Download as PDF, PPTX




![insert({ cf1: { row1: { col3: foo } } })
Client Cassandra
On-Disk Node Commit Log
{ cf1: { row1: { col1: abc } } }
In-Memory Memtable for “cf1”
{ cf1: { row1: { col2: def } } }
{ cf1: { row1: { col1: <del> } } }
row1 col1: [del] col2: “def” col3: “foo”
{ cf1: { row2: { col1: xyz } } }
row2 col1: “xyz”
{ cf1: { row1: { col3: foo } } }
COMMIT](https://image.slidesharecdn.com/cassandra-and-solid-state-drives-120316005056-phpapp02/75/Cassandra-and-Solid-State-Drives-5-2048.jpg)
![In-Memory Memtable for “cf1”
row1 col1: [del] col2: “def” col3: “foo”
row2 col1: “xyz”
SSTable SSTable SSTable SSTable
1 2 3 4
FLUSH](https://image.slidesharecdn.com/cassandra-and-solid-state-drives-120316005056-phpapp02/75/Cassandra-and-Solid-State-Drives-6-2048.jpg)














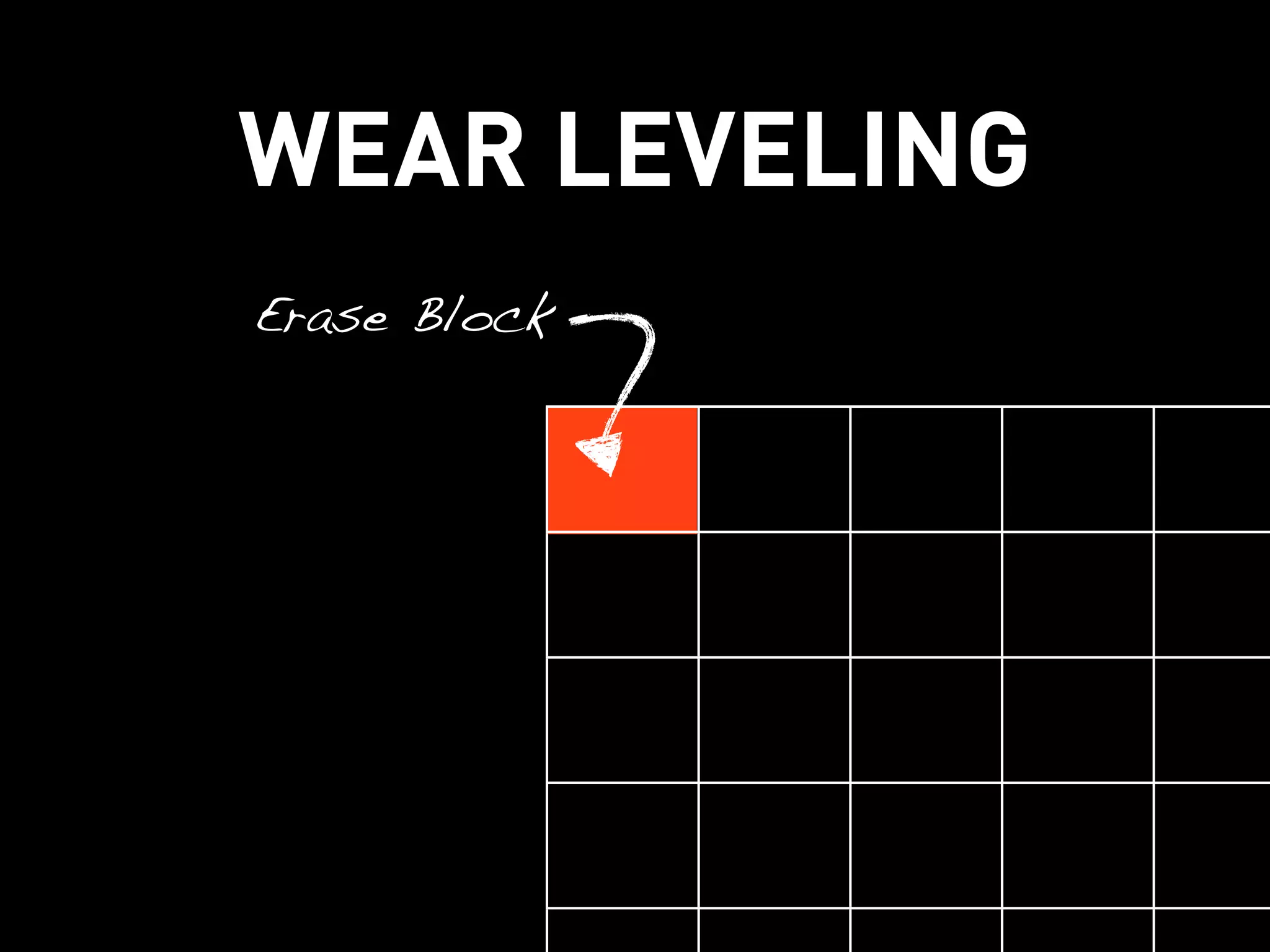


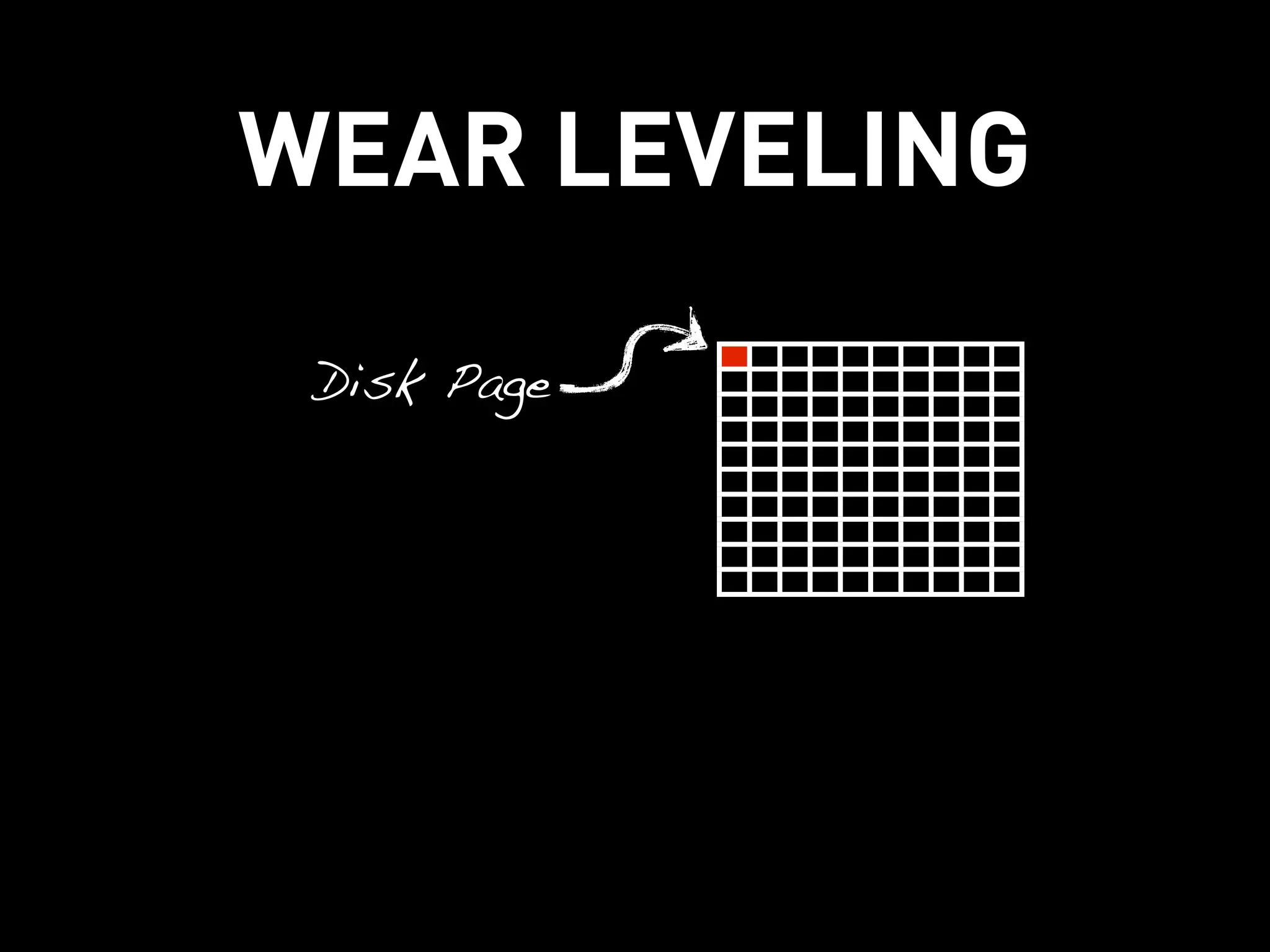
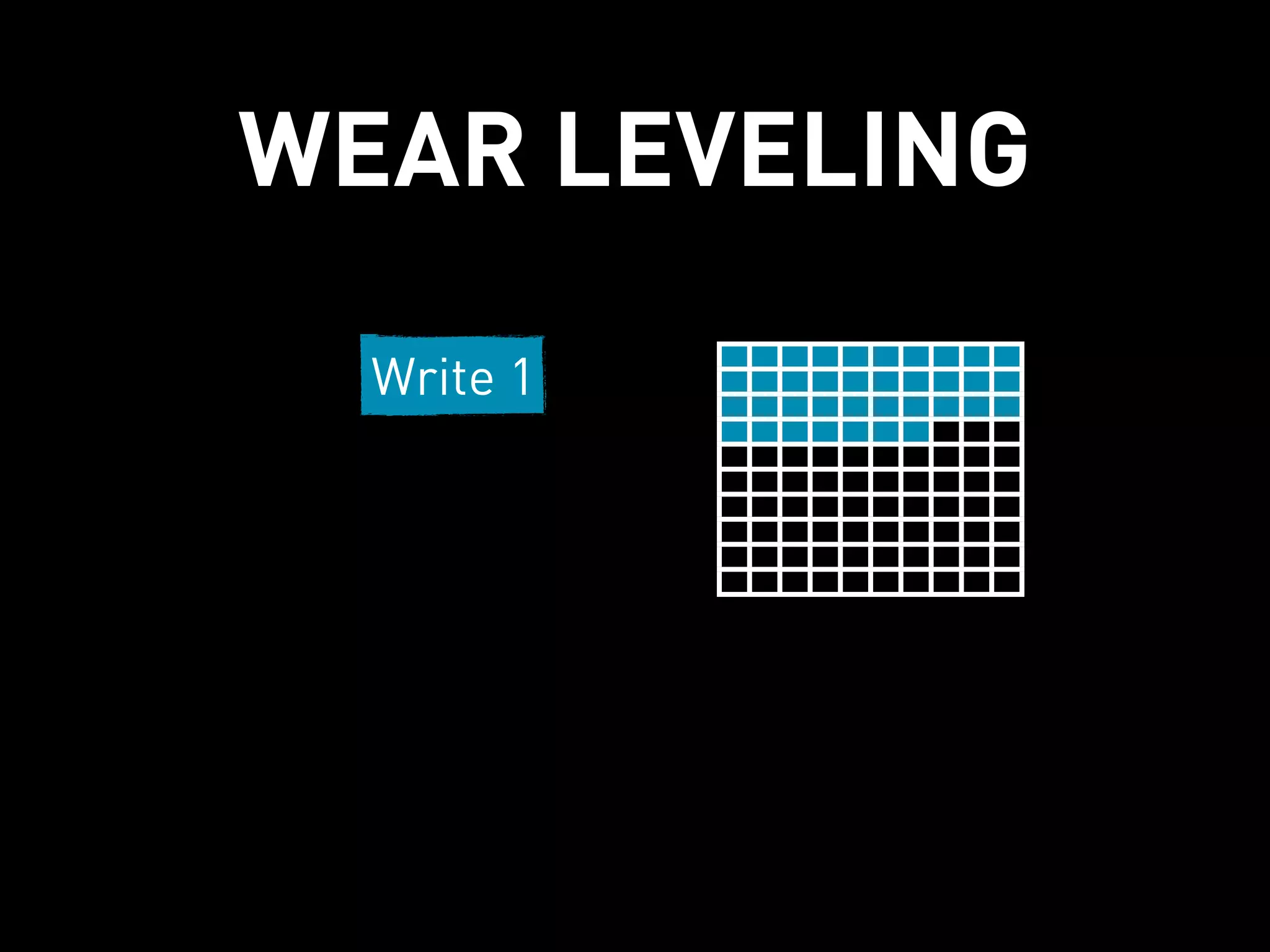
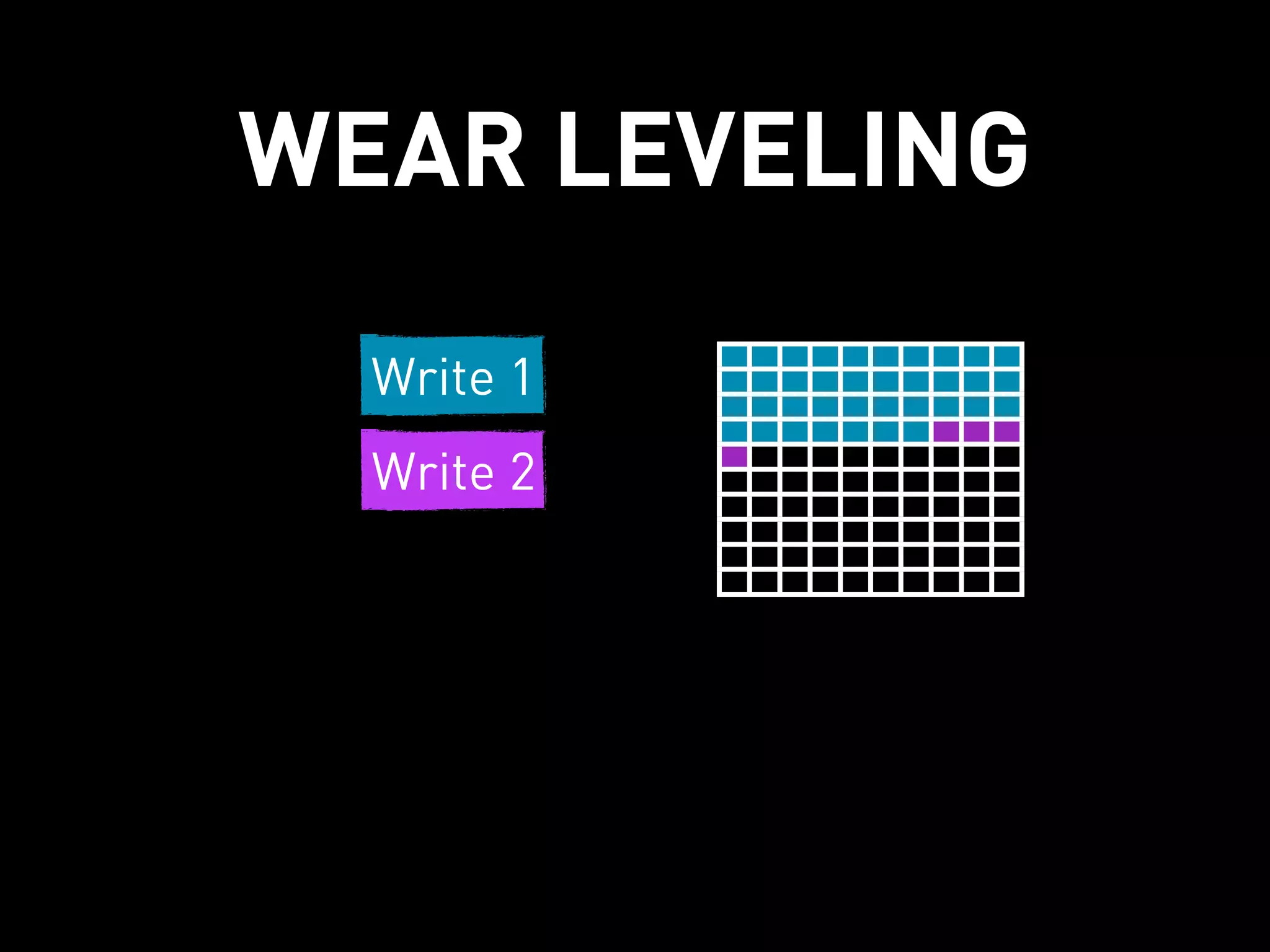
