




![Hadoop in Real life
Using HunkMap Reduce Job for Hadoop
il.public class WordCount extends Configured implements Tool {
public static class Map extends MapReduceBase implements Mapper<LongWritable,
Text, Text, IntWritable> {static enum Counters { INPUT_WORDS }
• private Text word = new Text();
• private boolean caseSensitive = true;
• private Set<String> patternsToSkip = new HashSet<String>();
• private long numRecords = 0;
• private String inputFile;
• public void configure(JobConf job) {
• caseSensitive = job.getBoolean("wordcount.case.sensitive", true);
• inputFile = job.get("map.input.file");
• if (job.getBoolean("wordcount.skip.patterns", false)) {
• Path[] patternsFiles = new Path[0];
• try {
• patternsFiles = DistributedCache.getLocalCacheFiles(job);
• } catch (IOException ioe) {
• System.err.println("Caught exception while getting cached files: " +
StringUtils.stringifyException(ioe));
• }
• for (Path patternsFile : patternsFiles) {
• parseSkipFile(patternsFile);
• }
• }
• Index=Hadoop
• |wc usestopwords=f
• |stats sum(count) by word](https://image.slidesharecdn.com/hunkoverviewsplunklive-140408070716-phpapp01/85/Hunk-Splunk-Analytics-for-Hadoop-8-320.jpg)











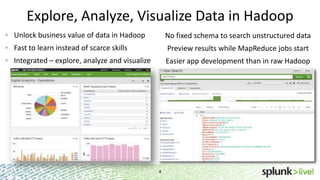
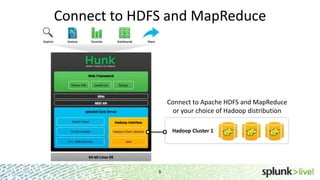
This document provides an overview of Hunk, an analytics platform for exploring, analyzing, and visualizing data stored in Hadoop. It discusses how Hunk allows users to connect to HDFS and MapReduce, create virtual indexes, use MapReduce as an orchestration framework, and search data in Hadoop. The document also highlights how Hunk provides an easier, more flexible workflow for business users compared to traditional Hadoop approaches.























































































