








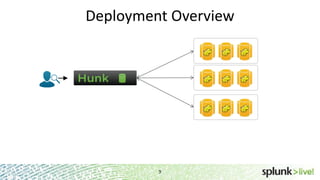


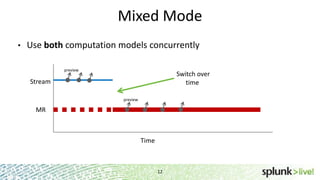
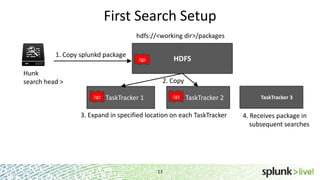

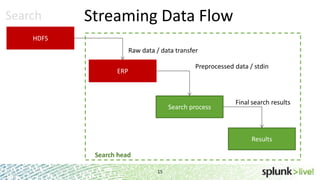
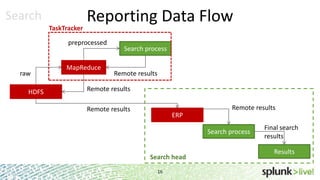
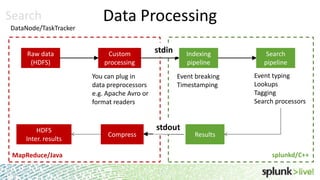
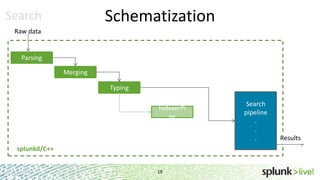






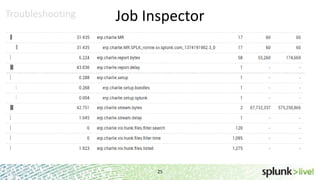




During the course of this presentation, forward-looking statements were made regarding Splunk's expected performance and legal notices were provided. The presentation discussed using Splunk to analyze large amounts of data stored in Hadoop by moving computation to the data through MapReduce jobs while supporting Splunk Processing Language and maintaining schema on read. Optimization techniques like partition pruning were covered to improve performance as well as best practices, troubleshooting tips, and resources for using Hunk.























































































