Downloaded 12 times














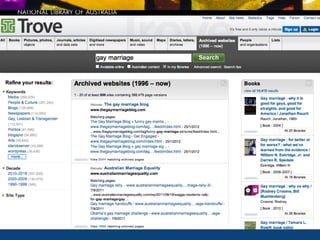
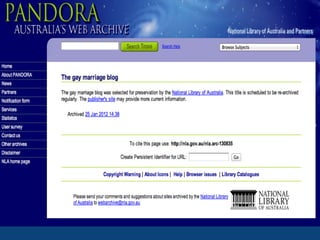
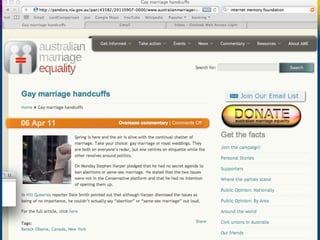

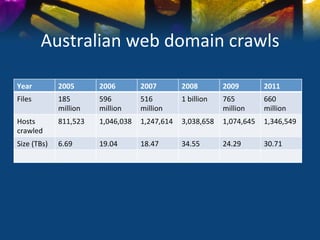







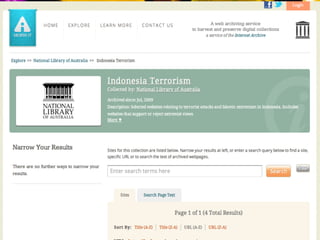

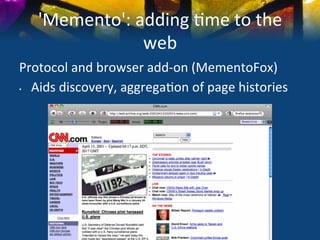










This document discusses various strategies and resources for archiving internet content for research purposes. It describes several existing large-scale web archives like the Internet Archive and Common Crawl, as well as national and institutional archives. It also outlines how researchers can collect targeted web archives using open-source tools or subscription-based services.





















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
