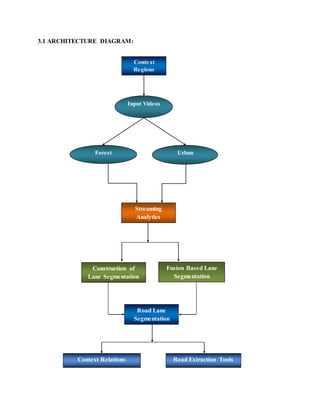
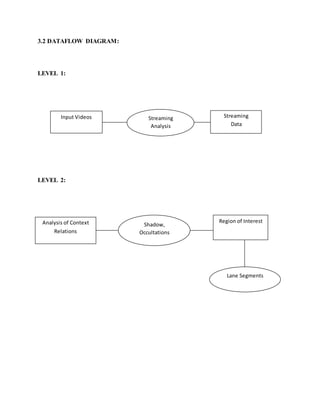
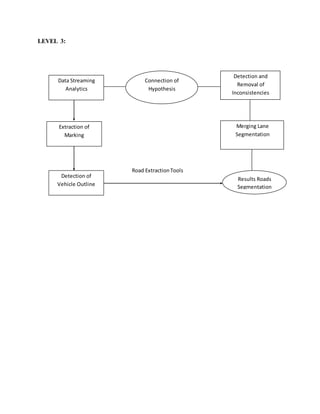
This document discusses the development of internal quality measures for automatic road extraction from aerial images in urban environments, focusing on the reliability of results through self-diagnosis. It explores various techniques for automatic extraction, including gestalt principles and dynamical systems, while addressing the complexities of urban scenes. The proposed approach integrates a detailed road and context model to capture the varying appearances and influences of background objects, emphasizing the necessity for high-quality input data.