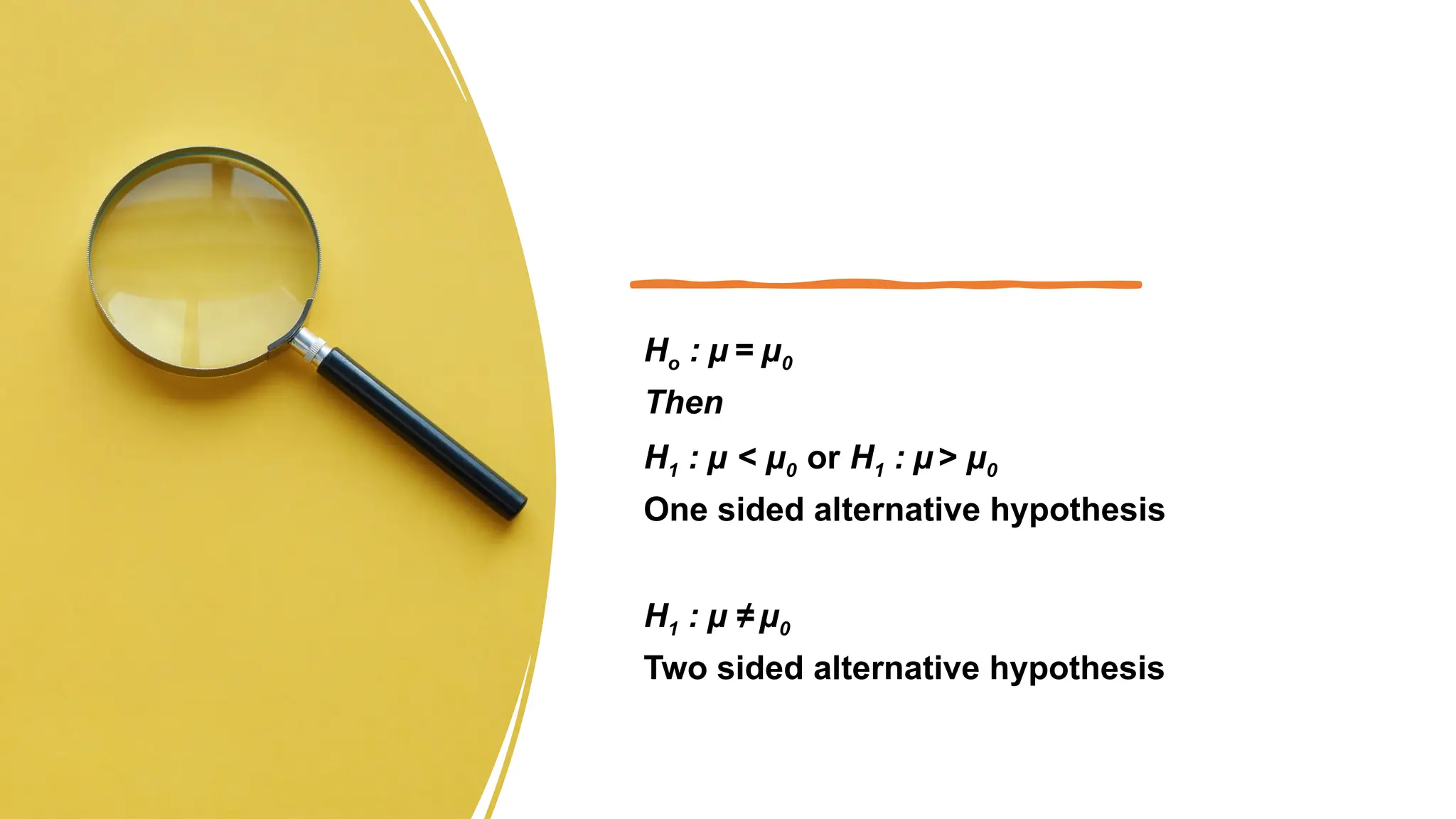
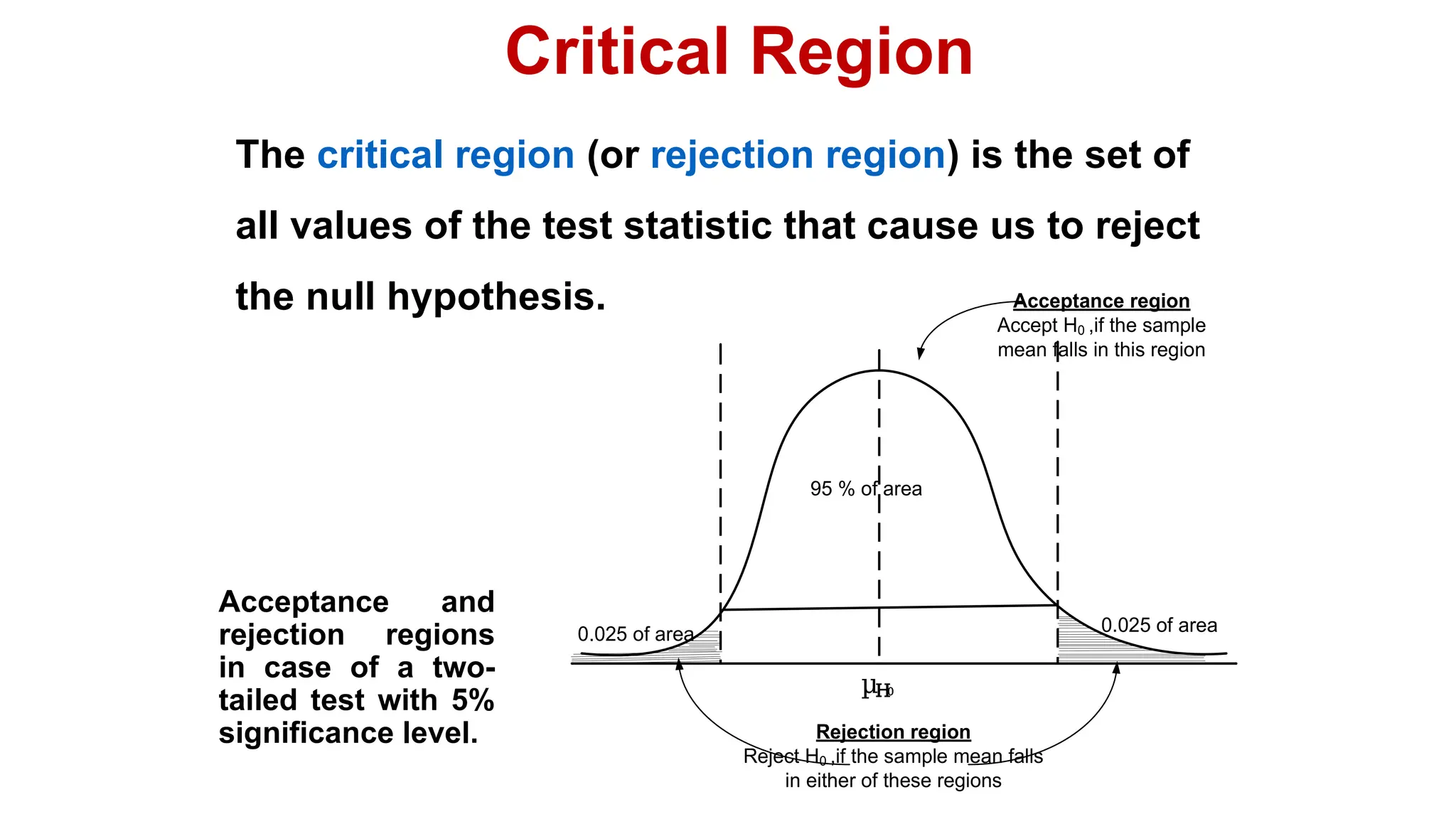
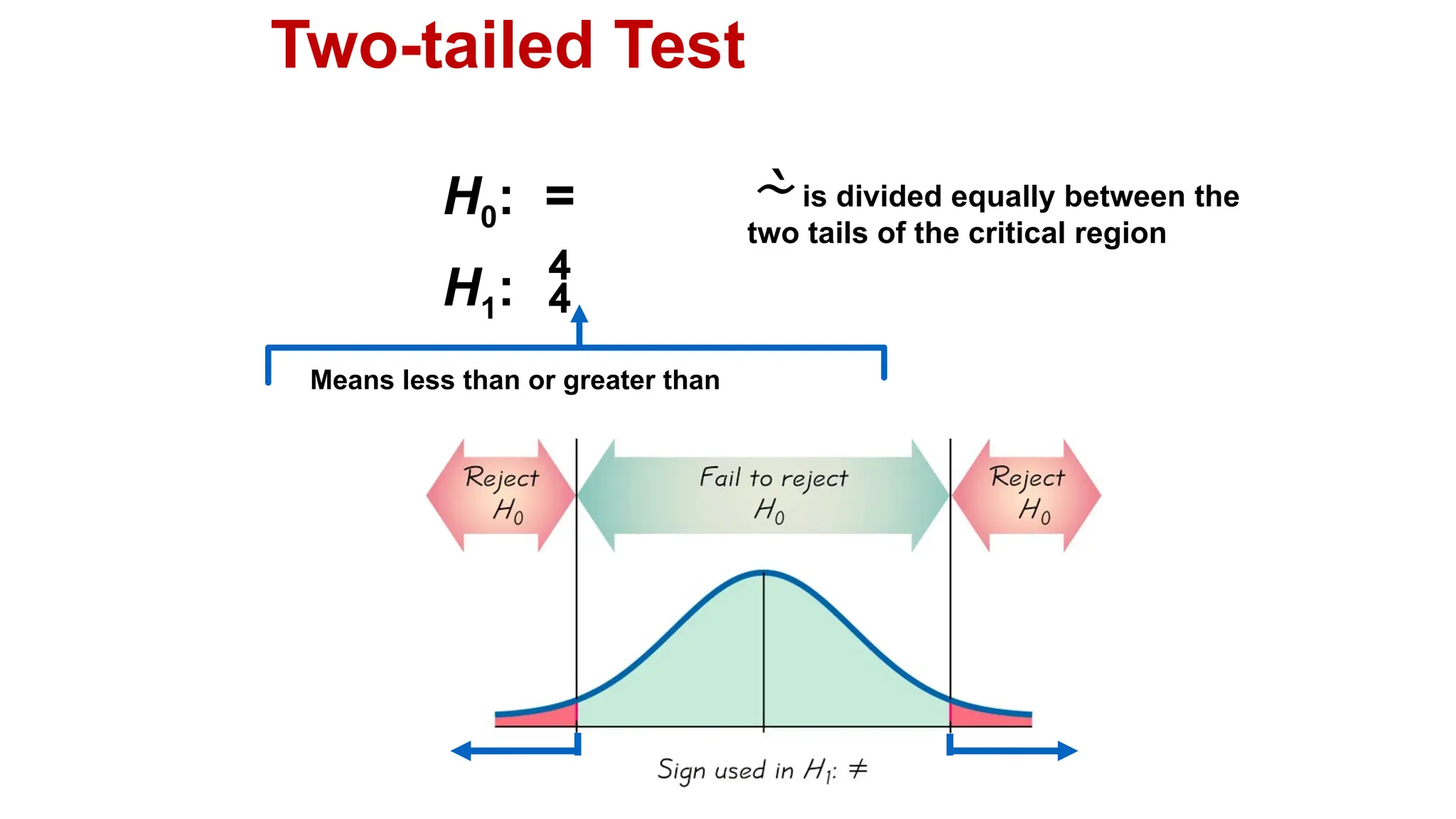
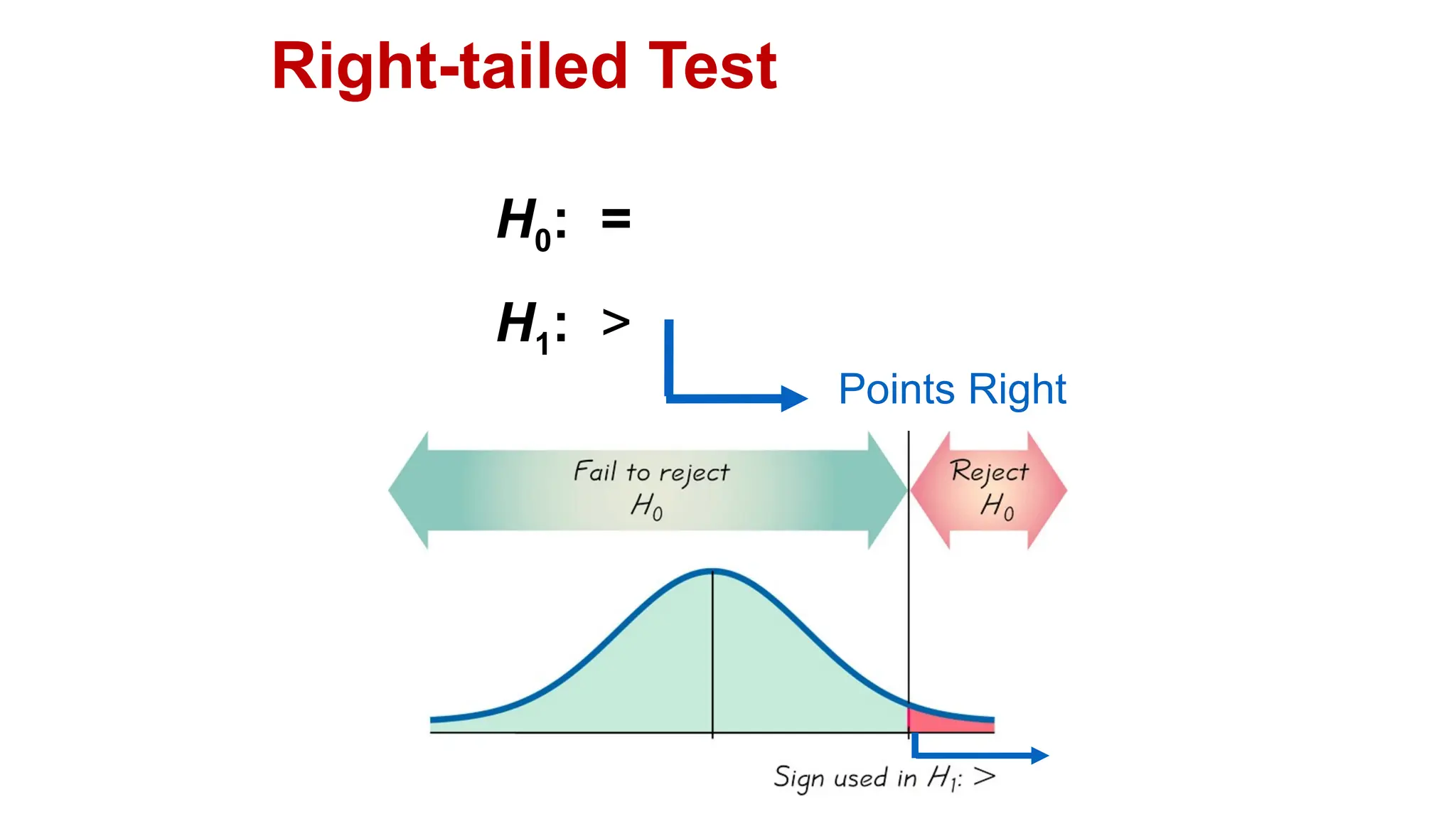
