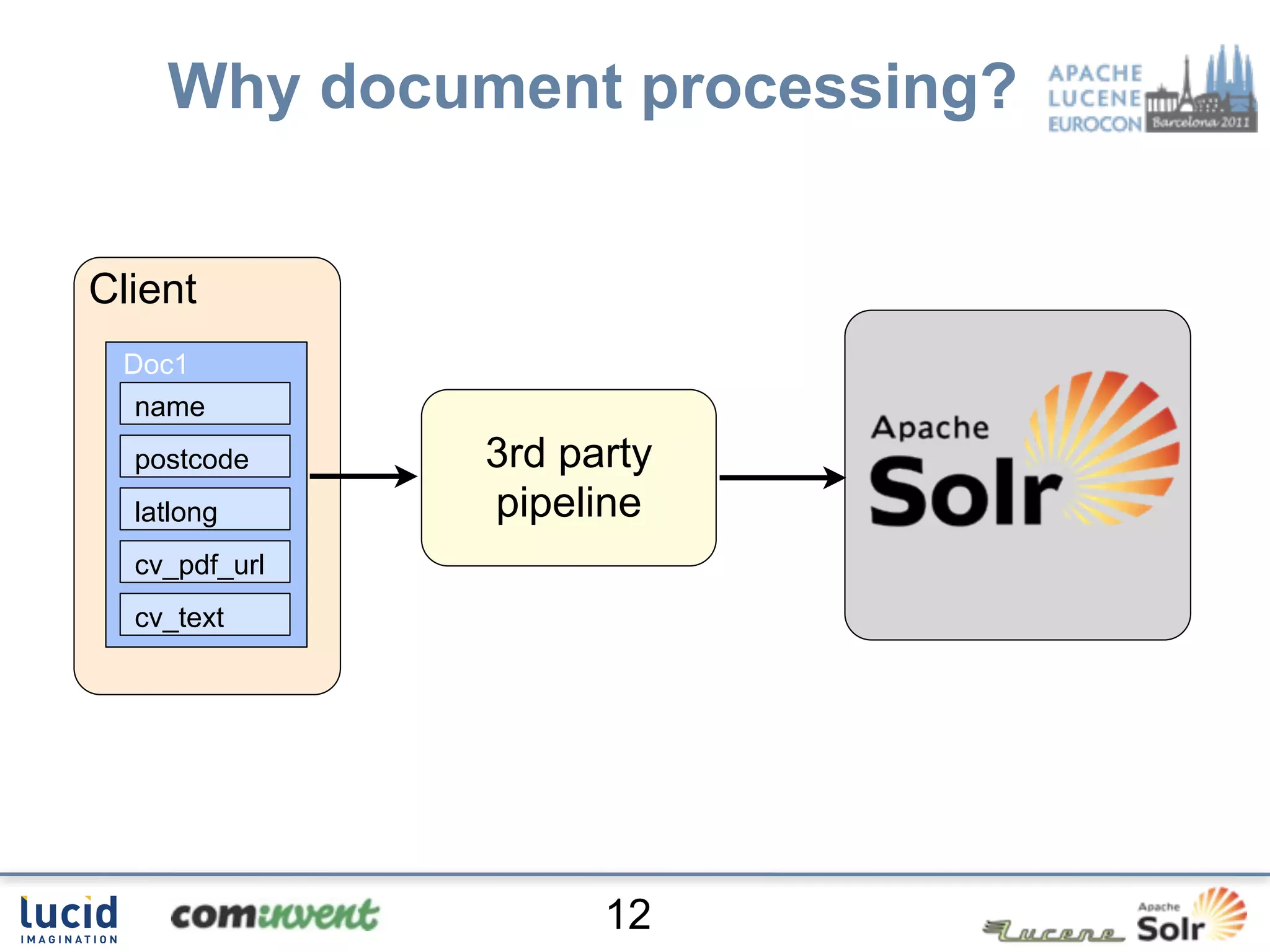
Download as PDF, PPTX


















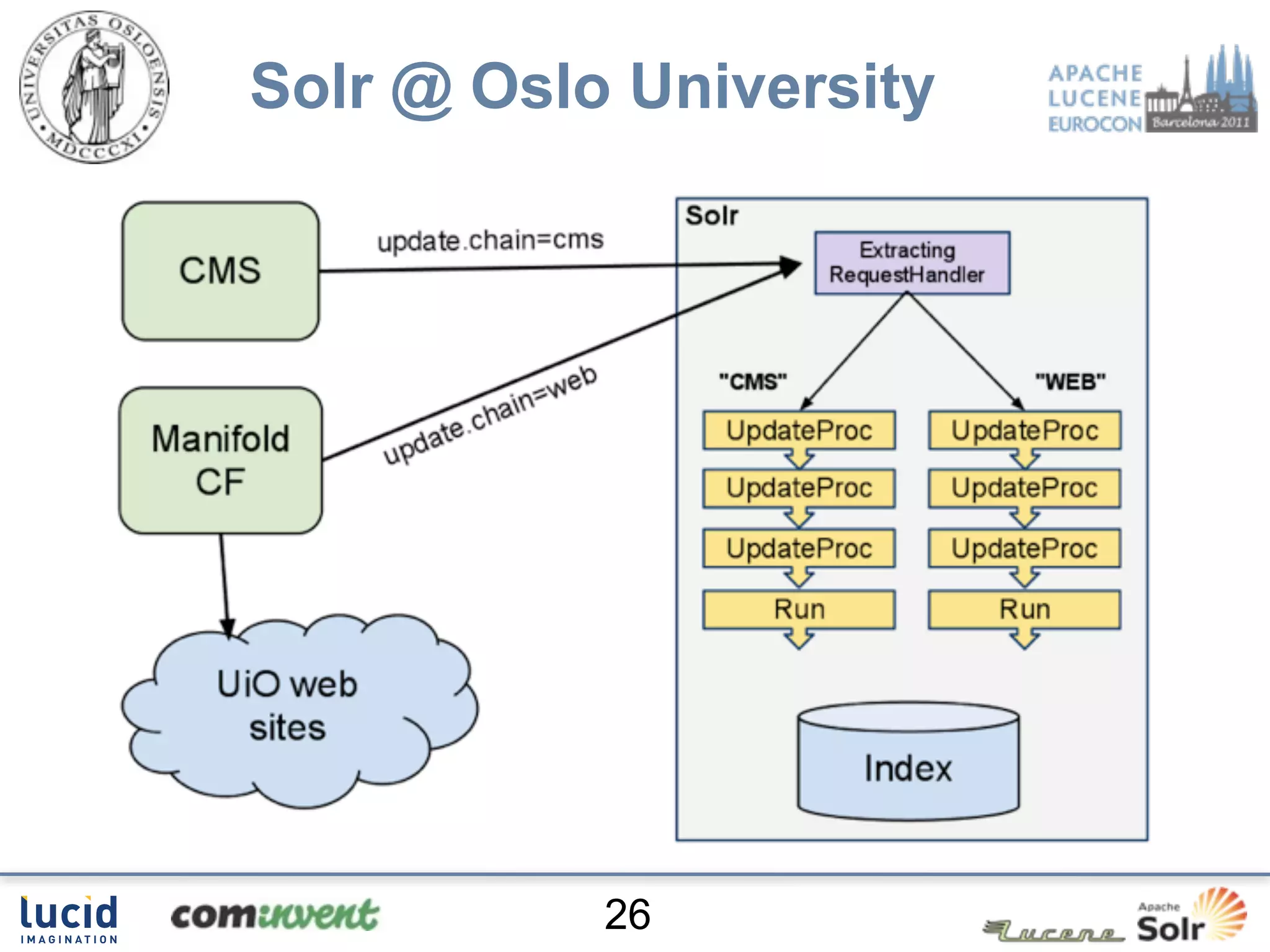
![Solr @ Oslo University
<?xml version="1.0"?>
<updateRequestProcessorChain name="web">
<processor class="solr.update.processor.LanguageIdentifierUpdateProcessorFactory">
<lst name="defaults">
<str name="langid.fl">title,content</str>
<str name="langid.idField">url</str>
<str name="langid.fallbackFields"></str>
<str name="langid.fallback">no</str>
<str name="langid.whitelist">no,en</str>
<str name="langid.langField">language</str>
<str name="langid.langsField">languages</str>
<bool name="langid.overwrite">true</bool>
<bool name="langid.map">true</bool>
<str name="langid.map.fl">title,content</str>
<double name="langid.threshold">0.5</double>
</lst>
</processor>
<processor class="no.uio.update.processor.RegexpReplaceProcessorFactory">
<bool name="enabled">true</bool>
<str name="fl">content_no content_en</str>
<str name="pattern">[su00A0]+</str>
<str name="replacement"> </str>
</processor>
<processor class="no.uio.update.processor.FixDuplicateContentTitleProcessorFactory">
<bool name="enabled">true</bool>
<str name="title.fl">title_no,title_en</str>
27
