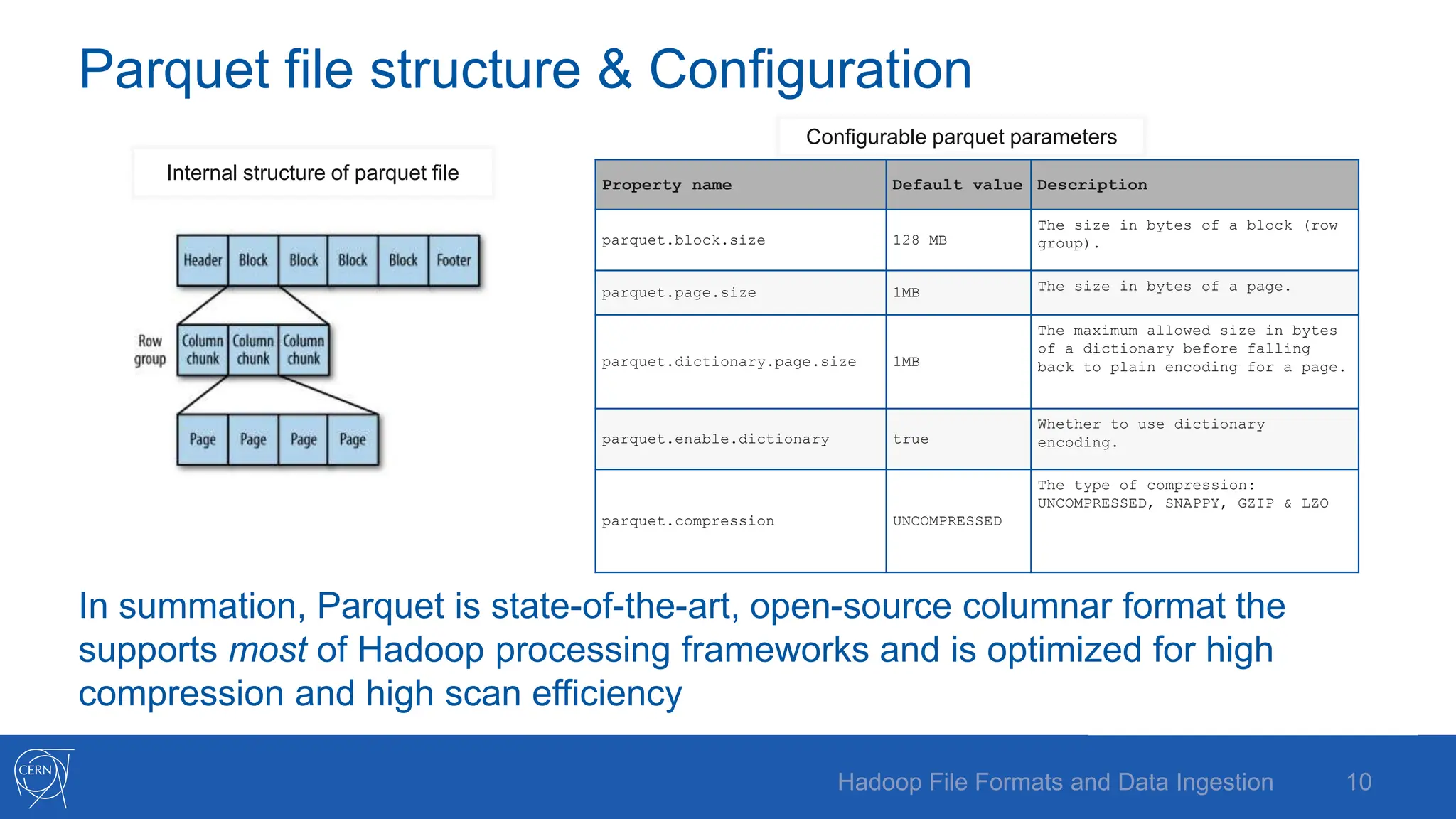