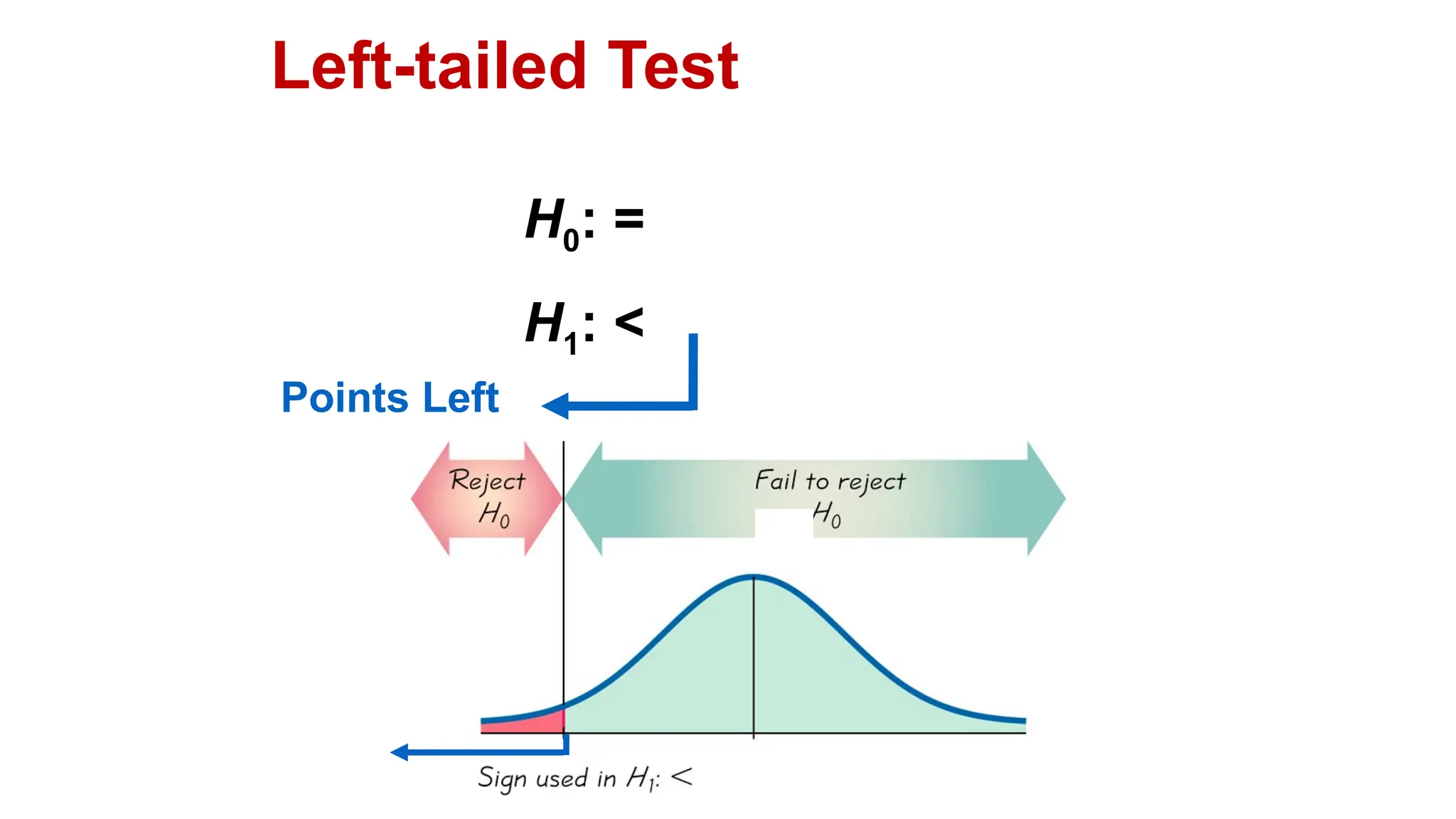
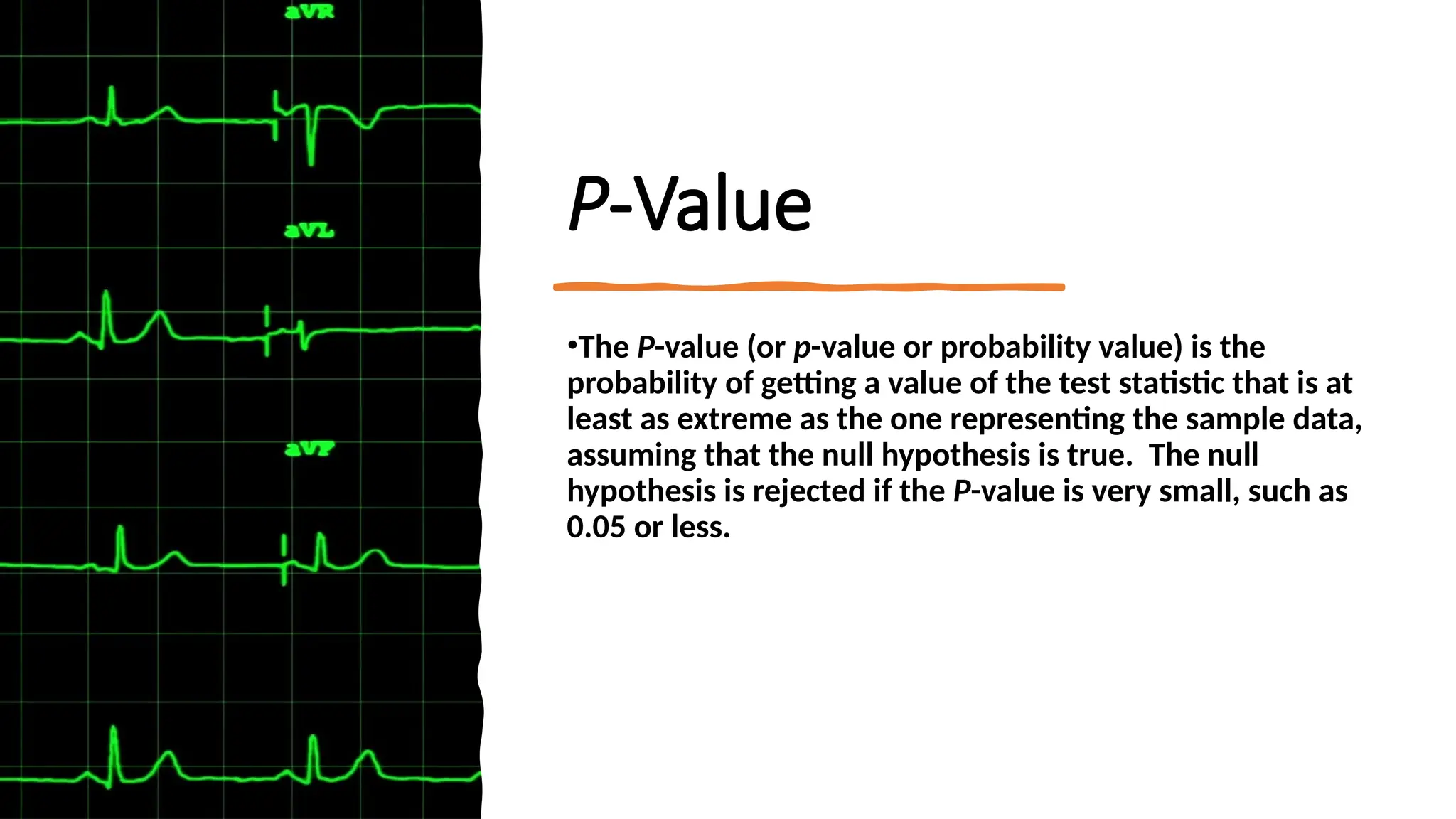
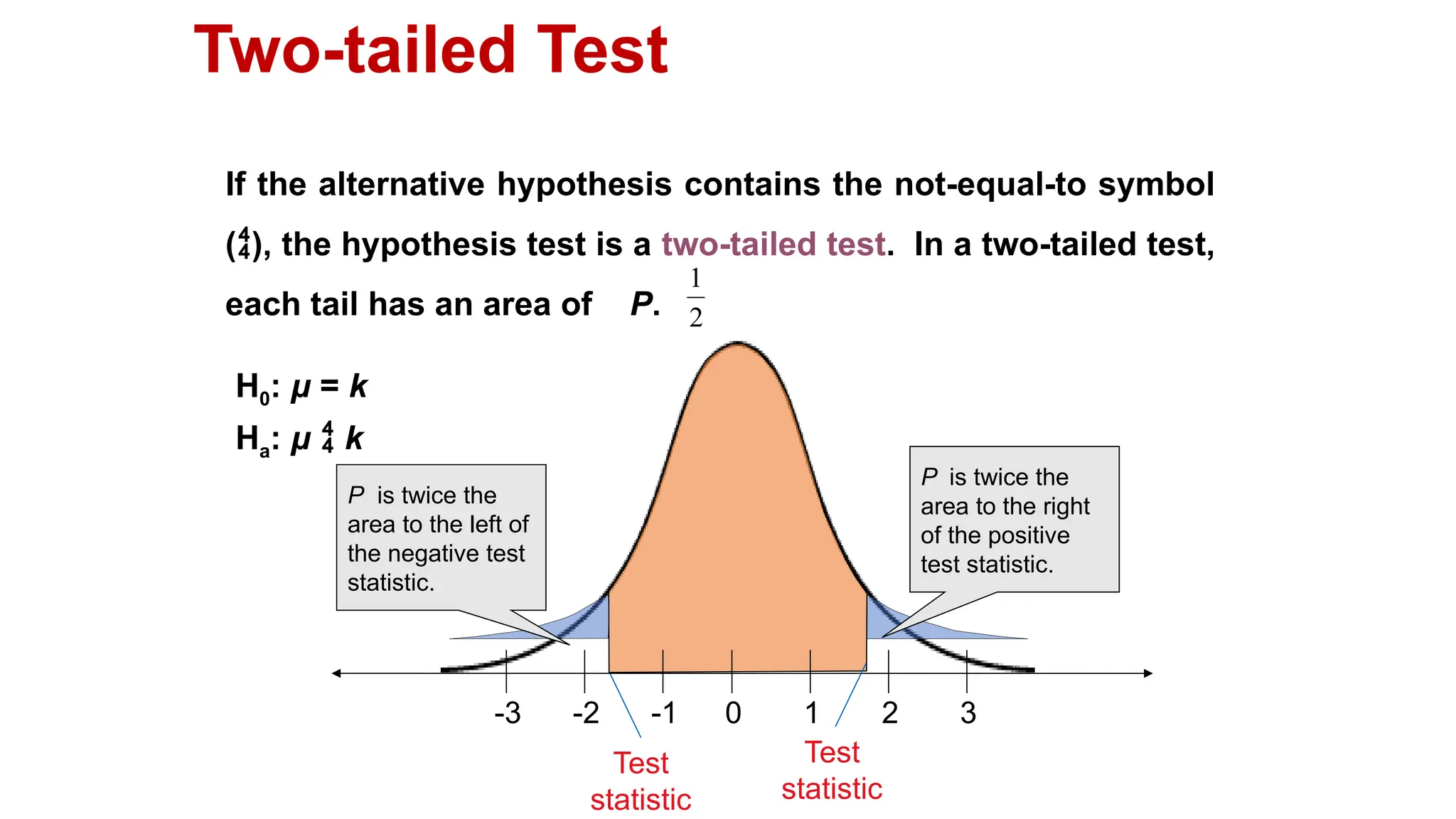