<str name="content.fl">content_no,content_en</str>](https://image.slidesharecdn.com/improvingsolrsupdatechain-janhydahl-111018172612-phpapp01/75/Improving-the-Solr-Update-Chain-32-2048.jpg)

![Solr @ Oslo University
<?xml version="1.0"?>
<updateRequestProcessorChain name="web">
<processor class="solr.update.processor.LanguageIdentifierUpdateProcessorFactory">
<lst name="defaults">
<str name="langid.fl">title,content</str>
<str name="langid.idField">url</str>
<str name="langid.fallbackFields"></str>
<str name="langid.fallback">no</str>
<str name="langid.whitelist">no,en</str>
<str name="langid.langField">language</str>
<str name="langid.langsField">languages</str>
<bool name="langid.overwrite">true</bool>
<bool name="langid.map">true</bool>
<str name="langid.map.fl">title,content</str>
<double name="langid.threshold">0.5</double>
</lst>
</processor>
<processor class="no.uio.update.processor.RegexpReplaceProcessorFactory">
<bool name="enabled">true</bool>
<str name="fl">content_no content_en</str>
<str name="pattern">[su00A0]+</str>
<str name="replacement"> </str>
</processor>
<processor class="no.uio.update.processor.FixDuplicateContentTitleProcessorFactory">
<bool name="enabled">true</bool>
<str name="title.fl">title_no,title_en</str>
27
