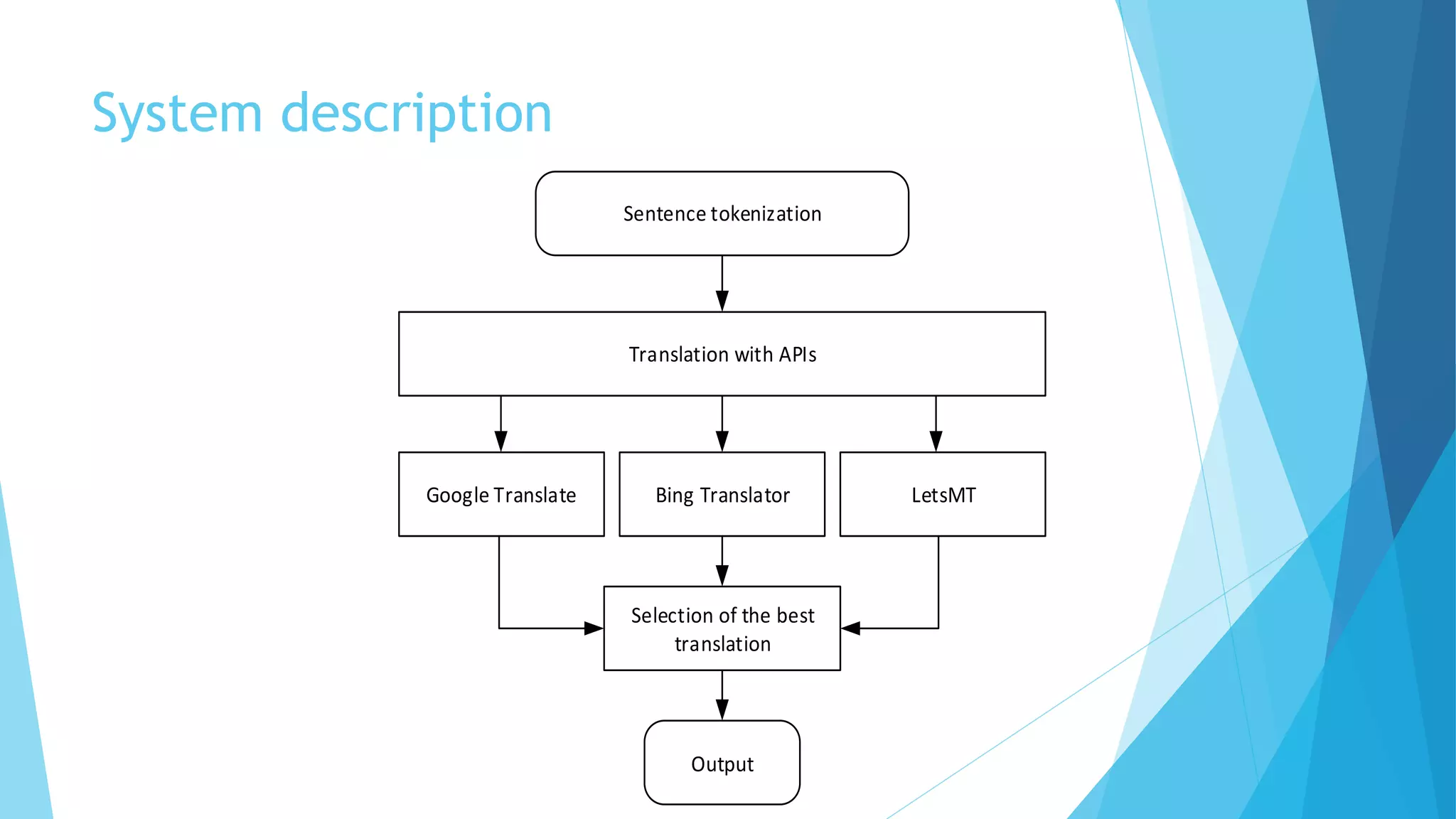
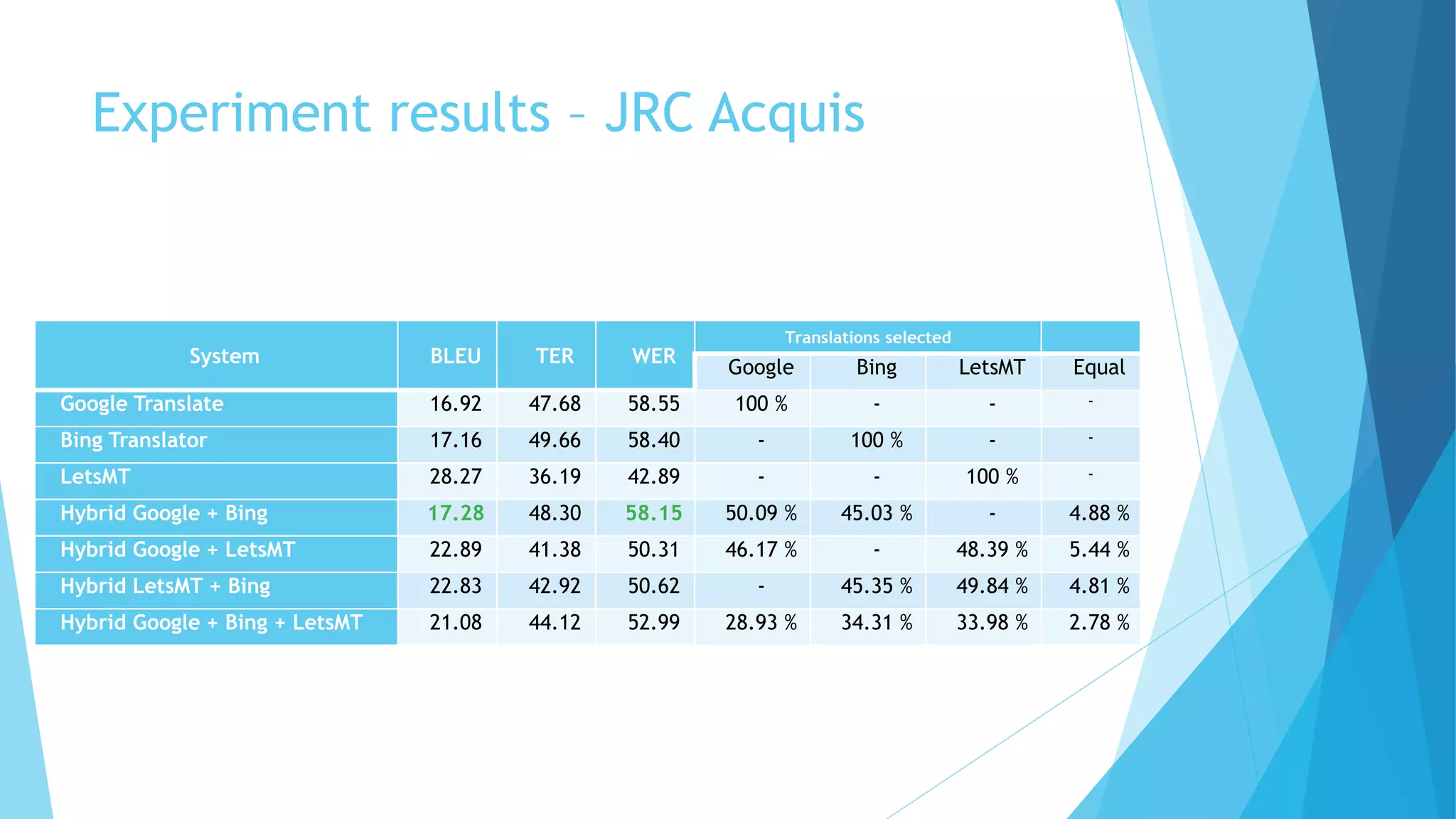
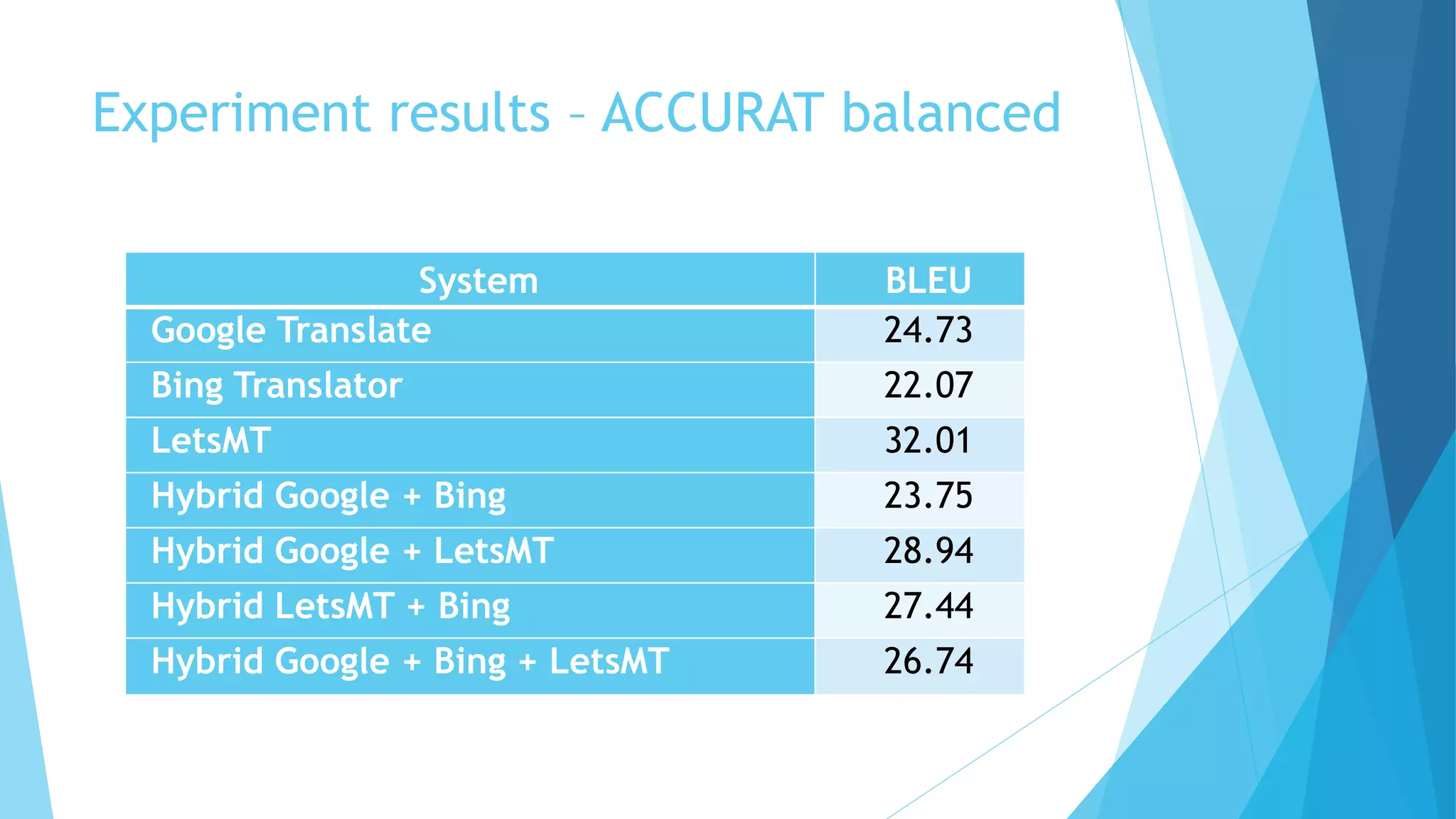
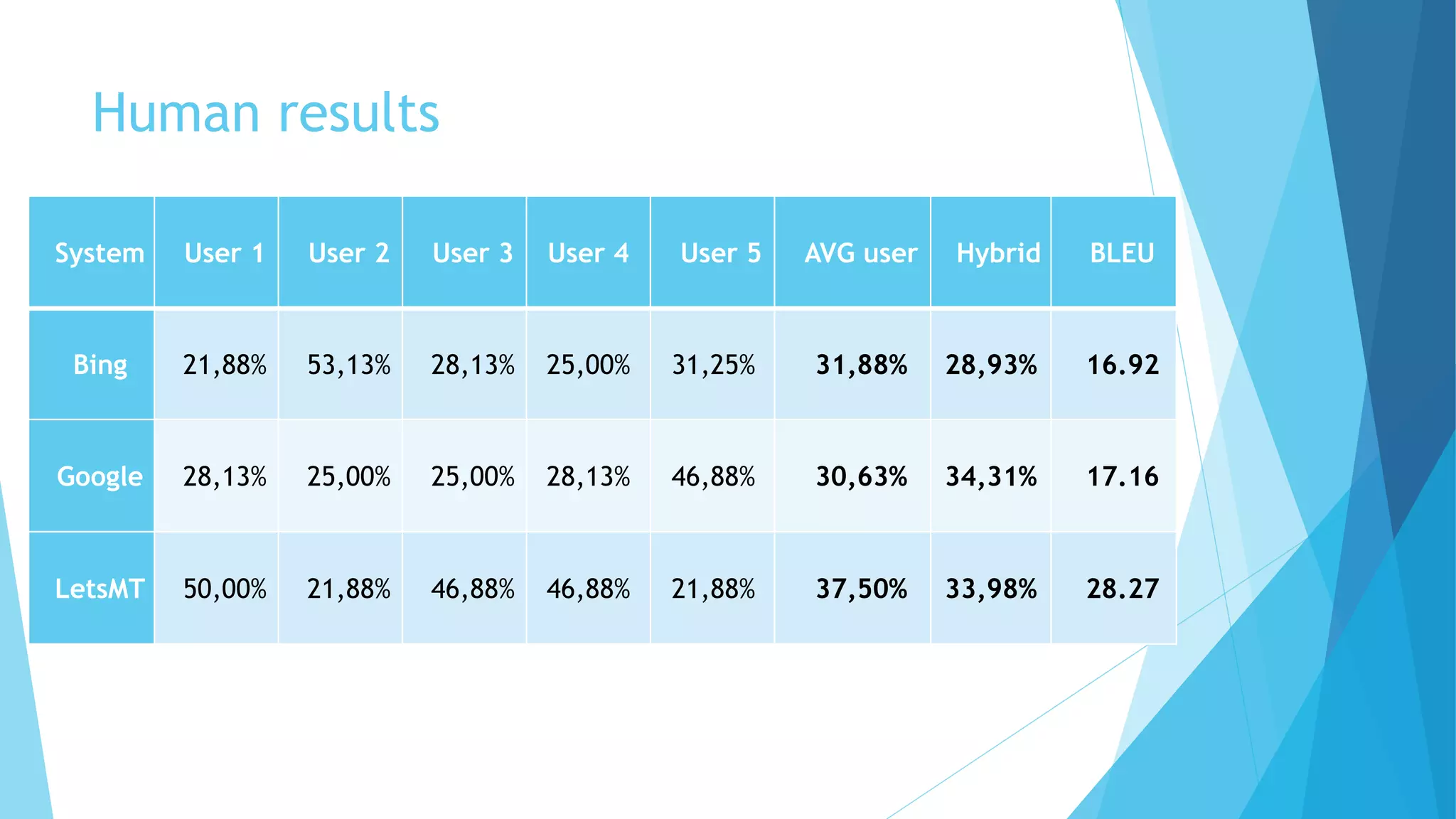
This document discusses a hybrid machine translation method developed by Matīss Rikters at the University of Latvia, focused on combining outputs from multiple online translation APIs for English-Latvian translations. The study explores various machine translation systems, presents experiments evaluating translation quality, and reports on results from human evaluations of machine-generated outputs. Conclusions include the need for improvements in translation selection and future work possibilities such as incorporating larger language models and better quality estimation methods.






















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)