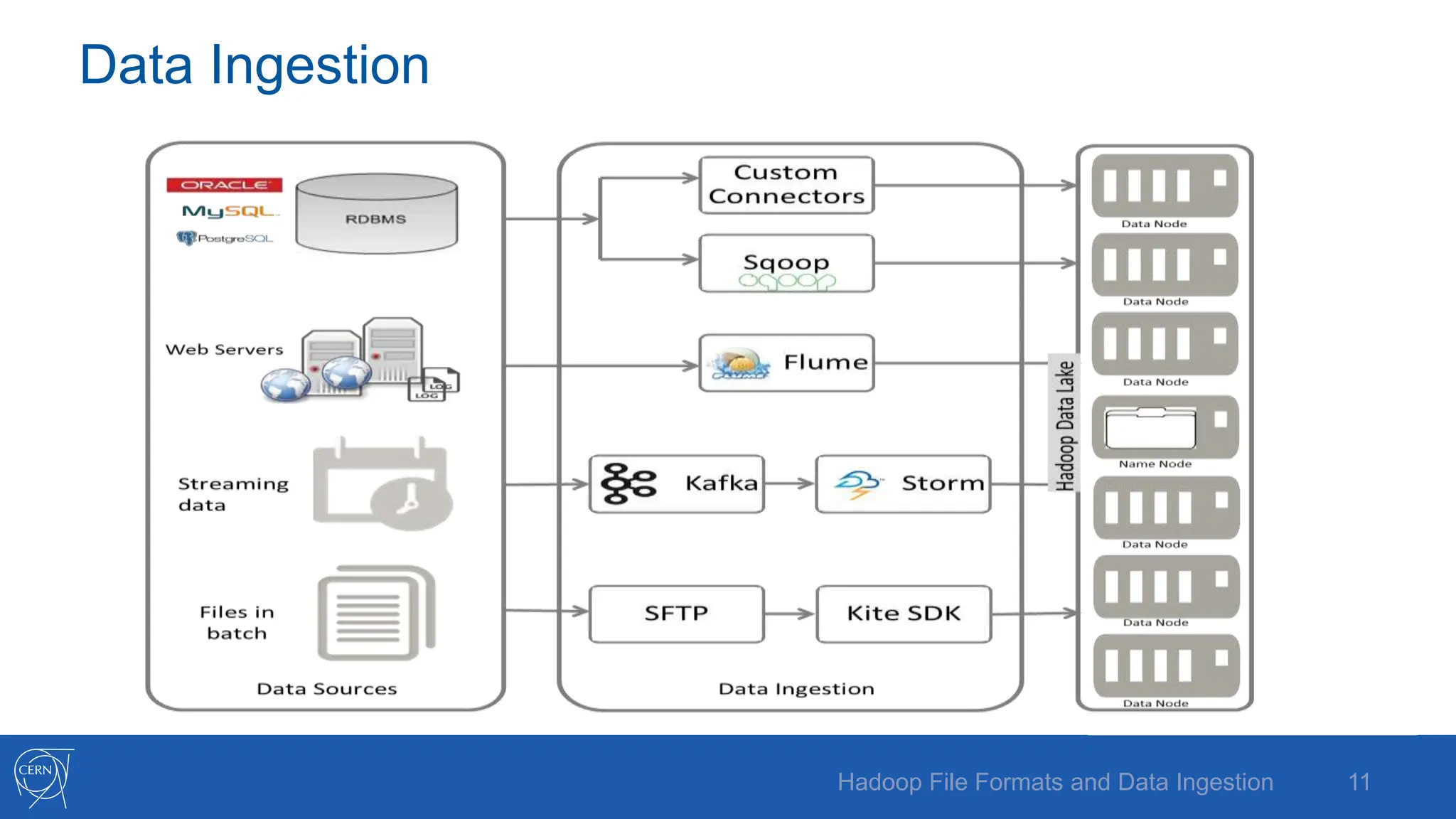