<str name="content.fl">content_no,content_en</str>](https://image.slidesharecdn.com/improvingsolrsupdatechain-janhydahl-111018172612-phpapp01/75/Improving-the-Solr-Update-Chain-34-2048.jpg)
![</processor>
<processor class="no.uio.update.processor.RegexpReplaceProcessorFactory">
<bool name="enabled">true</bool>
Solr @ Oslo University
<str name="fl">content_no content_en</str>
<str name="pattern">[su00A0]+</str>
<str name="replacement"> </str>
</processor>
<processor class="no.uio.update.processor.FixDuplicateContentTitleProcessorFactory">
<bool name="enabled">true</bool>
<str name="title.fl">title_no,title_en</str>
<str name="content.fl">content_no,content_en</str>
<str name="contentType.field">tika_Content-Type</str>
<str name="contentType.regexp">^(text/html|application/xhtml).*</str>
</processor>
<processor class="no.uio.update.processor.URLClassifyProcessorFactory">
<bool name="enabled">true</bool>
<str name="domainOutputField">host</str>
<str name="canonicalUrlOutputField">canonicalurl</str>
</processor>
<processor class="no.uio.update.processor.RegexpBoostProcessorFactory">
<bool name="enabled">true</bool>
<str name="inputField">url</str>
<str name="boostField">urlboost</str>
<str name="boostFilename">${solr.solr.home}/conf/rank/urlboosts.txt</str>
