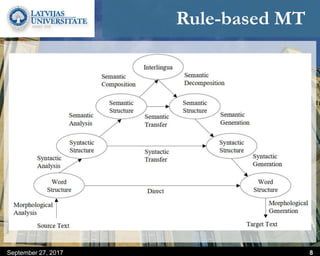
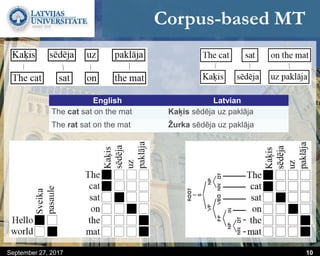
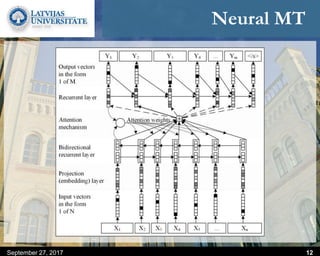
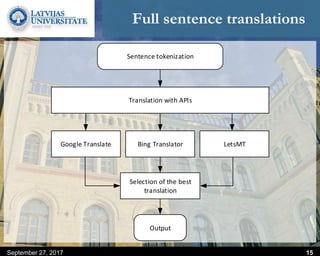
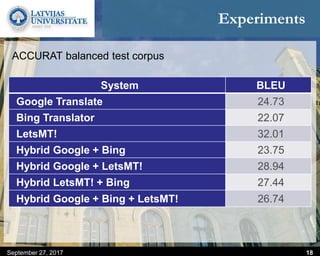
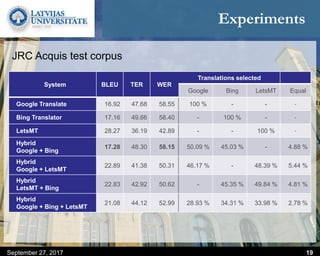
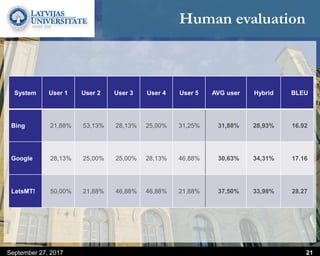
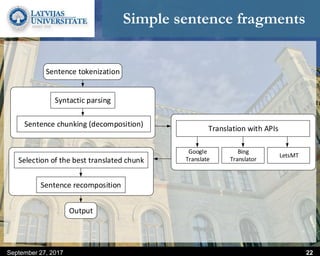
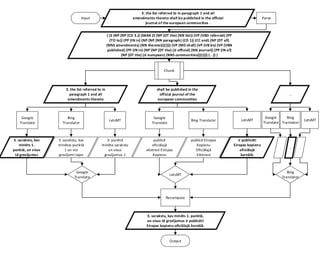
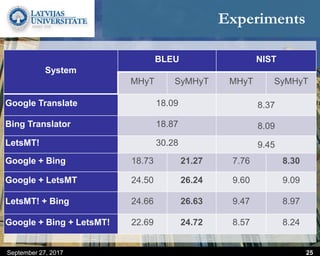
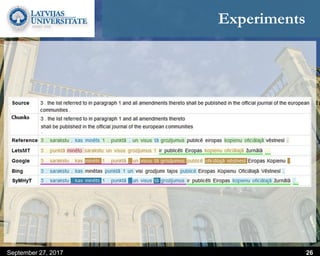
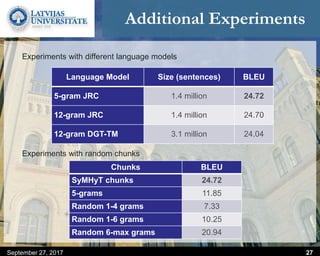
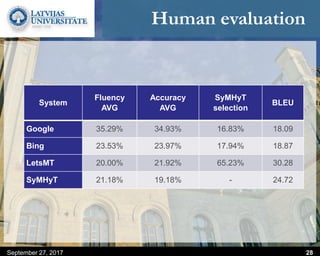
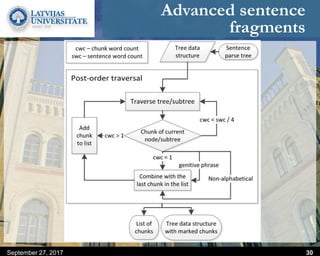
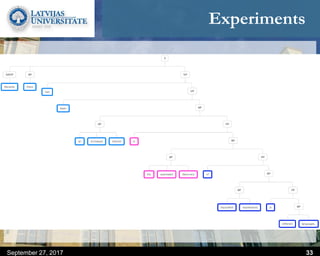
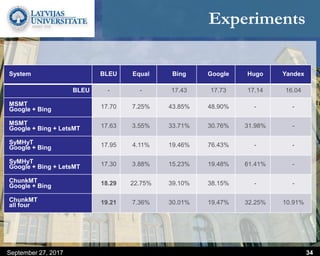
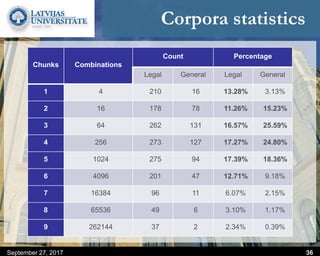
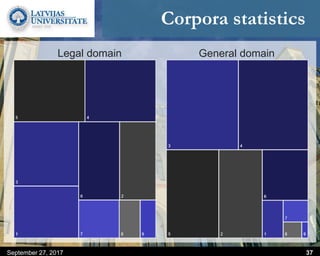
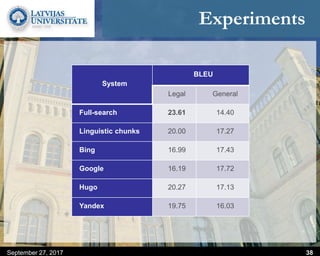
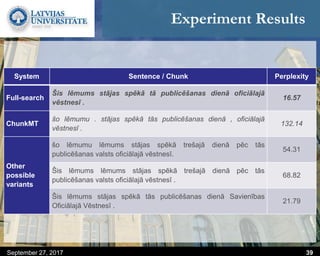
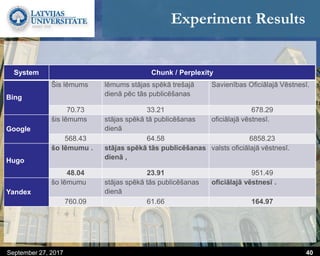
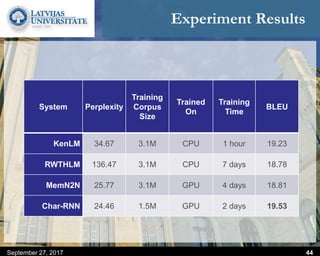
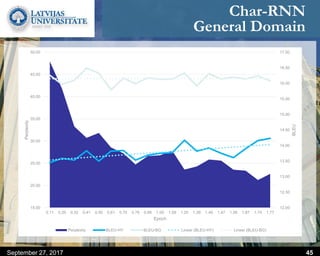
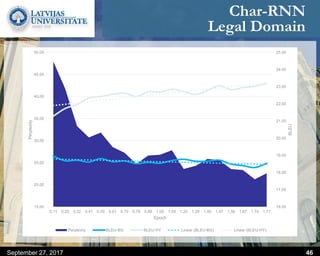
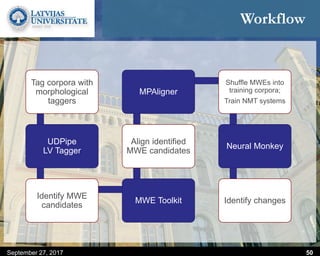
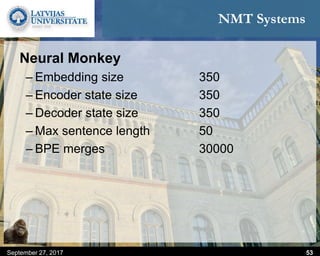