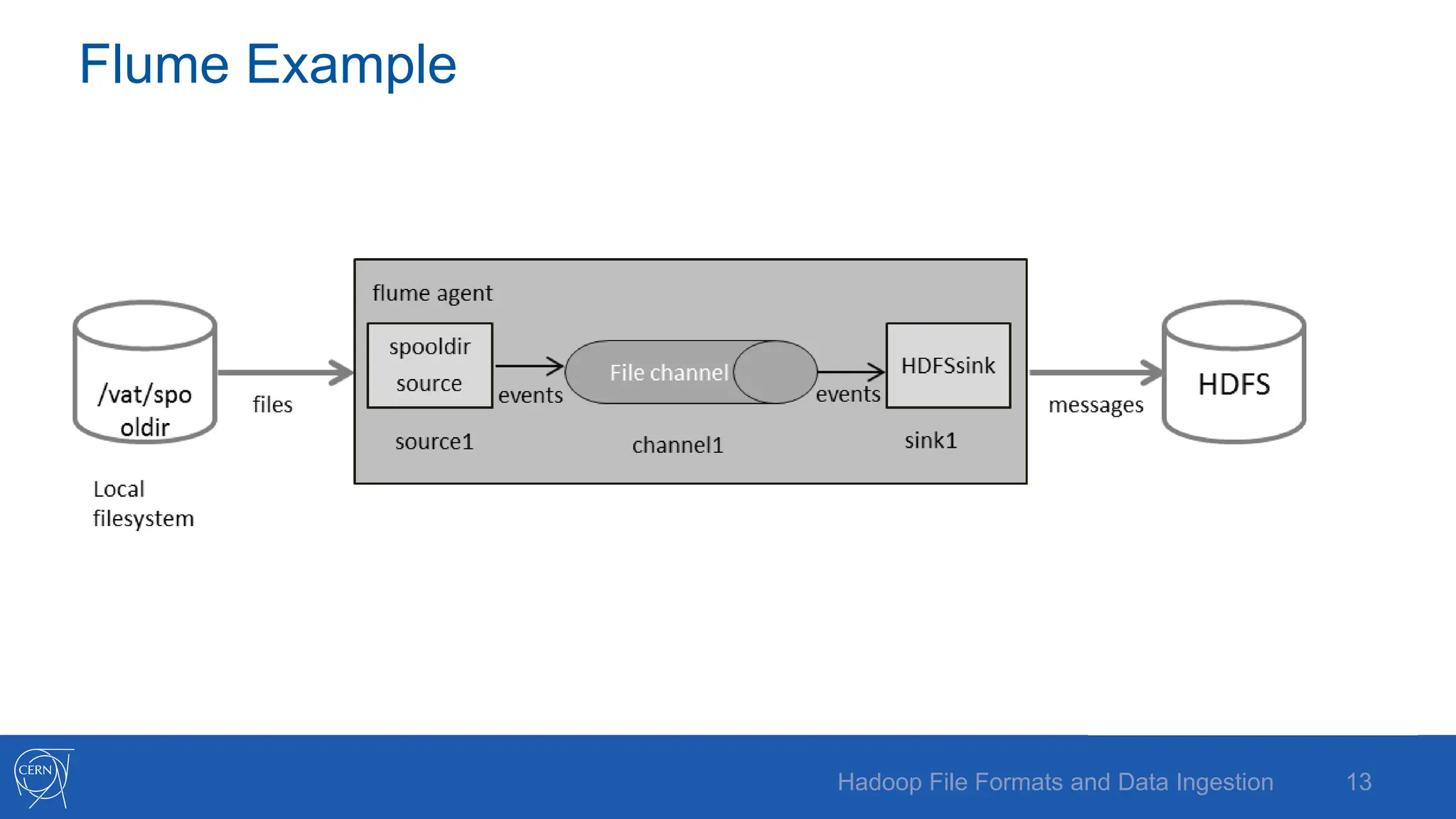
