

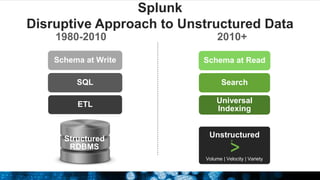
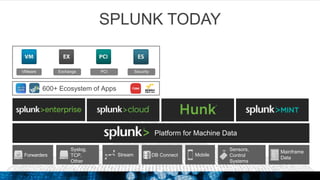

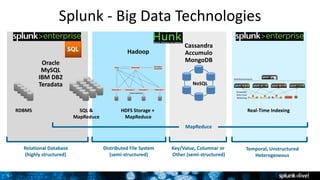
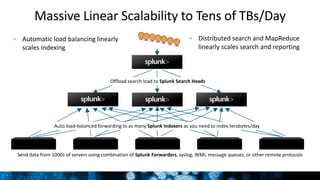
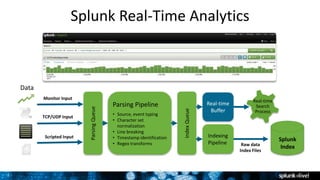

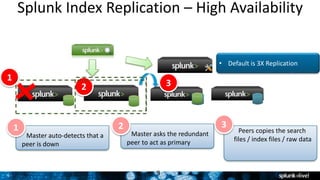

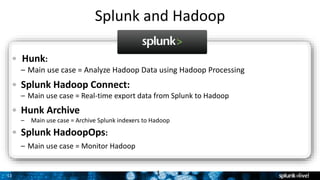


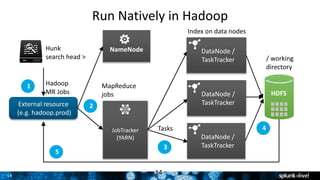
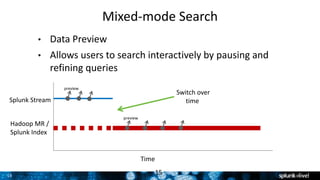
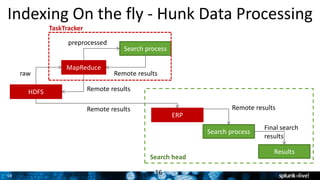
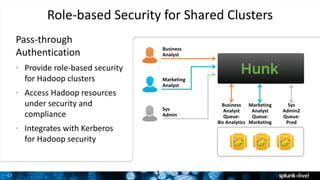
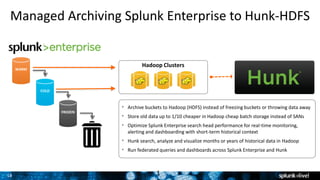

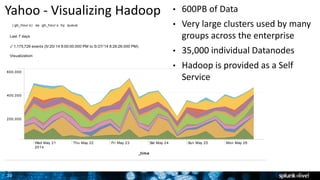



The document outlines Splunk's capabilities in big data analytics, emphasizing its ability to handle unstructured and structured data through a unique indexing approach. It details the integration of Splunk with Hadoop, highlighting functionalities such as data archiving, real-time analytics, and self-service capabilities for users. Key features include automatic load balancing, role-based security, and support for large data volumes across various platforms.






















































