</processor>
<processor class="no.uio.update.processor.StaticRankProcessorFactory">
<bool name="enabled">true</bool>
<str name="inputField">canonicalurl</str>
<str name="anchorField">anchortext</str>
<str name="rankField">docrank</str>
<str name="rankFilename">${solr.solr.home}/conf/rank/rankinfo.txt</str>
</processor>
<processor class="solr.LogUpdateProcessorFactory"/>
28](https://image.slidesharecdn.com/improvingsolrsupdatechain-janhydahl-111018172612-phpapp01/75/Improving-the-Solr-Update-Chain-35-2048.jpg)
![</processor>
<processor class="no.uio.update.processor.RegexpReplaceProcessorFactory">
<bool name="enabled">true</bool>
Solr @ Oslo University
<str name="fl">content_no content_en</str>
<str name="pattern">[su00A0]+</str>
<str name="replacement"> </str>
</processor>
<processor class="no.uio.update.processor.FixDuplicateContentTitleProcessorFactory">
<bool name="enabled">true</bool>
<str name="title.fl">title_no,title_en</str>
<str name="content.fl">content_no,content_en</str>
<str name="contentType.field">tika_Content-Type</str>
<str name="contentType.regexp">^(text/html|application/xhtml).*</str>
</processor>
<processor class="no.uio.update.processor.URLClassifyProcessorFactory">