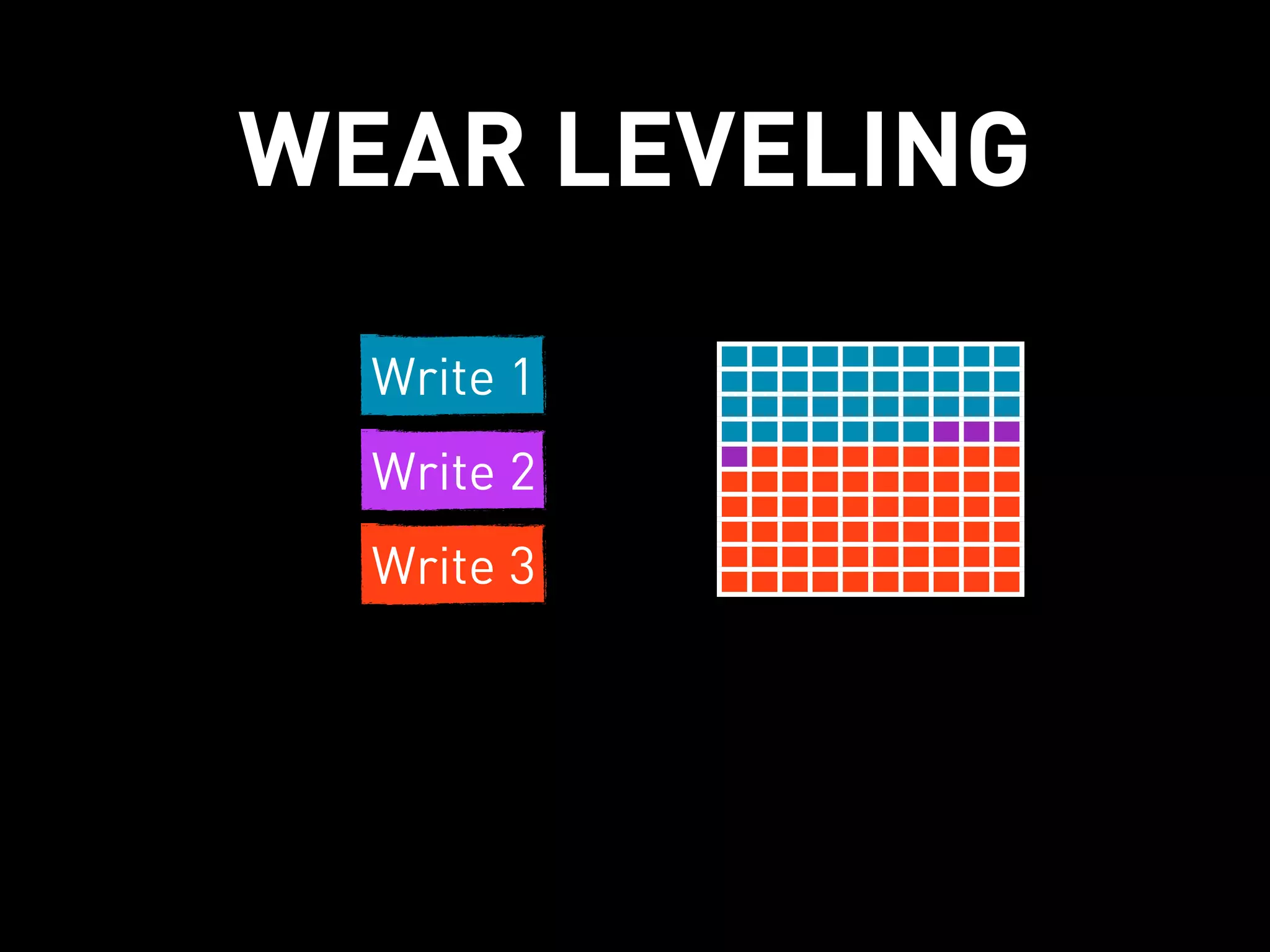









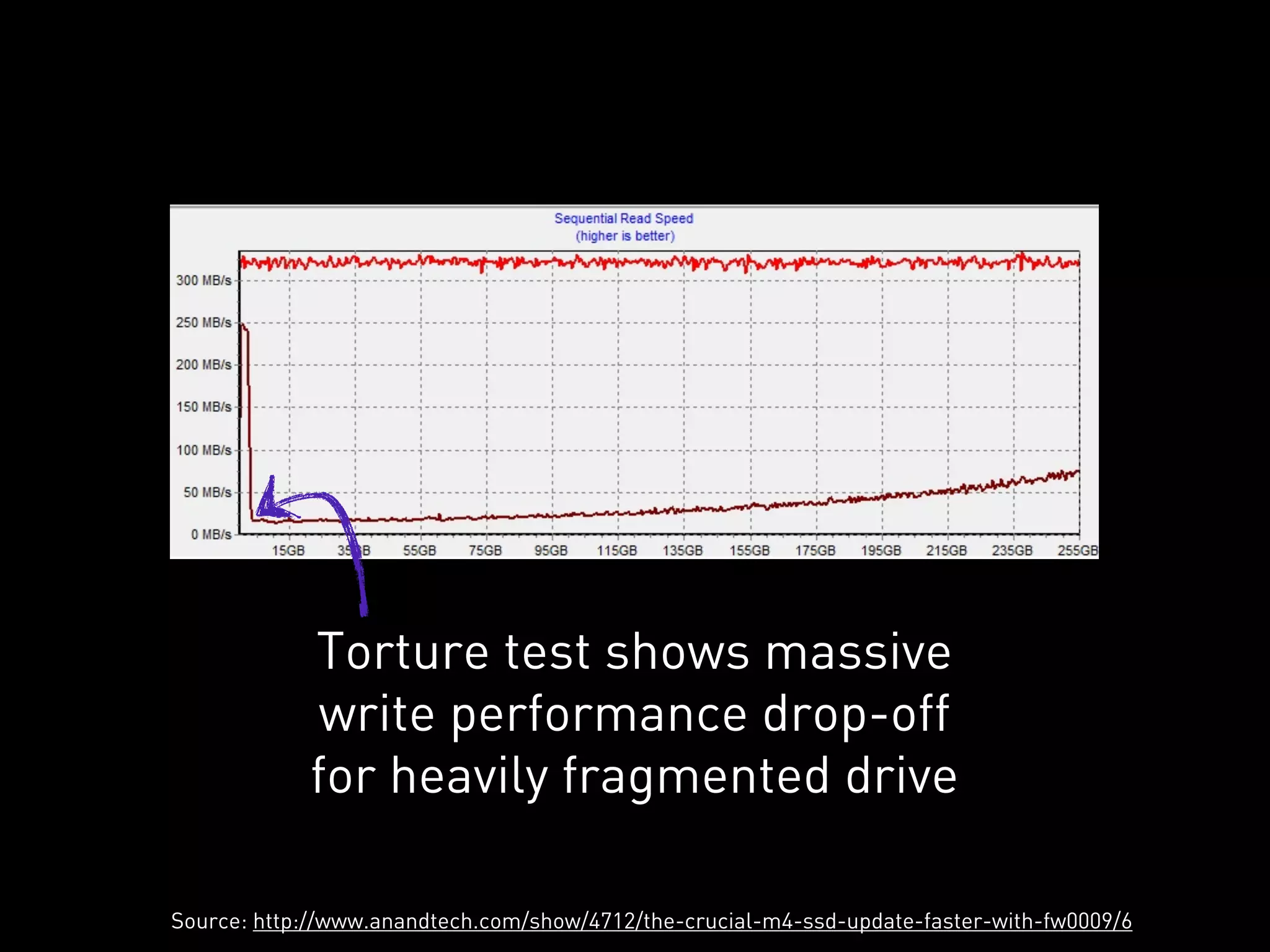
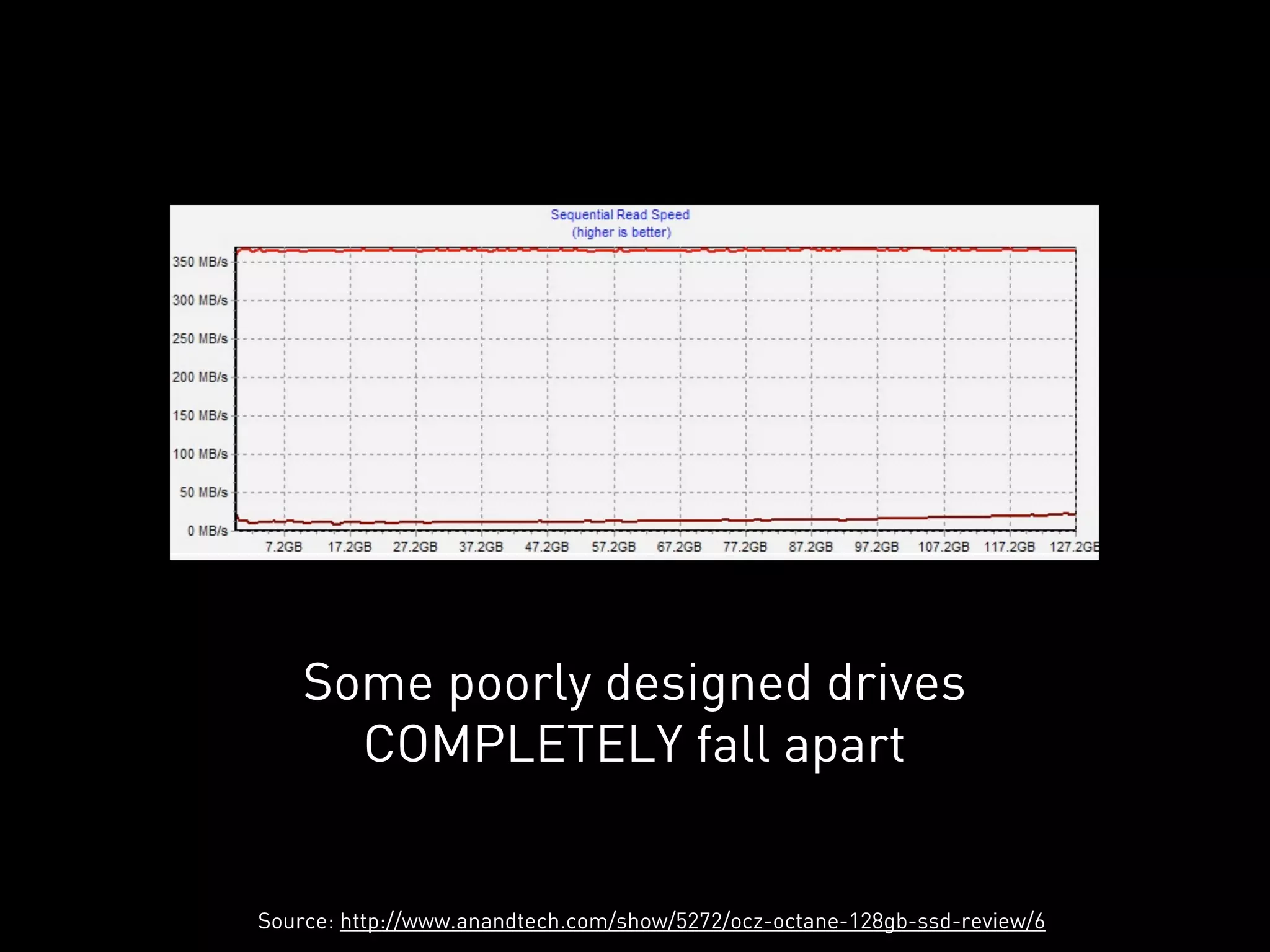
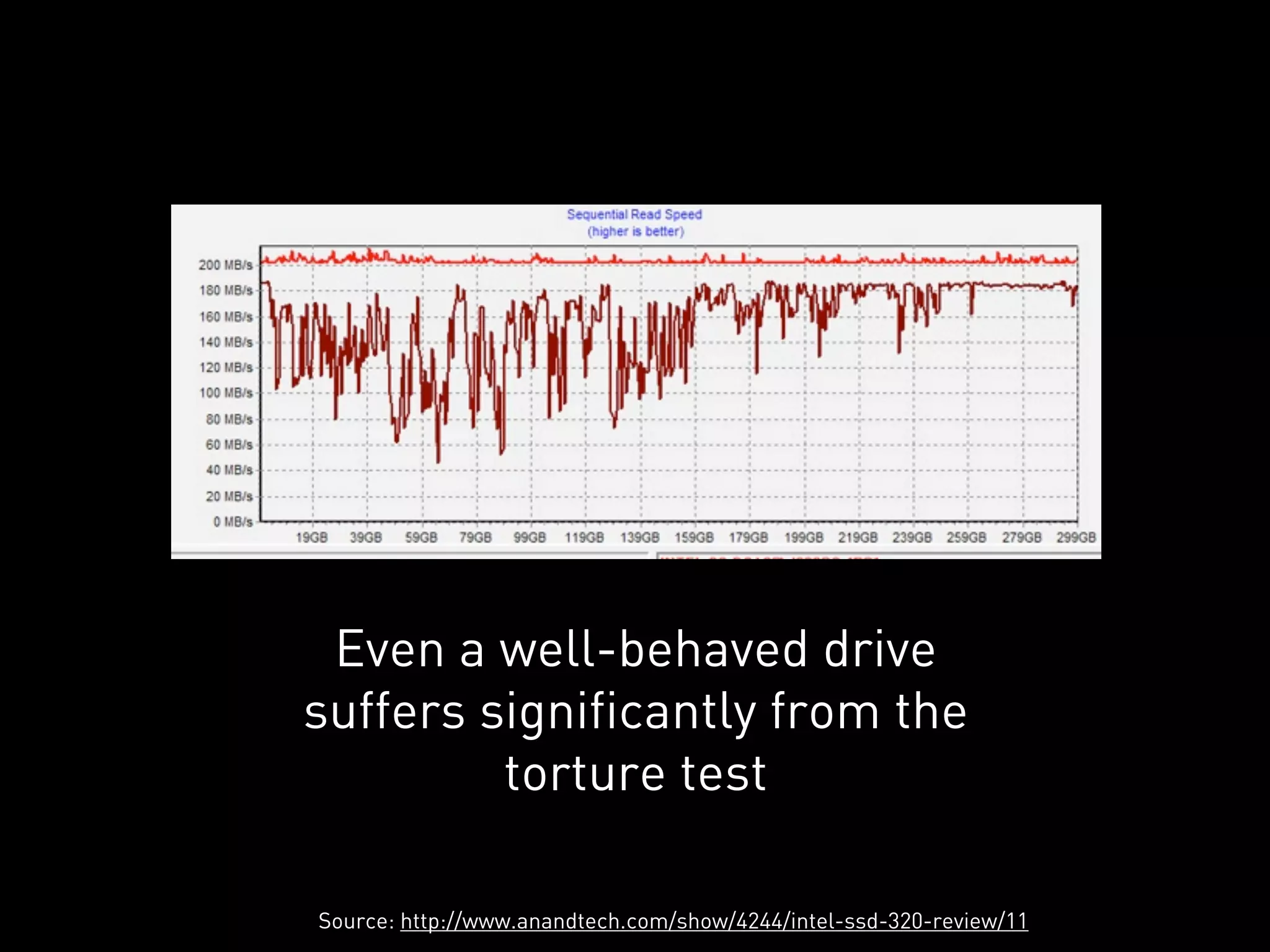
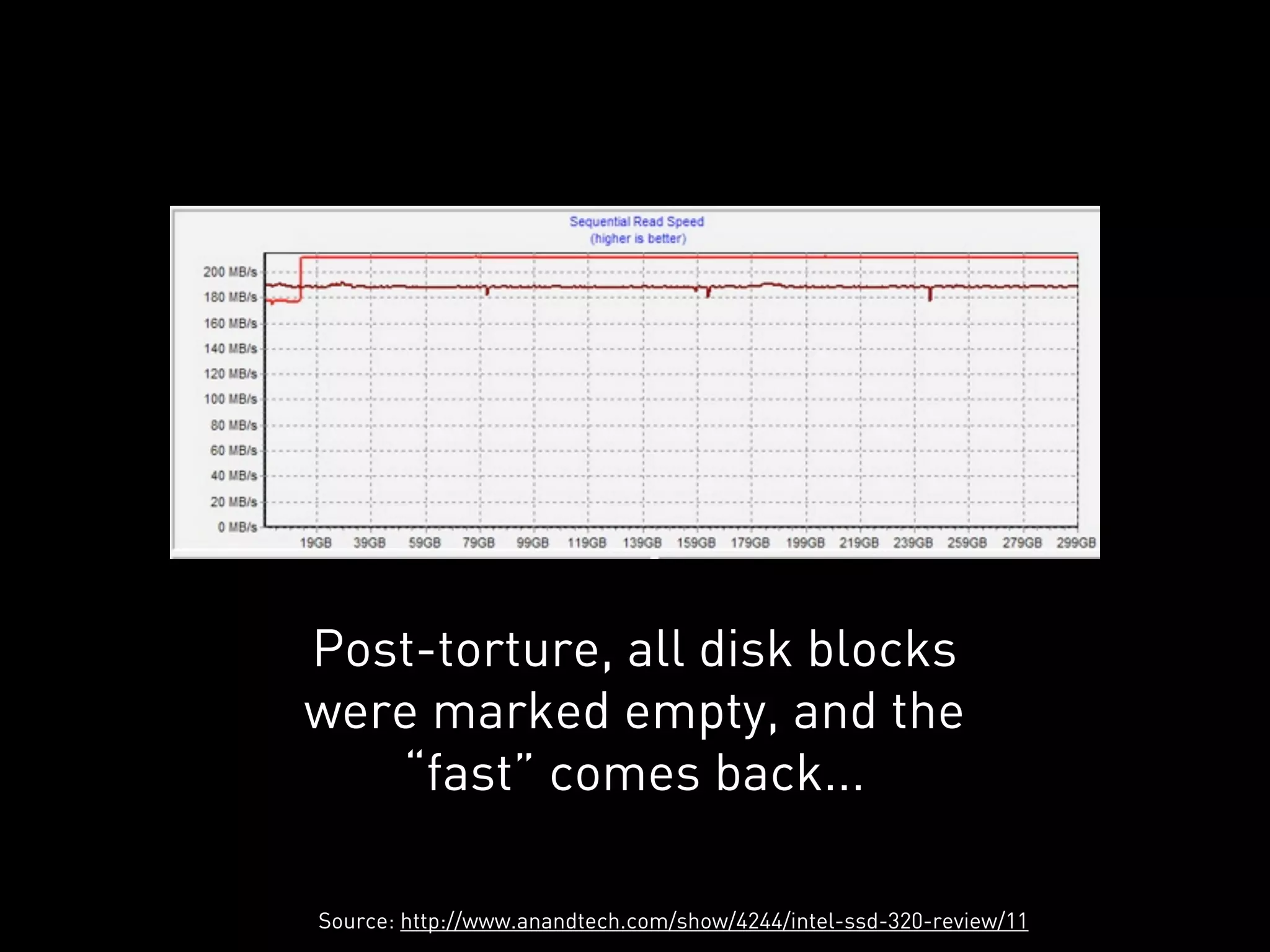




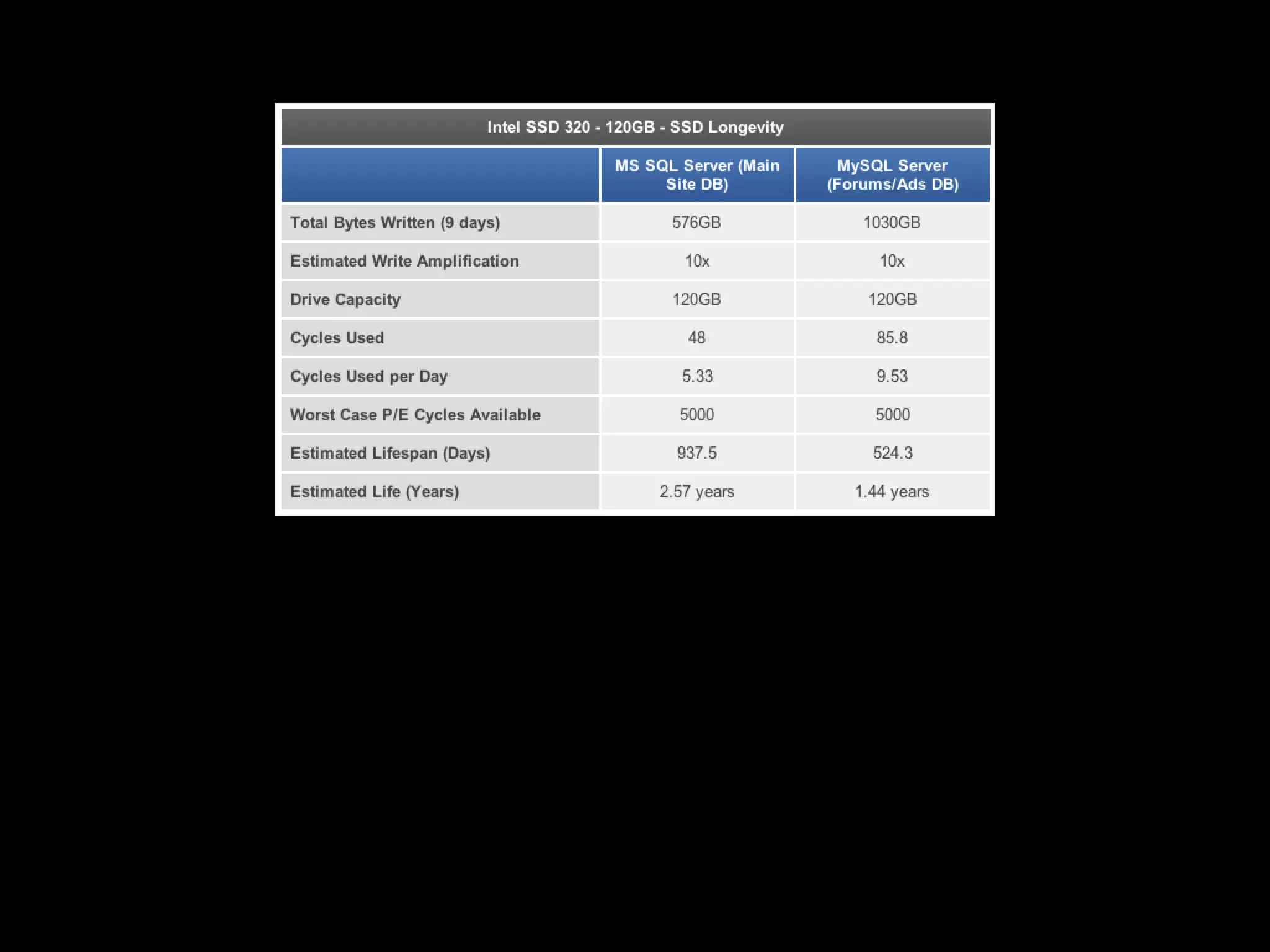