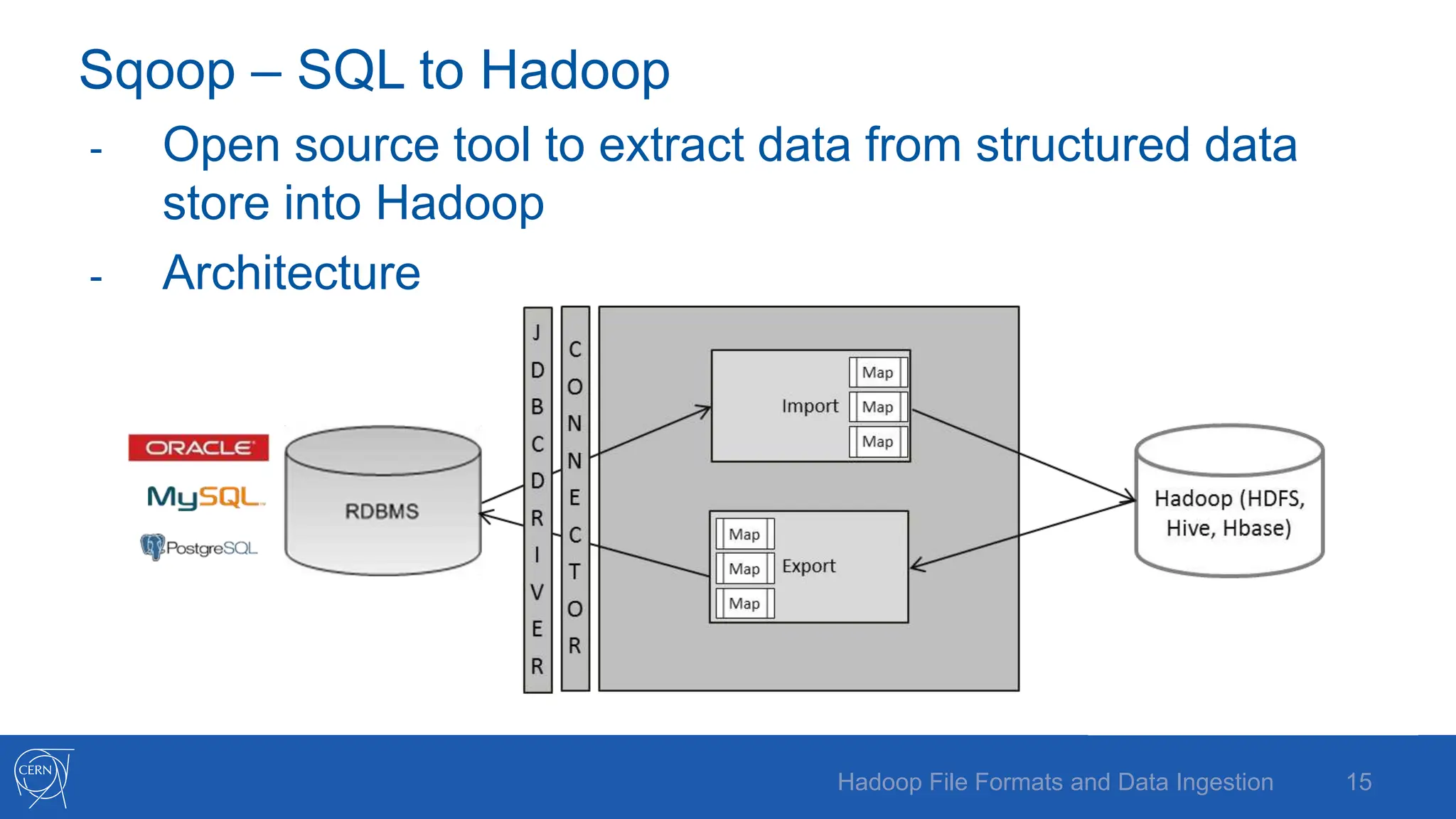