<bool name="enabled">true</bool>
<str name="domainOutputField">host</str>
<str name="canonicalUrlOutputField">canonicalurl</str>
</processor>
<processor class="no.uio.update.processor.RegexpBoostProcessorFactory">
<bool name="enabled">true</bool>
<str name="inputField">url</str>
<str name="boostField">urlboost</str>
<str name="boostFilename">${solr.solr.home}/conf/rank/urlboosts.txt</str>
</processor>
<processor class="no.uio.update.processor.StaticRankProcessorFactory">
<bool name="enabled">true</bool>
<str name="inputField">canonicalurl</str>
<str name="anchorField">anchortext</str>
<str name="rankField">docrank</str>
<str name="rankFilename">${solr.solr.home}/conf/rank/rankinfo.txt</str>
</processor>
<processor class="solr.LogUpdateProcessorFactory"/>
28](https://image.slidesharecdn.com/improvingsolrsupdatechain-janhydahl-111018172612-phpapp01/75/Improving-the-Solr-Update-Chain-36-2048.jpg)
![</processor>
<processor class="no.uio.update.processor.RegexpReplaceProcessorFactory">
<bool name="enabled">true</bool>
Solr @ Oslo University
<str name="fl">content_no content_en</str>
<str name="pattern">[su00A0]+</str>
<str name="replacement"> </str>
</processor>
<processor class="no.uio.update.processor.FixDuplicateContentTitleProcessorFactory">