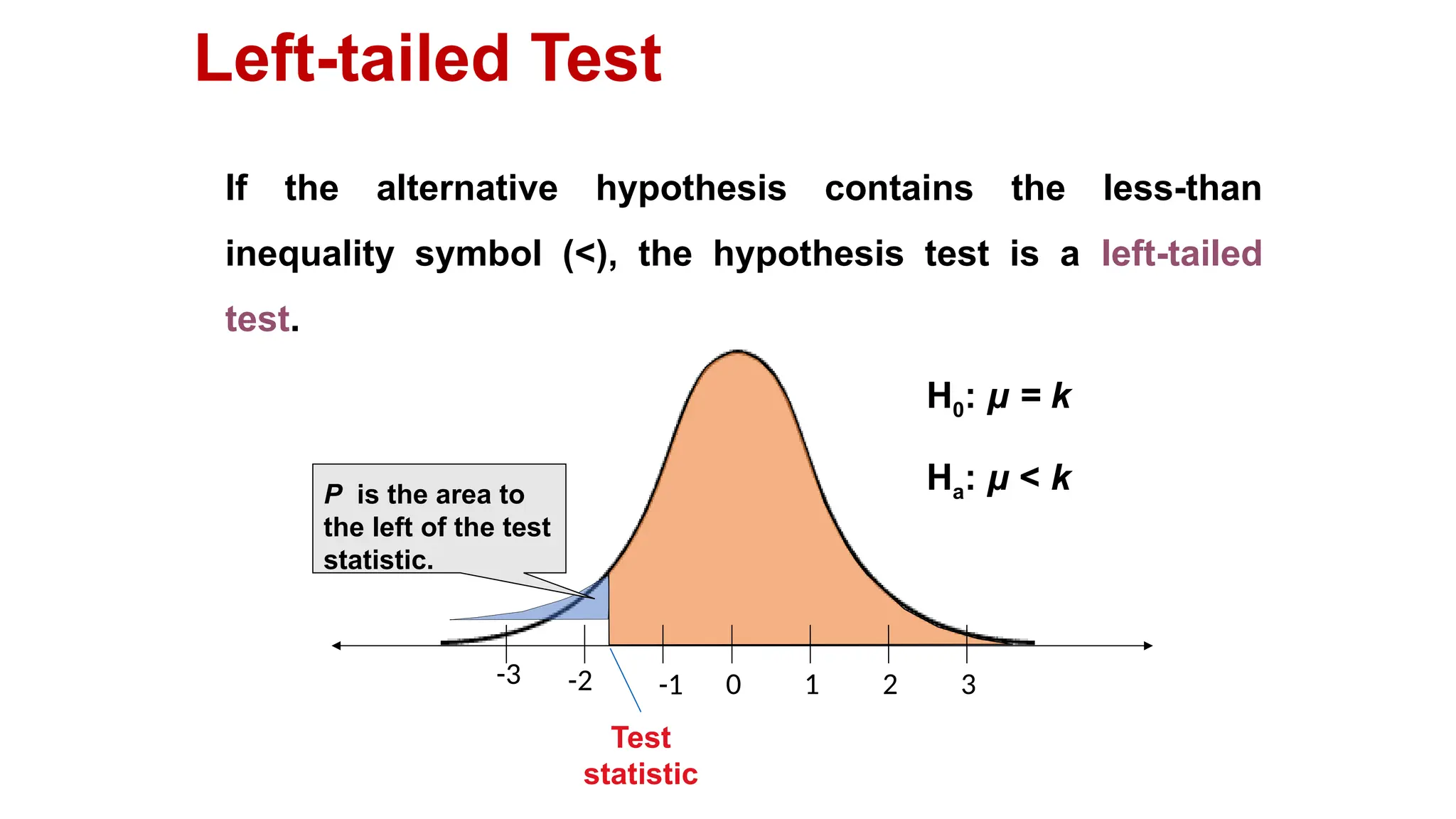
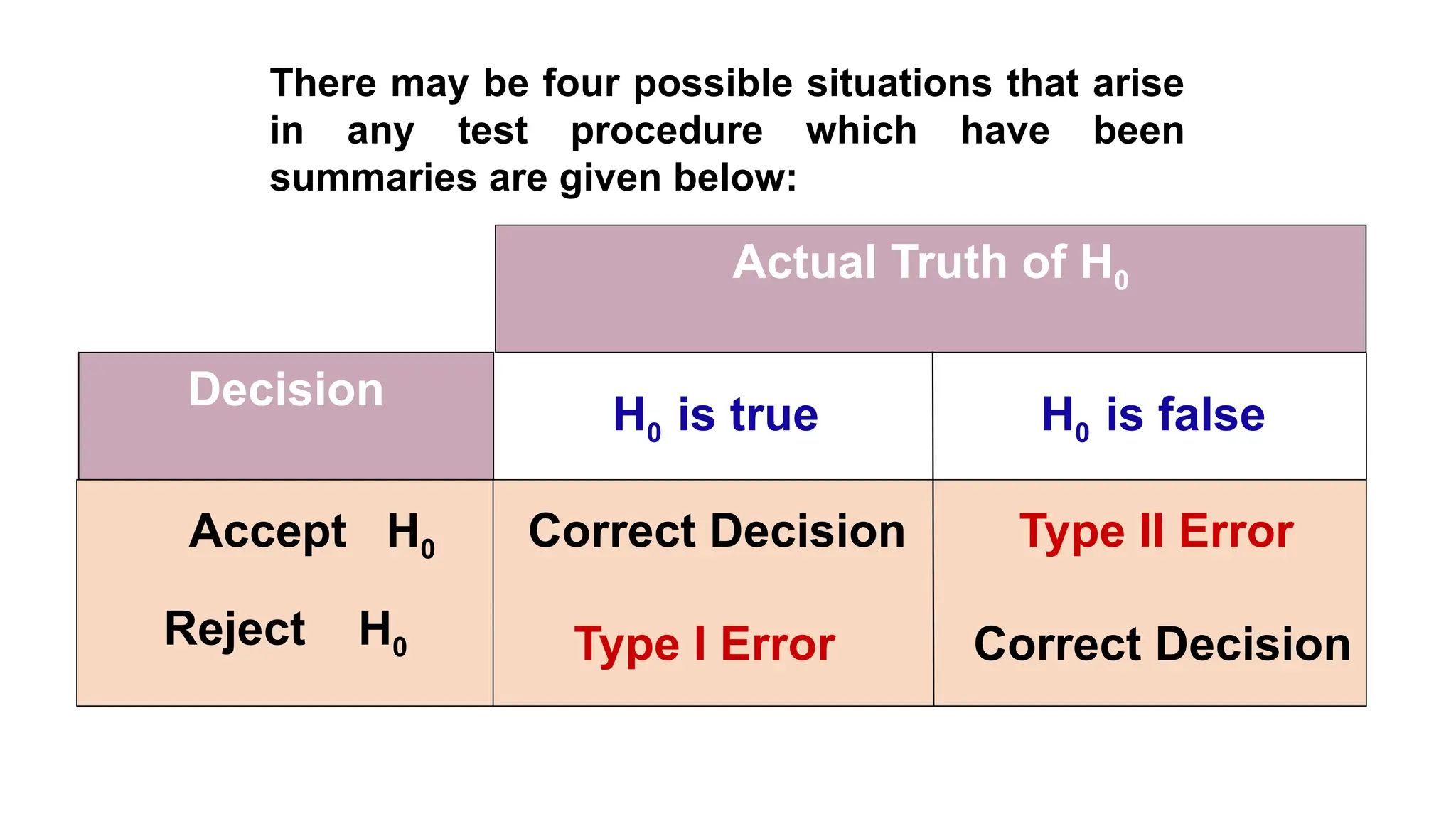
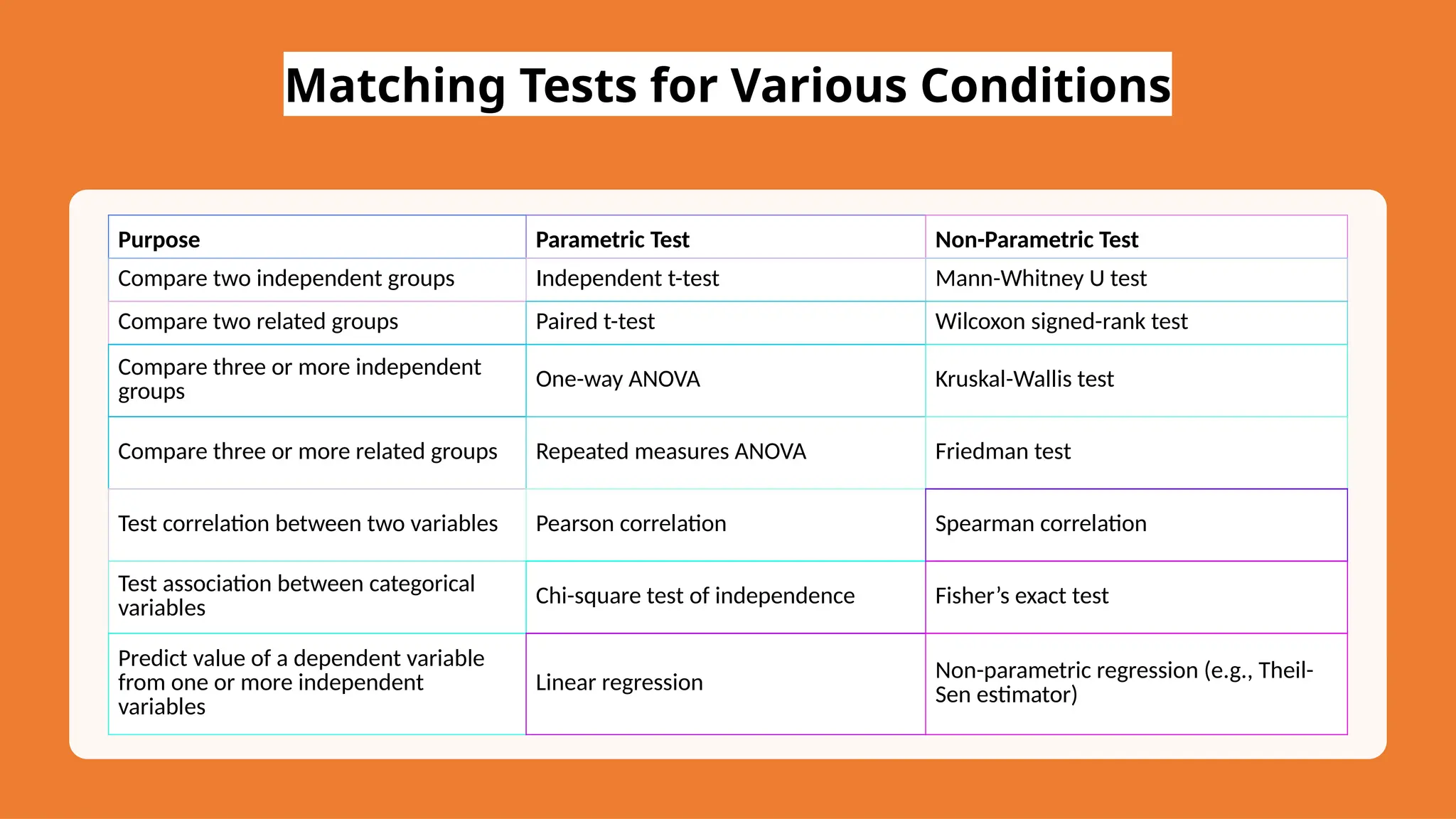
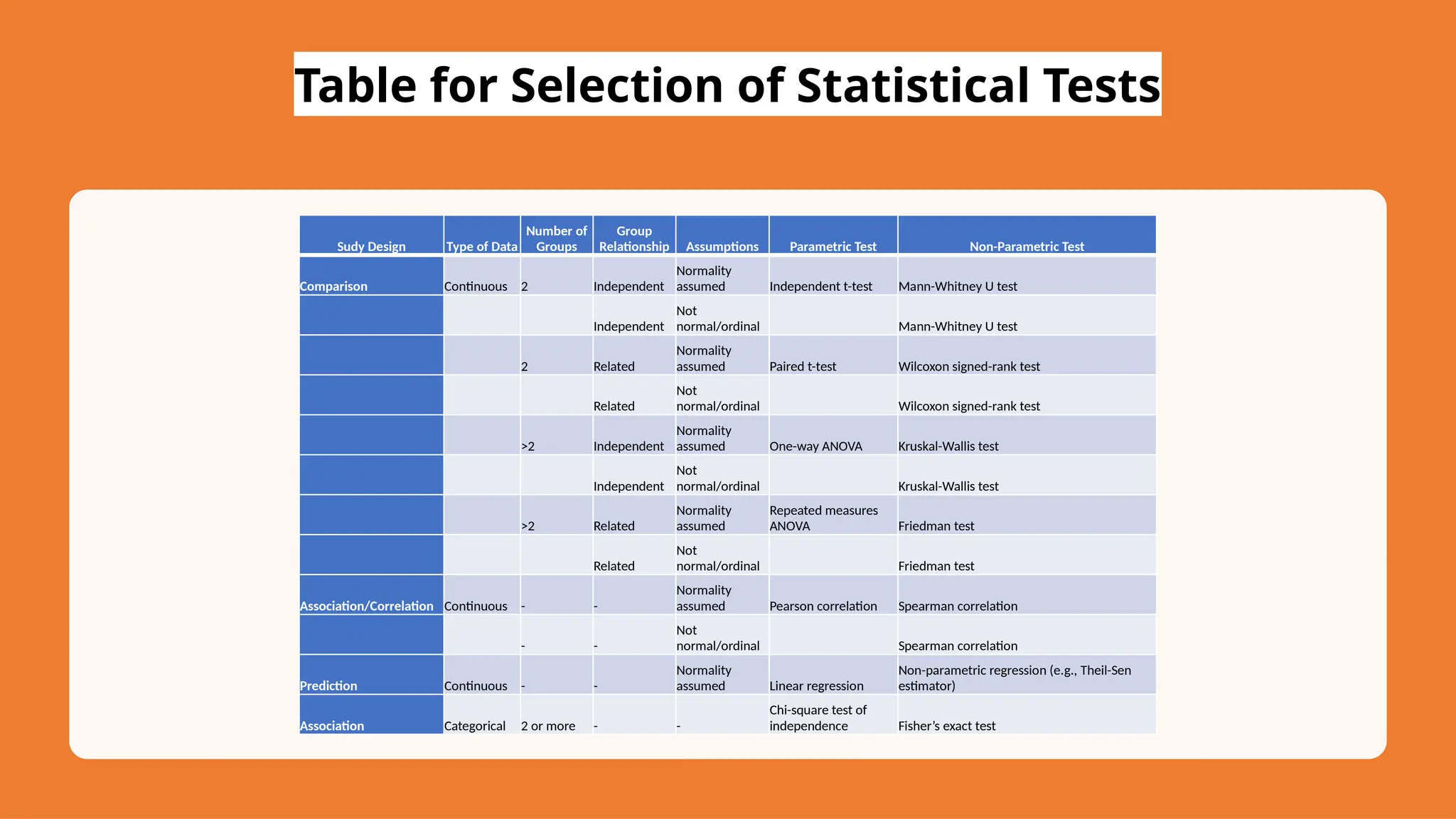