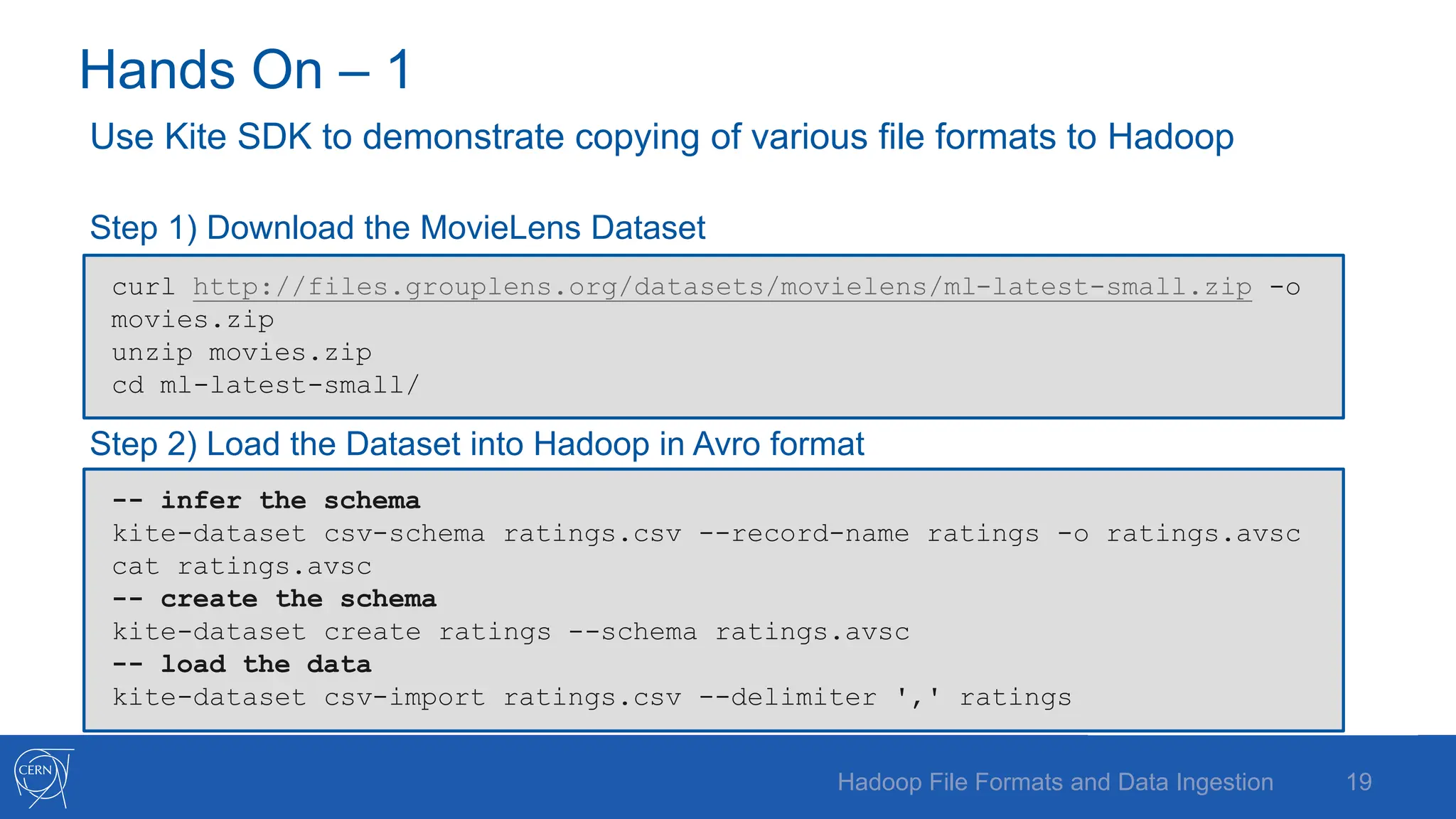