<bool name="enabled">true</bool>
<str name="title.fl">title_no,title_en</str>
<str name="content.fl">content_no,content_en</str>
<str name="contentType.field">tika_Content-Type</str>
<str name="contentType.regexp">^(text/html|application/xhtml).*</str>
</processor>
<processor class="no.uio.update.processor.URLClassifyProcessorFactory">
<bool name="enabled">true</bool>
<str name="domainOutputField">host</str>
<str name="canonicalUrlOutputField">canonicalurl</str>
</processor>
<processor class="no.uio.update.processor.RegexpBoostProcessorFactory">
<bool name="enabled">true</bool>
<str name="inputField">url</str>
<str name="boostField">urlboost</str>
<str name="boostFilename">${solr.solr.home}/conf/rank/urlboosts.txt</str>
</processor>
<processor class="no.uio.update.processor.StaticRankProcessorFactory">
<bool name="enabled">true</bool>
<str name="inputField">canonicalurl</str>
<str name="anchorField">anchortext</str>
<str name="rankField">docrank</str>
<str name="rankFilename">${solr.solr.home}/conf/rank/rankinfo.txt</str>
</processor>
<processor class="solr.LogUpdateProcessorFactory"/>
28](https://image.slidesharecdn.com/improvingsolrsupdatechain-janhydahl-111018172612-phpapp01/75/Improving-the-Solr-Update-Chain-37-2048.jpg)