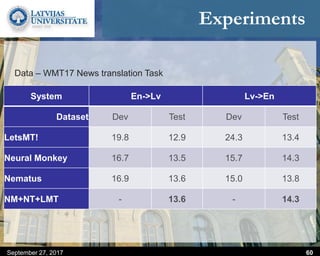
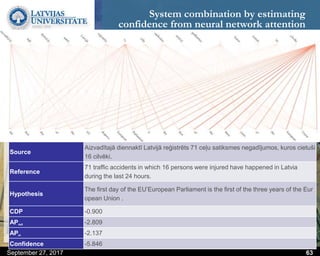
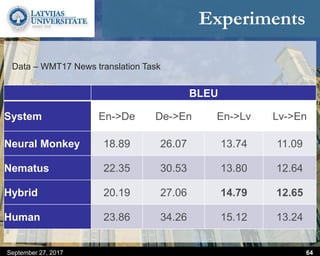
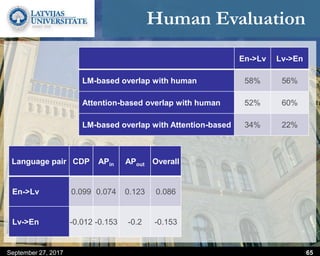
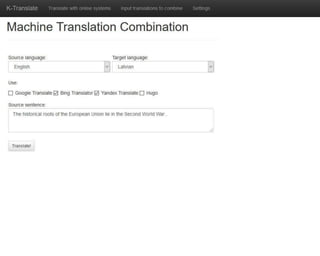
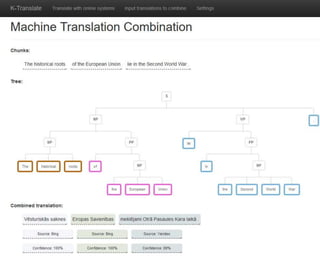
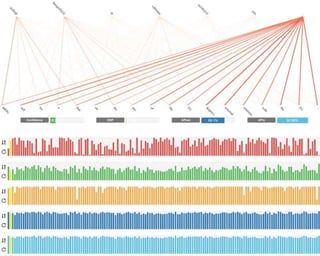
This document discusses methods for combining multiple machine translation systems to produce a superior final translation. It begins with introducing rule-based machine translation, statistical machine translation, and neural machine translation. Then it discusses various methods for combining outputs from different MT systems, including combining translations at the full sentence level, sentence fragment level using simple or advanced chunking, and exhaustive search. It presents experiments comparing the BLEU scores of single systems, dual/triple hybrid systems, and the full exhaustive search on various language corpora. The document aims to develop methods for combining Latvian and other morphologically rich and less-resourced language MT systems.