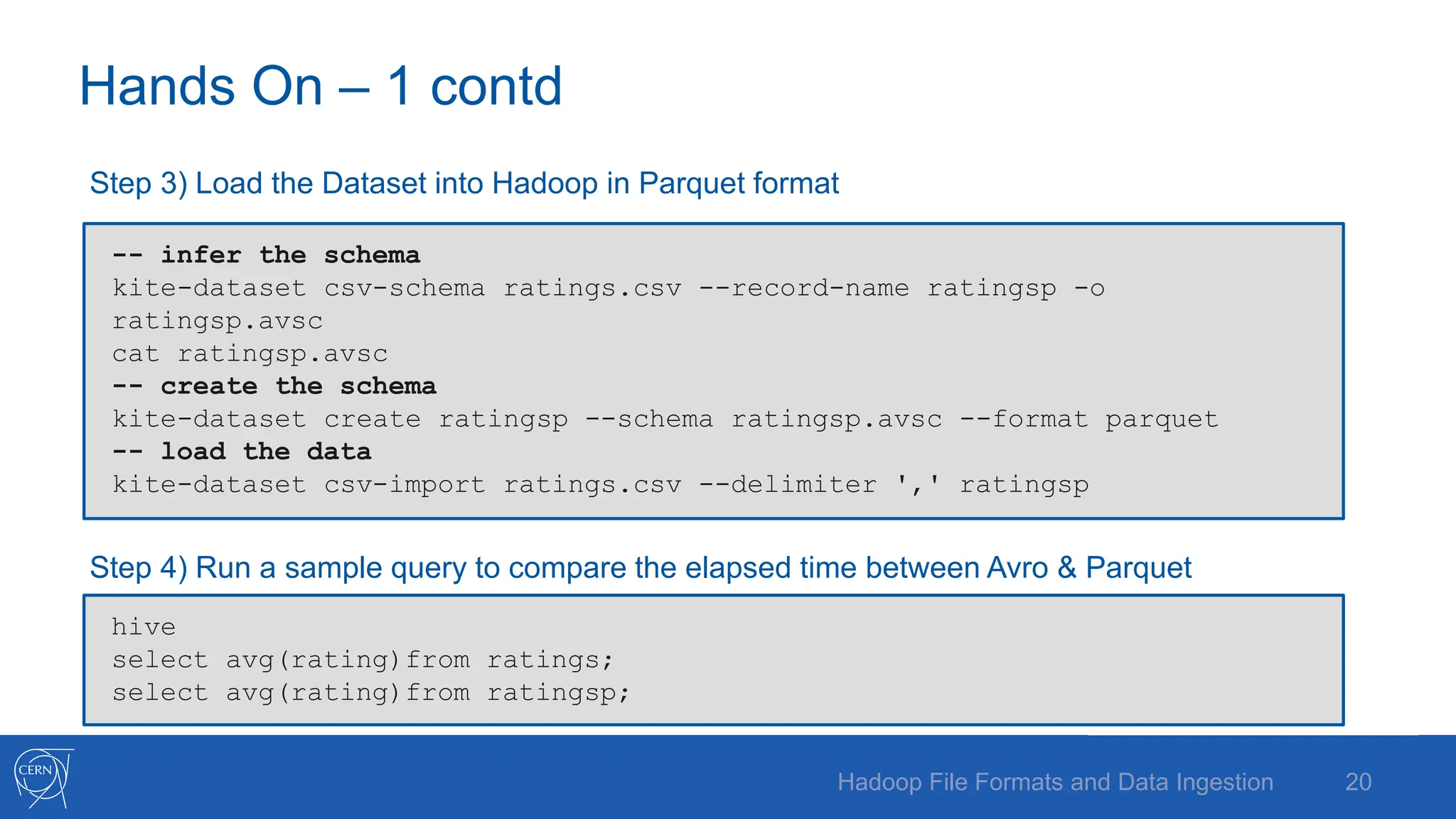