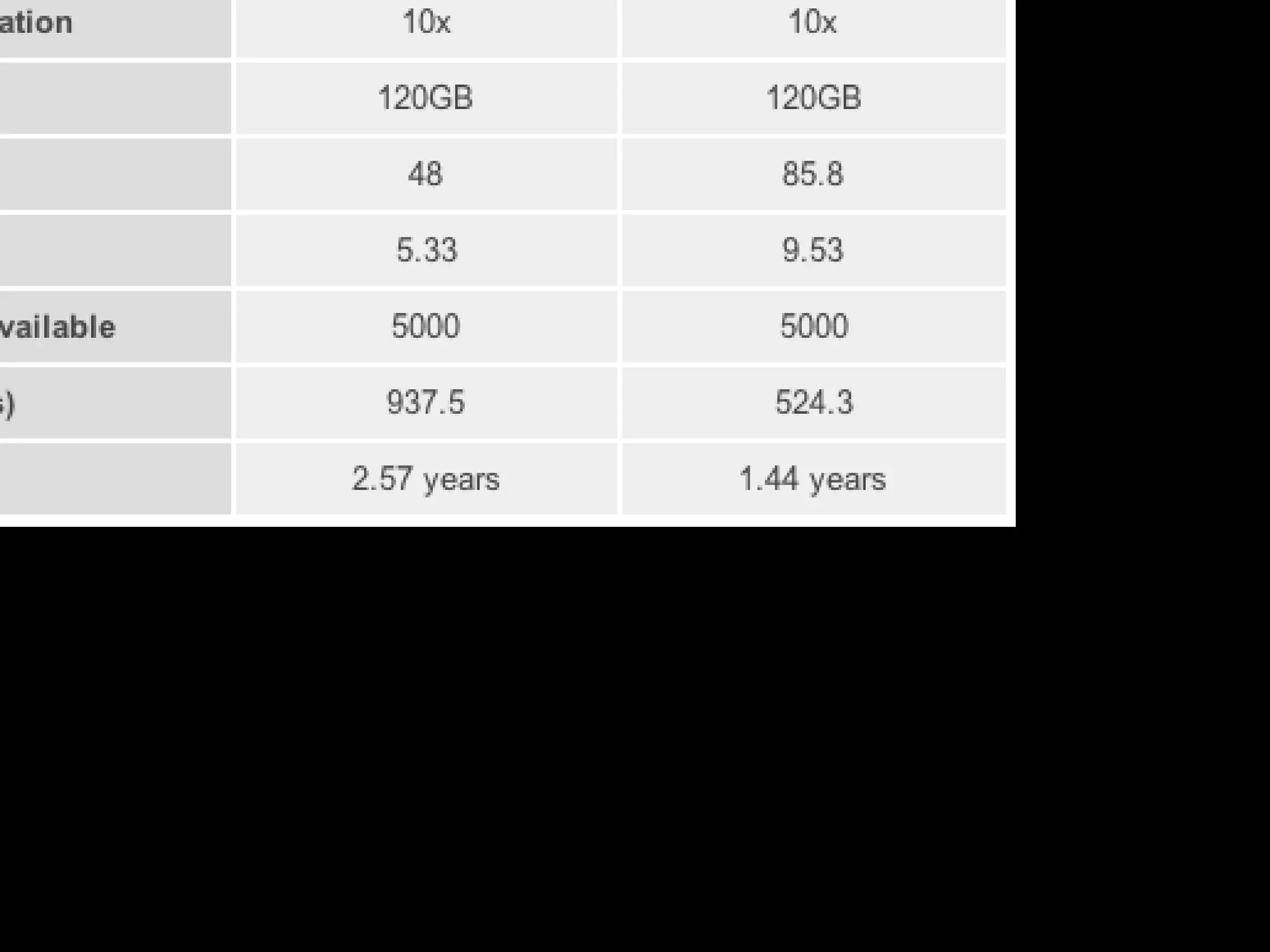







This document discusses how Cassandra's storage engine was optimized for spinning disks but remains well-suited for solid state drives. It describes how Cassandra uses LSM trees with sequential, append-only writes to disks, avoiding the random read/write patterns that cause issues for SSDs like write amplification and reduced lifetime from excessive garbage collection. While SSDs have benefits like fast random access, Cassandra's design circumvents problems they were meant to solve, keeping write amplification close to 1 and leveraging SSDs' fast sequential throughput.

















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