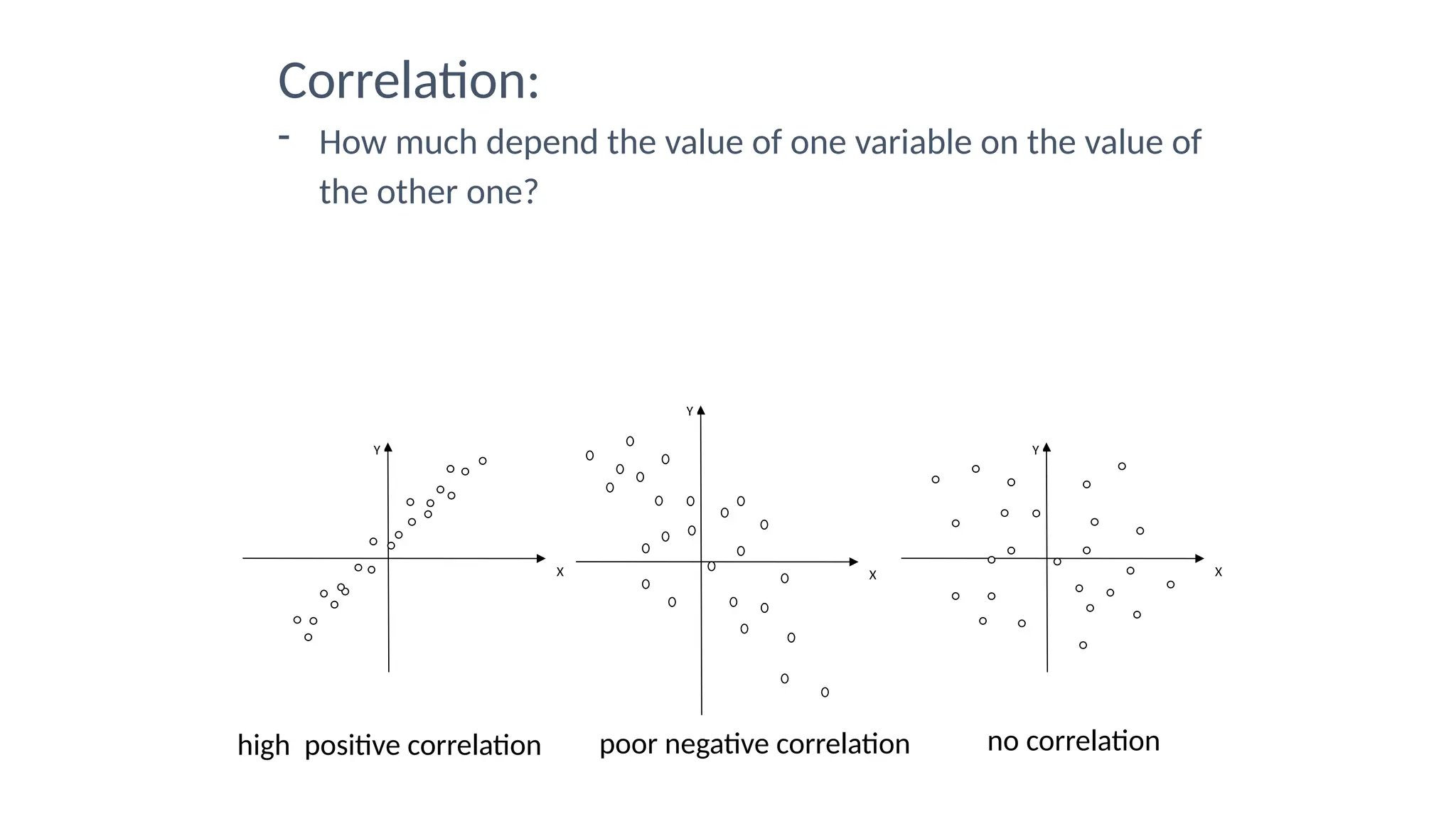
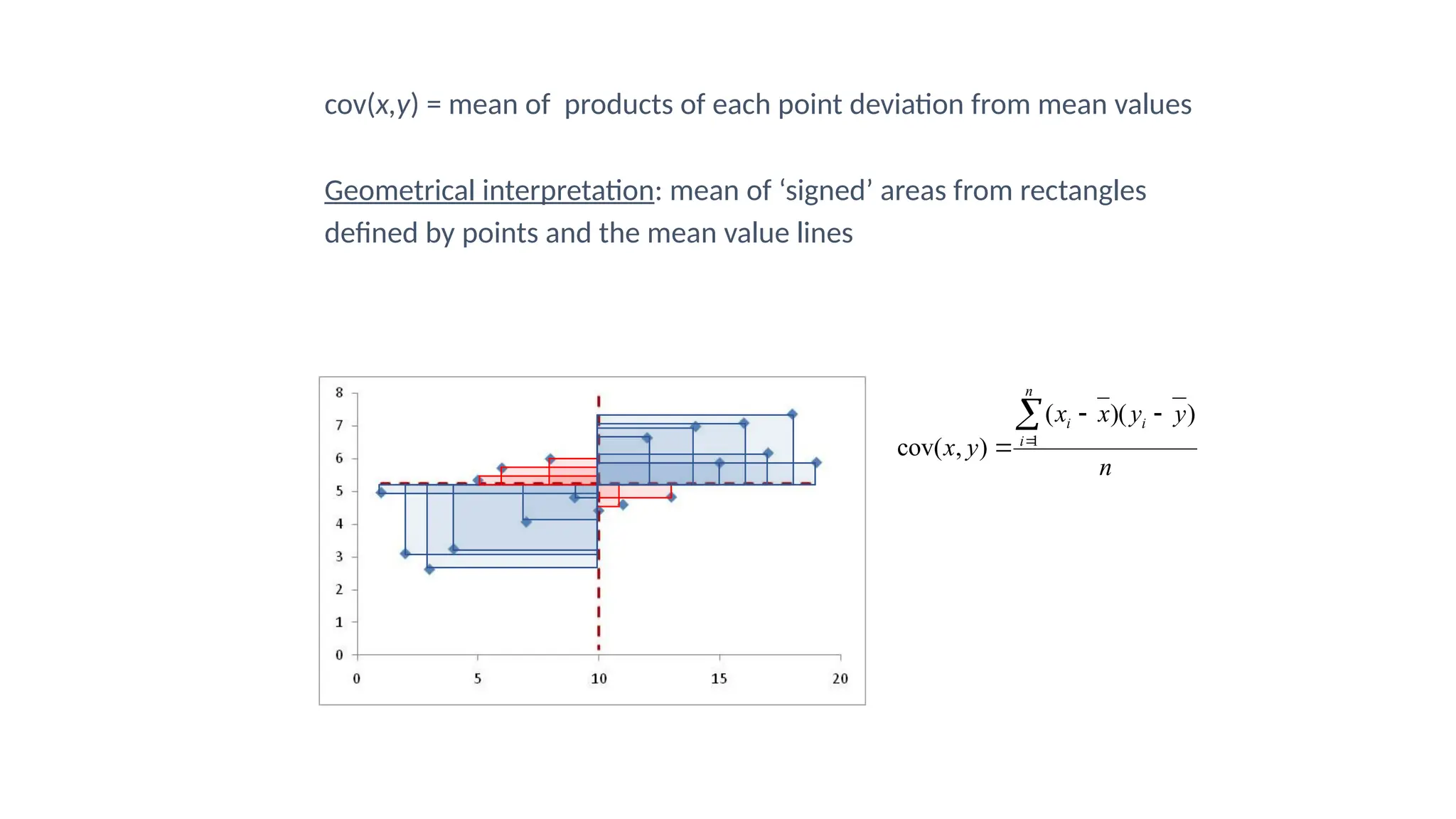
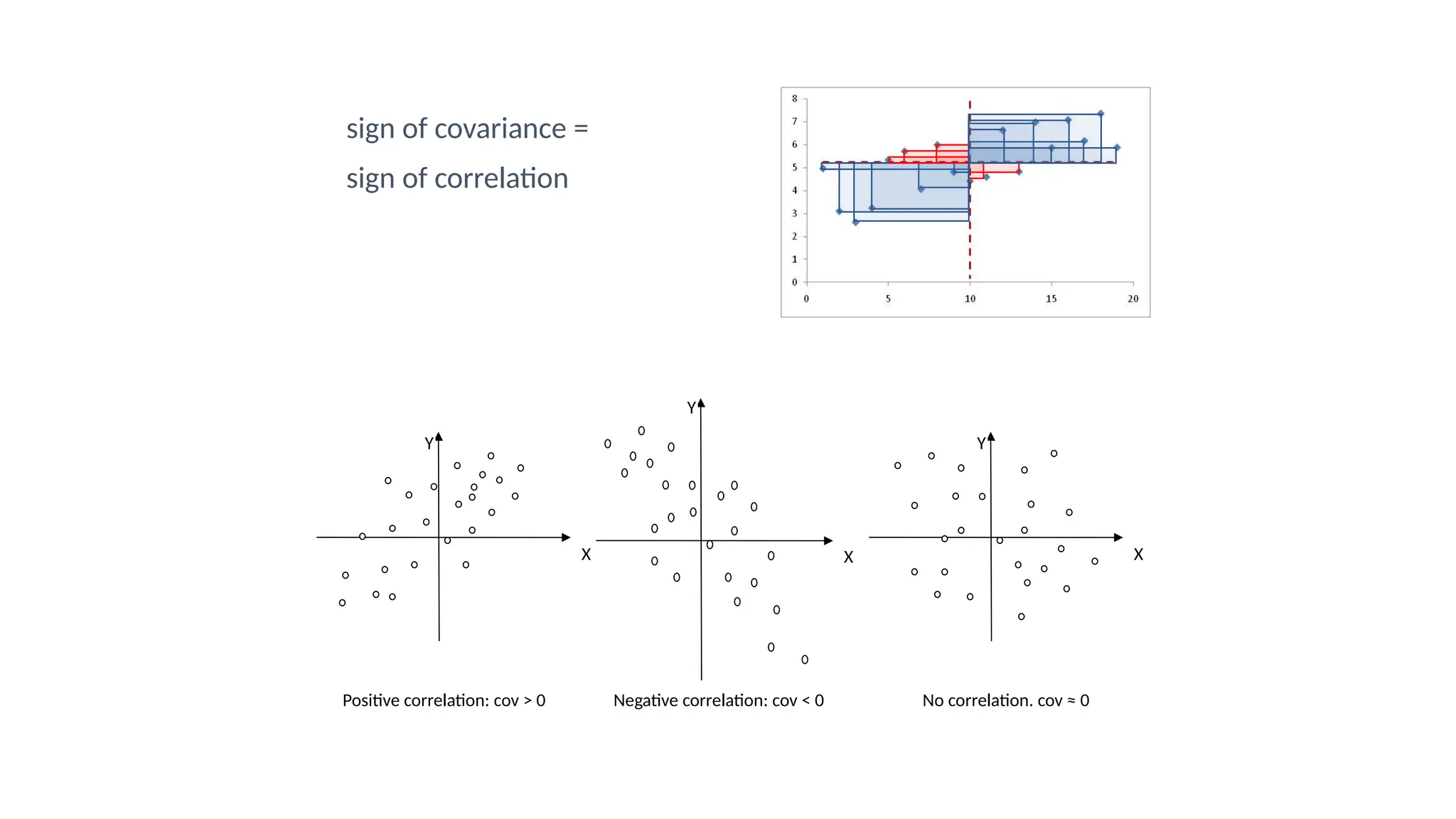
The document discusses hypothesis testing and inference, defining a hypothesis as a testable prediction regarding research outcomes, and outlining characteristics of good hypotheses. It elaborates on types of hypotheses, specifically null and alternative, detailing their roles in statistical decision-making, including test statistics, significance levels, and errors such as Type I and Type II. Additionally, it compares parametric and non-parametric testing methods and suggests approaches for selecting appropriate statistical tests based on data distribution and sample size.