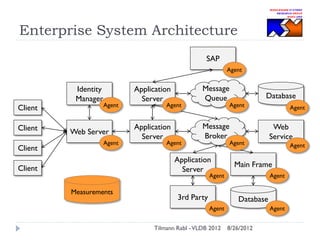
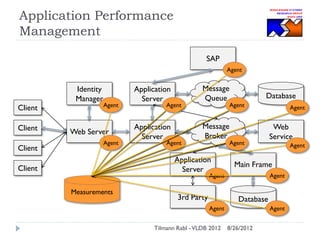
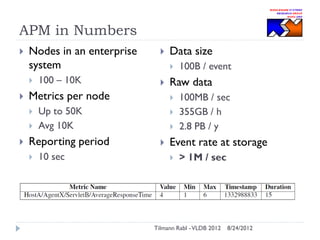
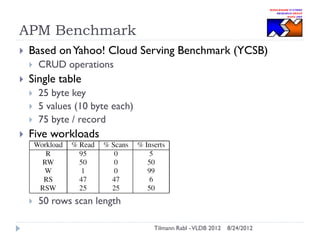
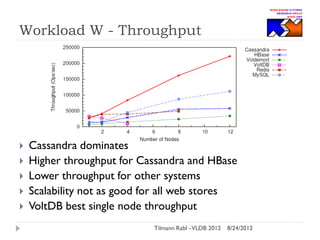
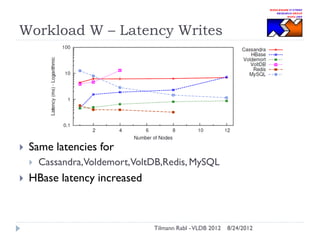
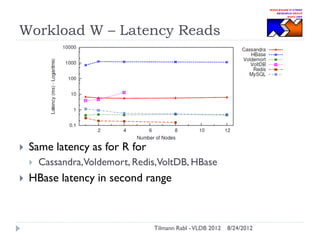
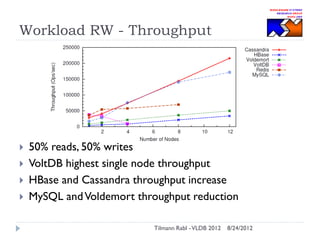
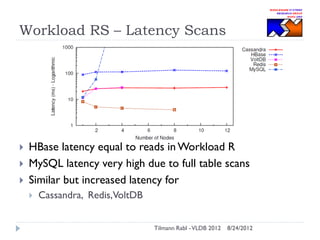
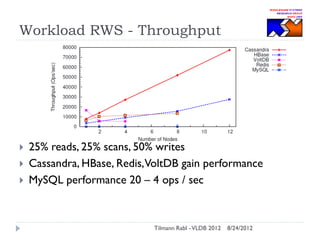
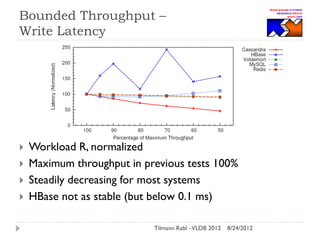
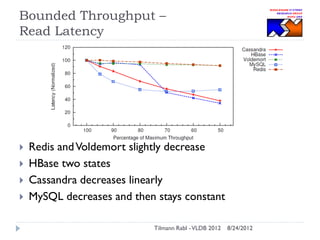
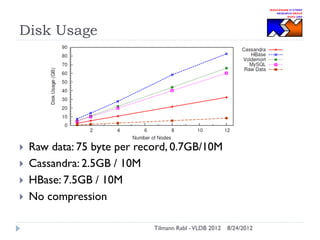
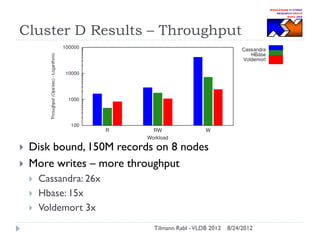
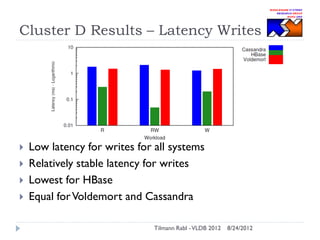
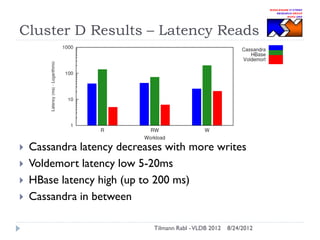
The document discusses research conducted by the Middleware Systems Research Group on application performance management (APM) for big data challenges, detailing benchmarks and results from various systems like Cassandra, HBase, and MySQL. The benchmarks indicate specific performance metrics regarding throughput and latency across different workloads, illustrating how systems behave under load and their scalability. Conclusions drawn highlight that while Cassandra meets many APM workload requirements, further enhancements are needed to ensure reliable performance in enterprise environments.