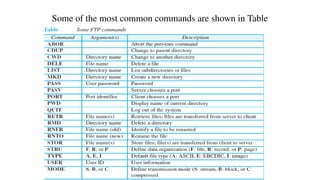
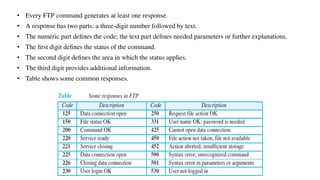
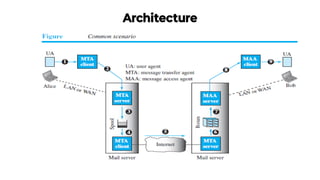
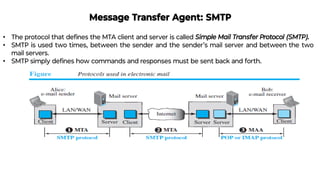
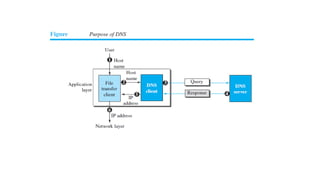
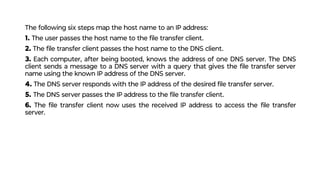
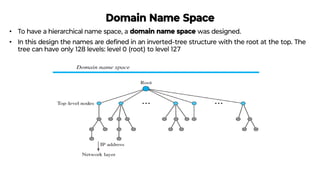
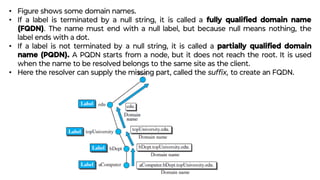
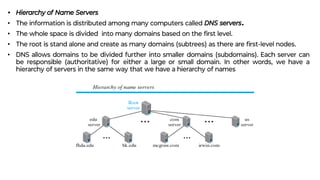
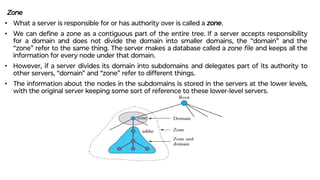
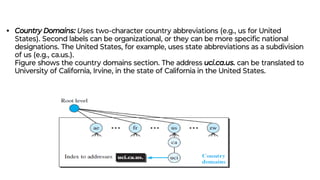
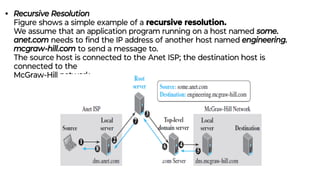
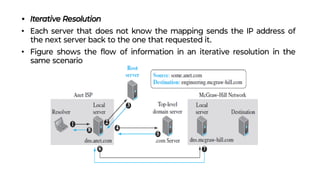
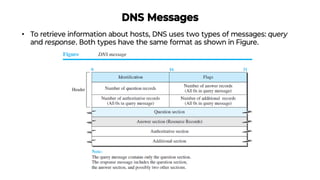
This document provides an overview of application layer protocols in the TCP/IP model. It discusses how the application layer provides services to users through logical connections. It describes standard protocols like HTTP and how nonstandard protocols can also be used. It explains the client-server and peer-to-peer paradigms used by application layer protocols to communicate. It provides details on the World Wide Web architecture and protocols like HTTP that power the web. It discusses web documents like static, dynamic, and active pages and how cookies can be used to maintain state across requests.