![</processor>
<processor class="no.uio.update.processor.RegexpReplaceProcessorFactory">
<bool name="enabled">true</bool>
Solr @ Oslo University
<str name="fl">content_no content_en</str>
<str name="pattern">[su00A0]+</str>
<str name="replacement"> </str>
</processor>
<processor class="no.uio.update.processor.FixDuplicateContentTitleProcessorFactory">
<bool name="enabled">true</bool>
<str name="title.fl">title_no,title_en</str>
<str name="content.fl">content_no,content_en</str>
<str name="contentType.field">tika_Content-Type</str>
<str name="contentType.regexp">^(text/html|application/xhtml).*</str>
</processor>
<processor class="no.uio.update.processor.URLClassifyProcessorFactory">
<bool name="enabled">true</bool>
<str name="domainOutputField">host</str>
<str name="canonicalUrlOutputField">canonicalurl</str>
</processor>
<processor class="no.uio.update.processor.RegexpBoostProcessorFactory">
<bool name="enabled">true</bool>
<str name="inputField">url</str>
<str name="boostField">urlboost</str>
<str name="boostFilename">${solr.solr.home}/conf/rank/urlboosts.txt</str>
</processor>
<processor class="no.uio.update.processor.StaticRankProcessorFactory">
<bool name="enabled">true</bool>
<str name="inputField">canonicalurl</str>
<str name="anchorField">anchortext</str>
<str name="rankField">docrank</str>
<str name="rankFilename">${solr.solr.home}/conf/rank/rankinfo.txt</str>
</processor>
<processor class="solr.LogUpdateProcessorFactory"/>
28](https://image.slidesharecdn.com/improvingsolrsupdatechain-janhydahl-111018172612-phpapp01/75/Improving-the-Solr-Update-Chain-38-2048.jpg)




















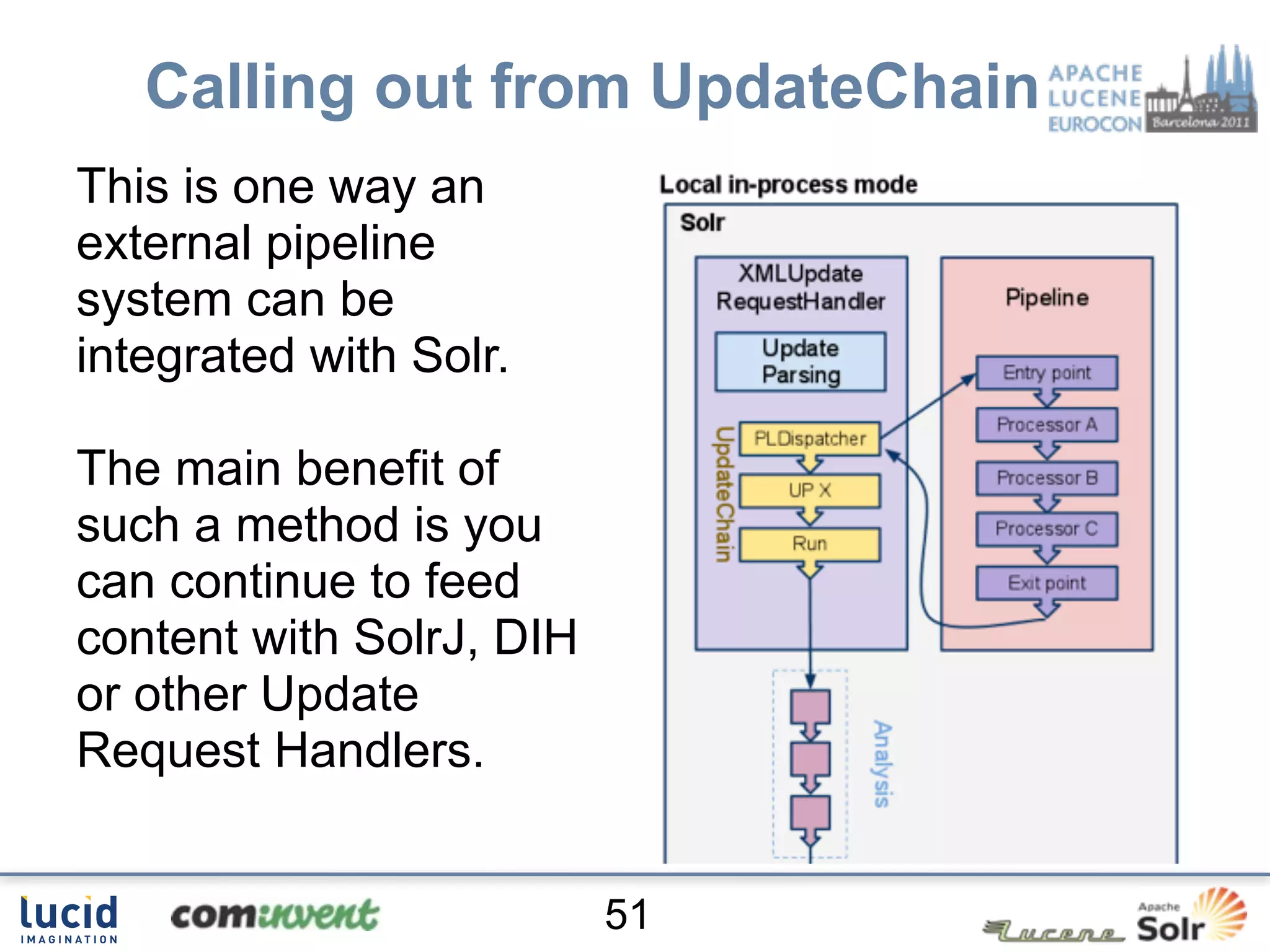
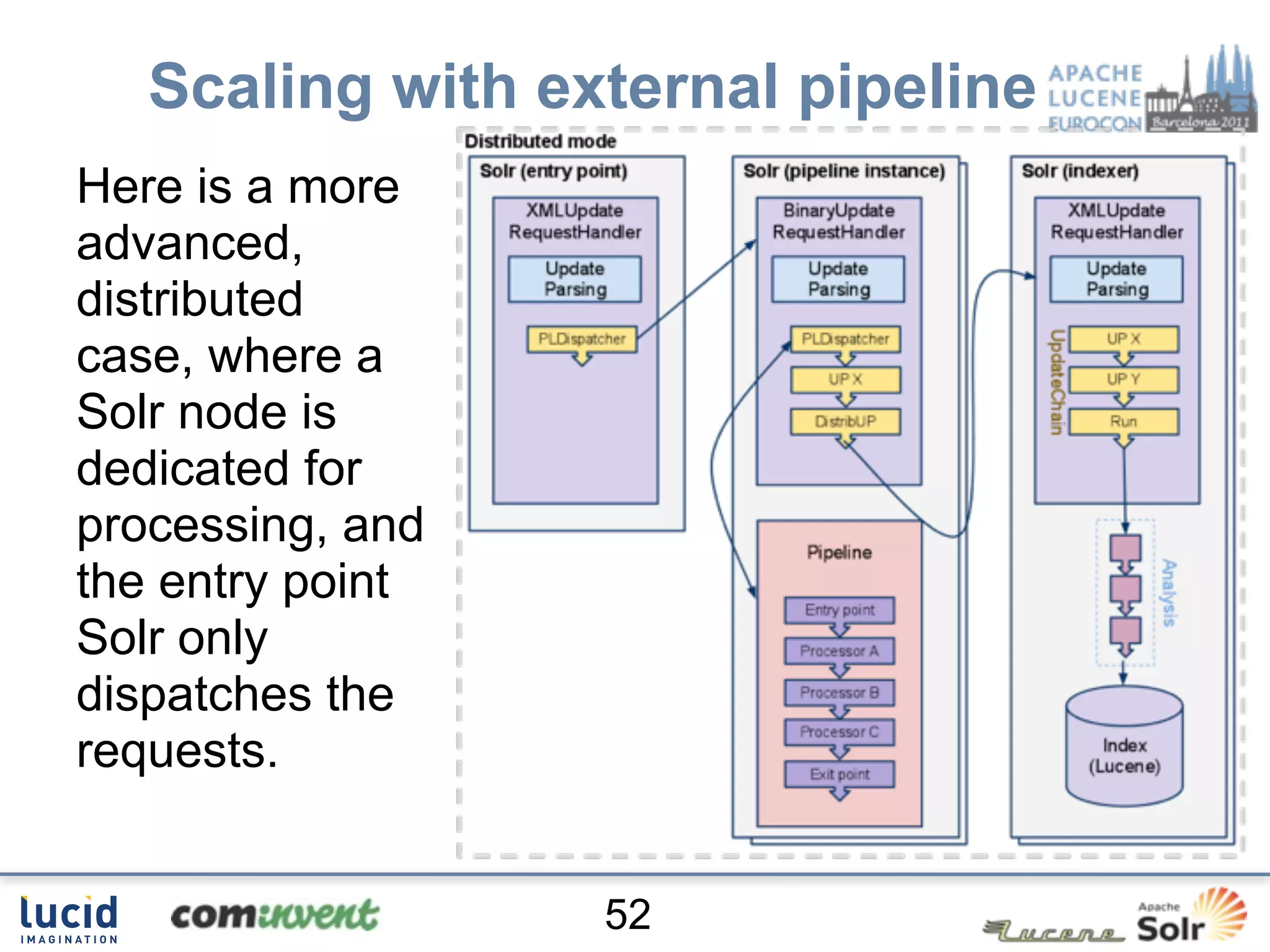

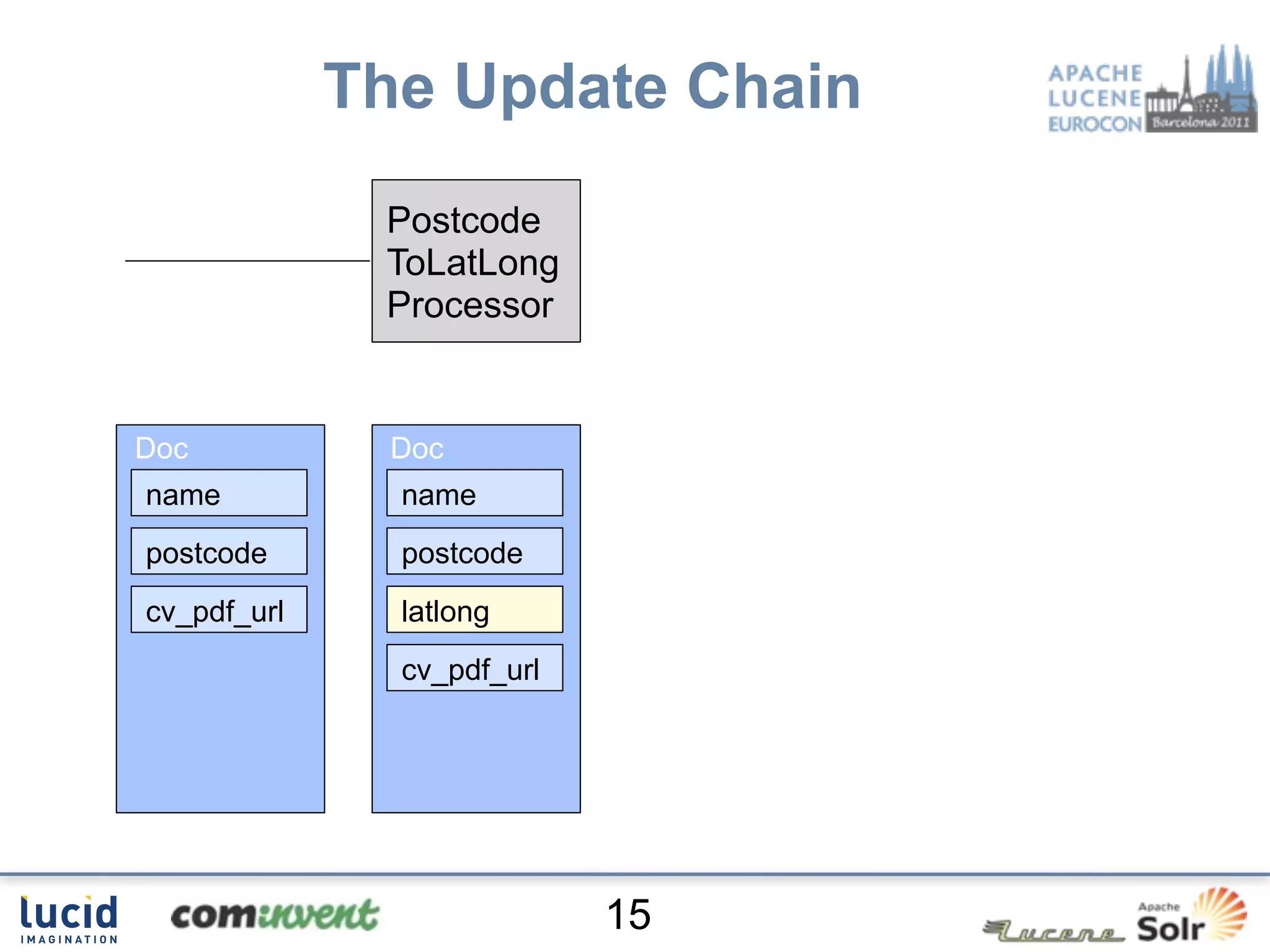
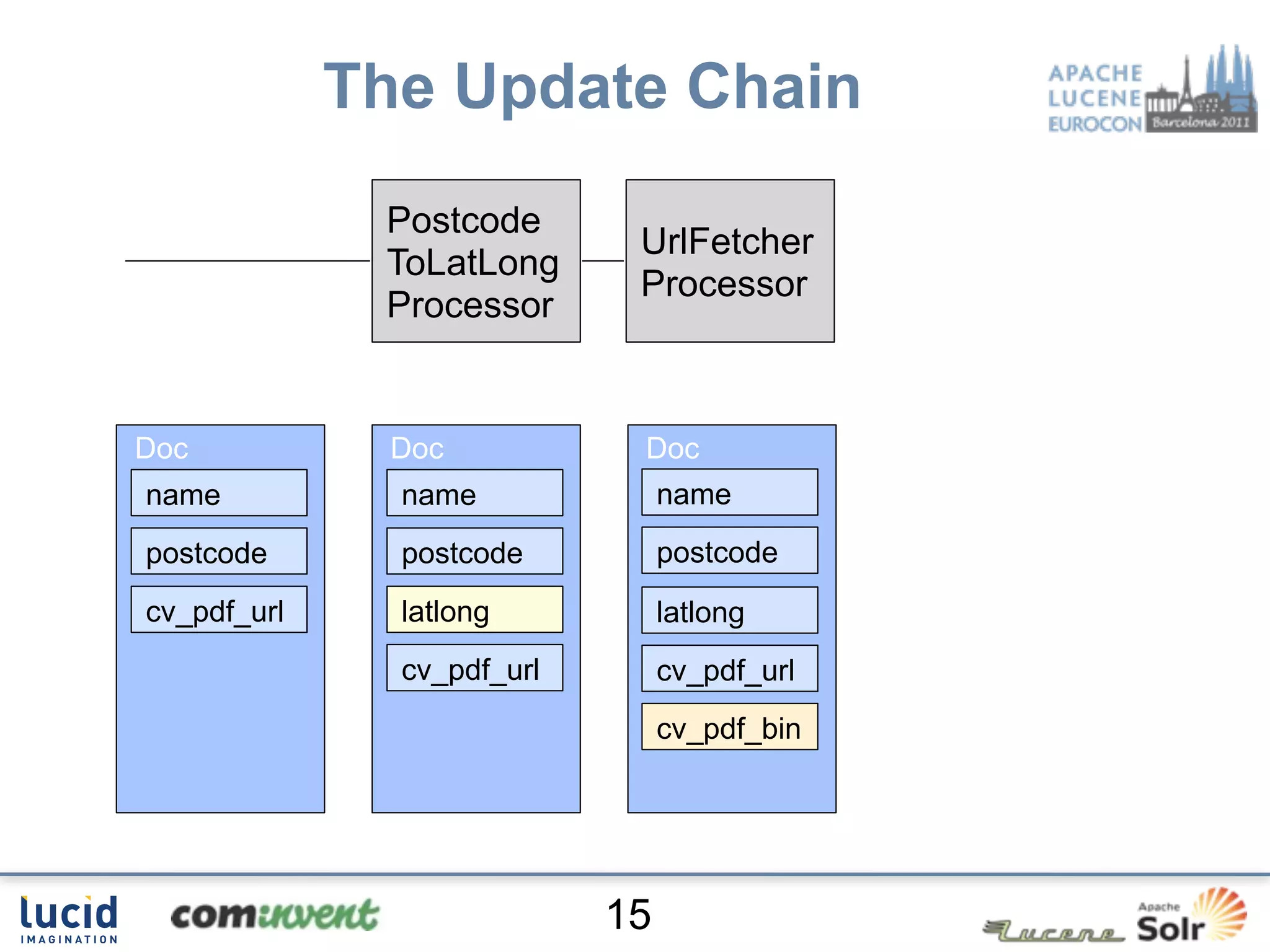
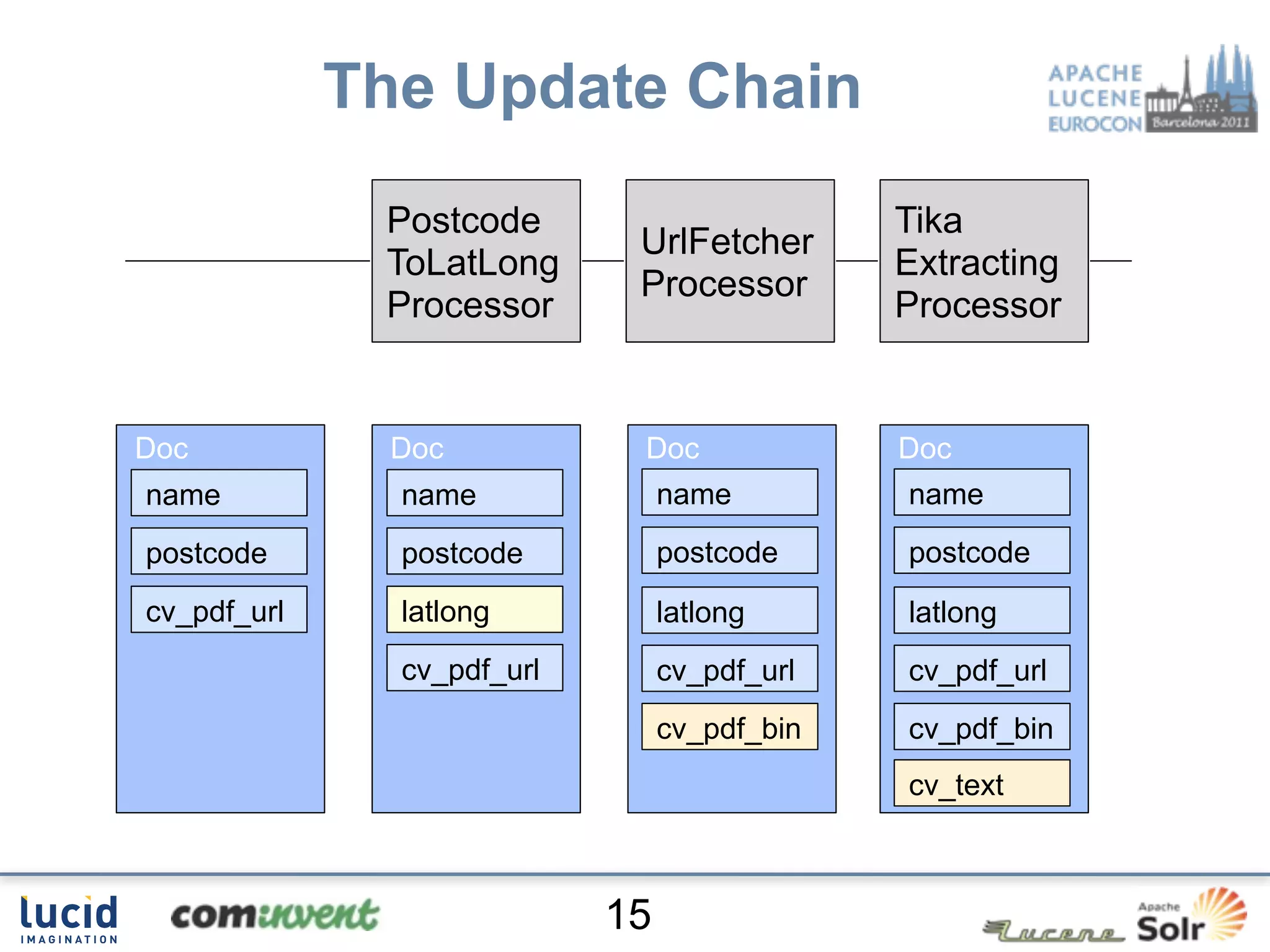
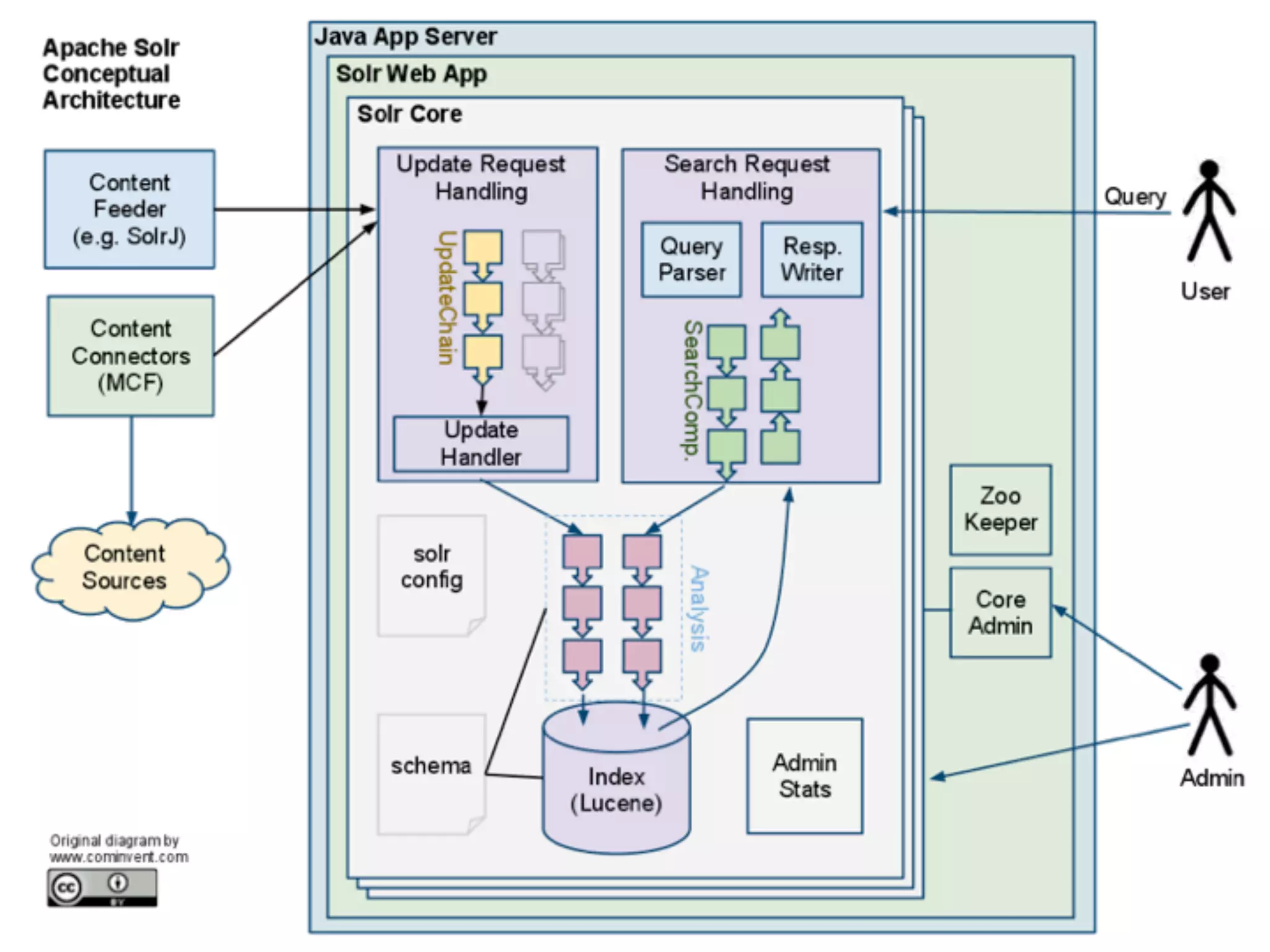
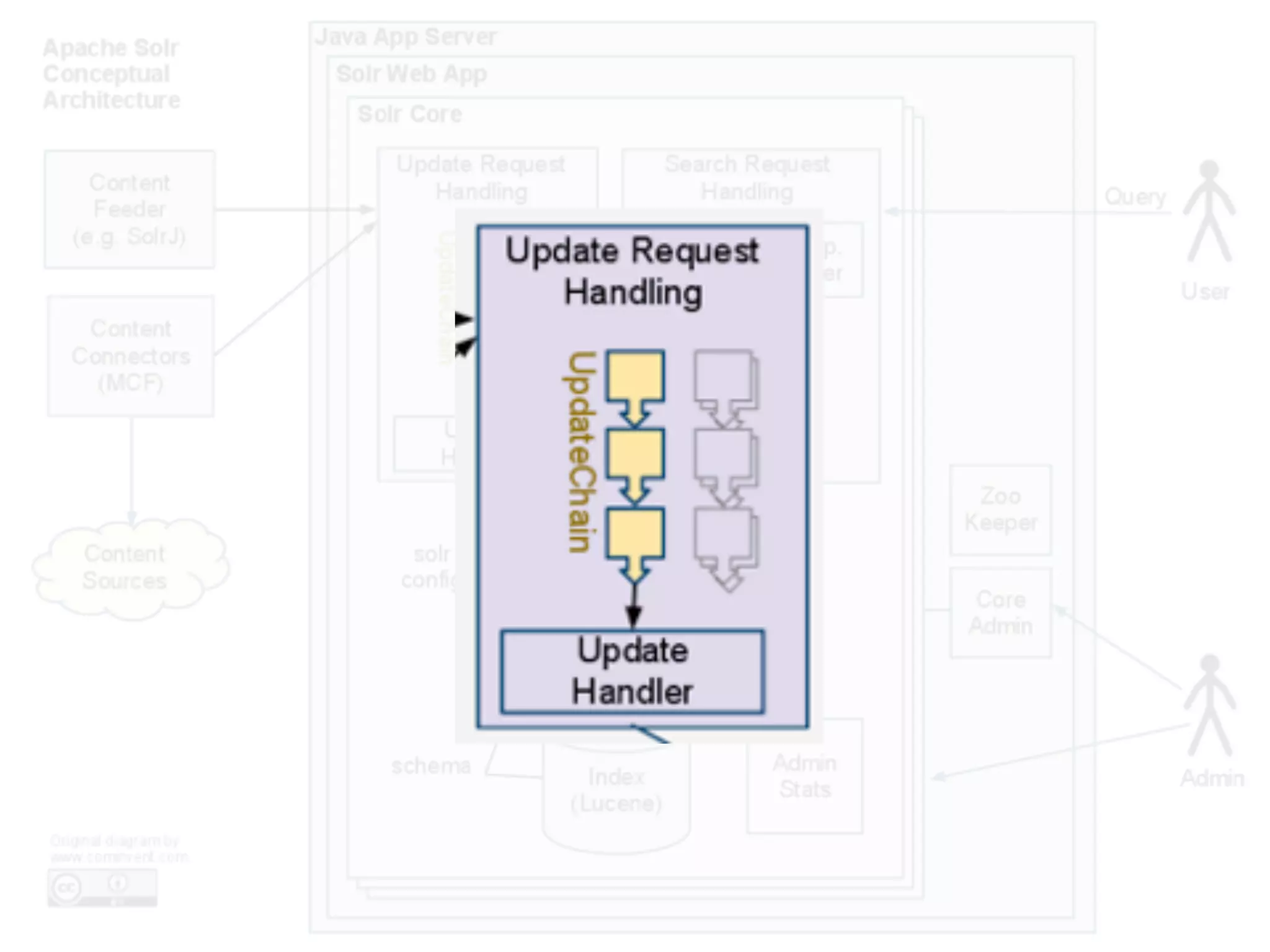
Jan Høydahl presents an overview of Solr's update chain, discussing document processing challenges and the creation of custom update processors. He highlights examples, including a web crawl project at Oslo University, and addresses potential improvements for the update chain's efficiency and flexibility. The presentation concludes with a summary of benefits and the need for additional processors.
































































































