Downloaded 86 times











![Scheduling Controlled | Volumes
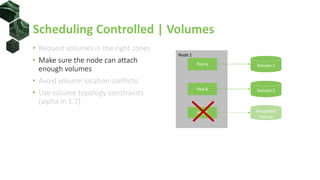
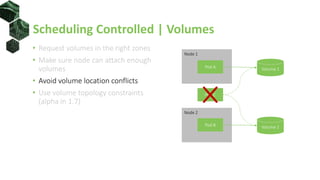
• Request volumes in the right zones
• Make sure node can attach enough
volumes
• Avoid volume location conflicts
• Use volume topology constraints
(alpha in 1.7)
annotations:
"volume.alpha.kubernetes.io/node-affinity": '{
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [{
"matchExpressions": [{
"key": "kubernetes.io/hostname",
"operator": "In",
"values": ["docker03"]
}]
}]
}}'](https://image.slidesharecdn.com/201802schedulingink8s-180228155243/85/Implement-Advanced-Scheduling-Techniques-in-Kubernetes-29-320.jpg)









![Scheduling Controlled | Pod Affinity Terms
• topologyKey – nodes’ label key defining co-location
• labelSelector and namespaces – select group of pods
<pod affinity term>:
topologyKey: <topology label key>
namespaces: [ <namespace>, ... ]
labelSelector:
matchLabels:
<label key>: <label value>
...
matchExpressions:
- key: <label key>
operator: In | NotIn | Exists | DoesNotExist
values: [ <value 1>, ... ]
...](https://image.slidesharecdn.com/201802schedulingink8s-180228155243/85/Implement-Advanced-Scheduling-Techniques-in-Kubernetes-39-320.jpg)



![Default Scheduler | Custom Policy Config
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "PodFitsHostPorts"},
...
{"name" : "HostName"}
],
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 1},
...
{"name" : "EqualPriority", "weight" : 1}
],
"hardPodAffinitySymmetricWeight" : 10,
"alwaysCheckAllPredicates" : false
}](https://image.slidesharecdn.com/201802schedulingink8s-180228155243/85/Implement-Advanced-Scheduling-Techniques-in-Kubernetes-44-320.jpg)
![Default Scheduler | Scheduler Extender
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [...],
"priorities" : [...],
"extenders" : [{
"urlPrefix": "http://127.0.0.1:12346/scheduler",
"filterVerb": "filter",
"bindVerb": "bind",
"prioritizeVerb": "prioritize",
"weight": 5,
"enableHttps": false,
"nodeCacheCapable": false
}],
"hardPodAffinitySymmetricWeight" : 10,
"alwaysCheckAllPredicates" : false
}](https://image.slidesharecdn.com/201802schedulingink8s-180228155243/85/Implement-Advanced-Scheduling-Techniques-in-Kubernetes-45-320.jpg)






![Use Case | Distributed Pods
apiVersion: v1
kind: Pod
metadata:
name: db-replica-3
labels:
component: db
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: component
operator: In
values: [ "db" ]
Node 2
db-replica-2
Node 1
Node 3
db-replica-1
db-replica-3](https://image.slidesharecdn.com/201802schedulingink8s-180228155243/85/Implement-Advanced-Scheduling-Techniques-in-Kubernetes-52-320.jpg)
![Use Case | Co-located Pods
apiVersion: v1
kind: Pod
metadata:
name: app-replica-1
labels:
component: web
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: component
operator: In
values: [ "db" ]
Node 2
db-replica-2
Node 1
Node 3
db-replica-1
app-replica-1](https://image.slidesharecdn.com/201802schedulingink8s-180228155243/85/Implement-Advanced-Scheduling-Techniques-in-Kubernetes-53-320.jpg)





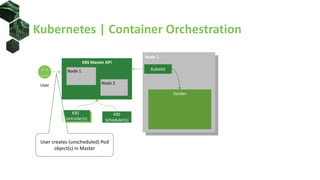
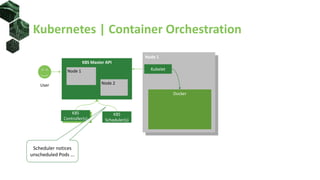
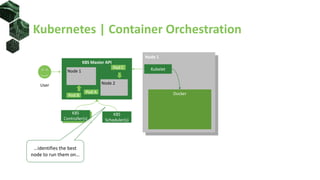
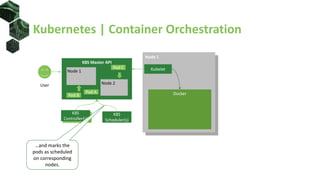
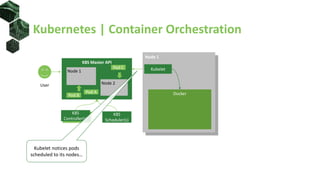
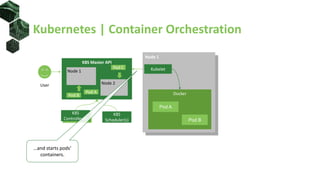
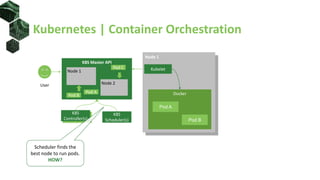
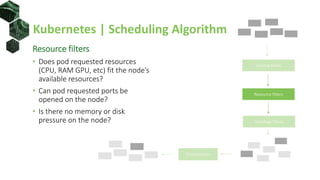
The document discusses advanced scheduling techniques in Kubernetes, detailing the scheduling algorithm, controls, and various strategies for optimizing pod placement within a cluster. It covers aspects such as resource filters, volume constraints, node affinity, taints, and tolerations, providing examples and recommendations for effective scheduling. Overall, it emphasizes the importance of resource requests and inter-pod affinity while suggesting customization options for schedulers.



















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