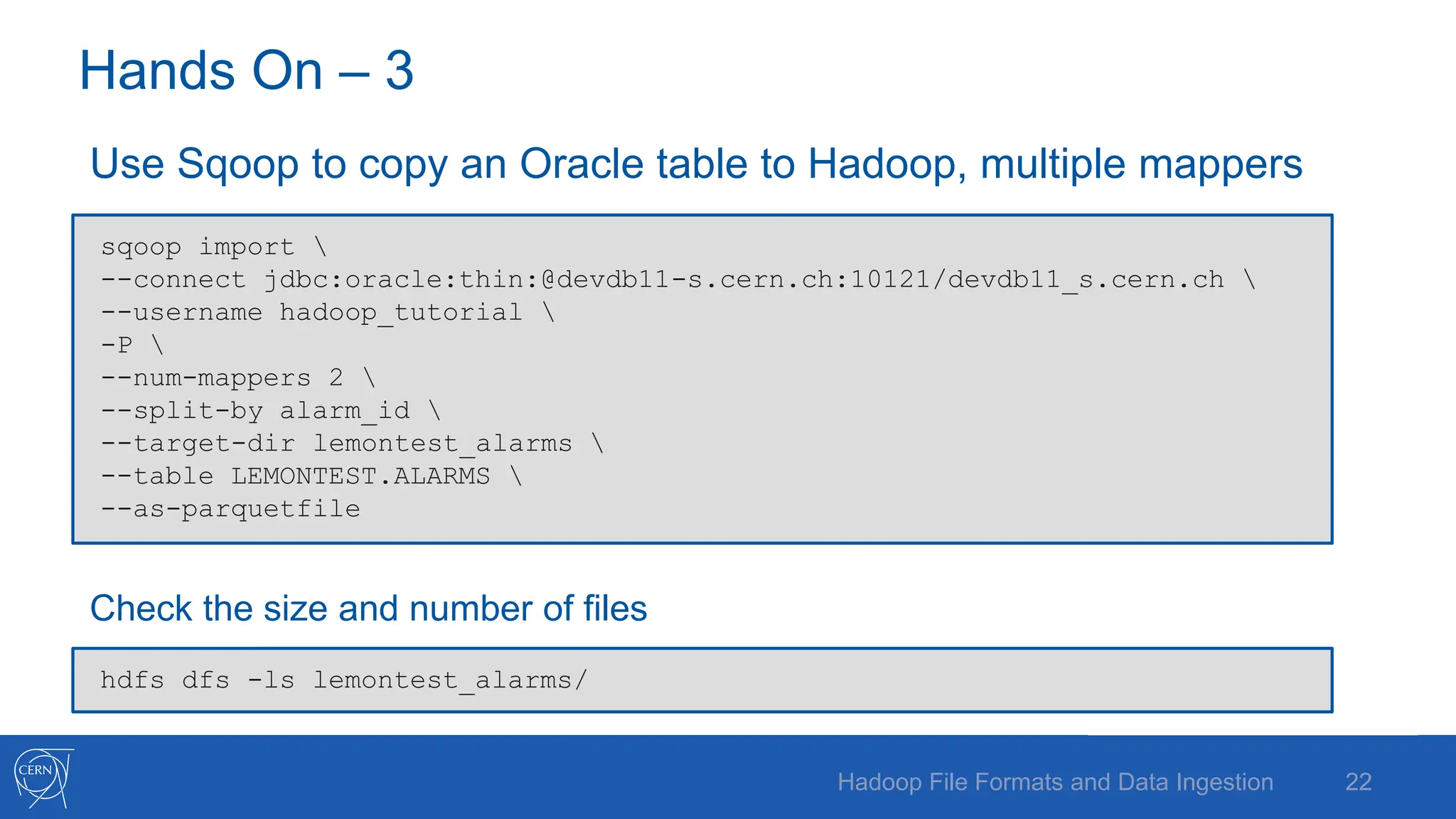
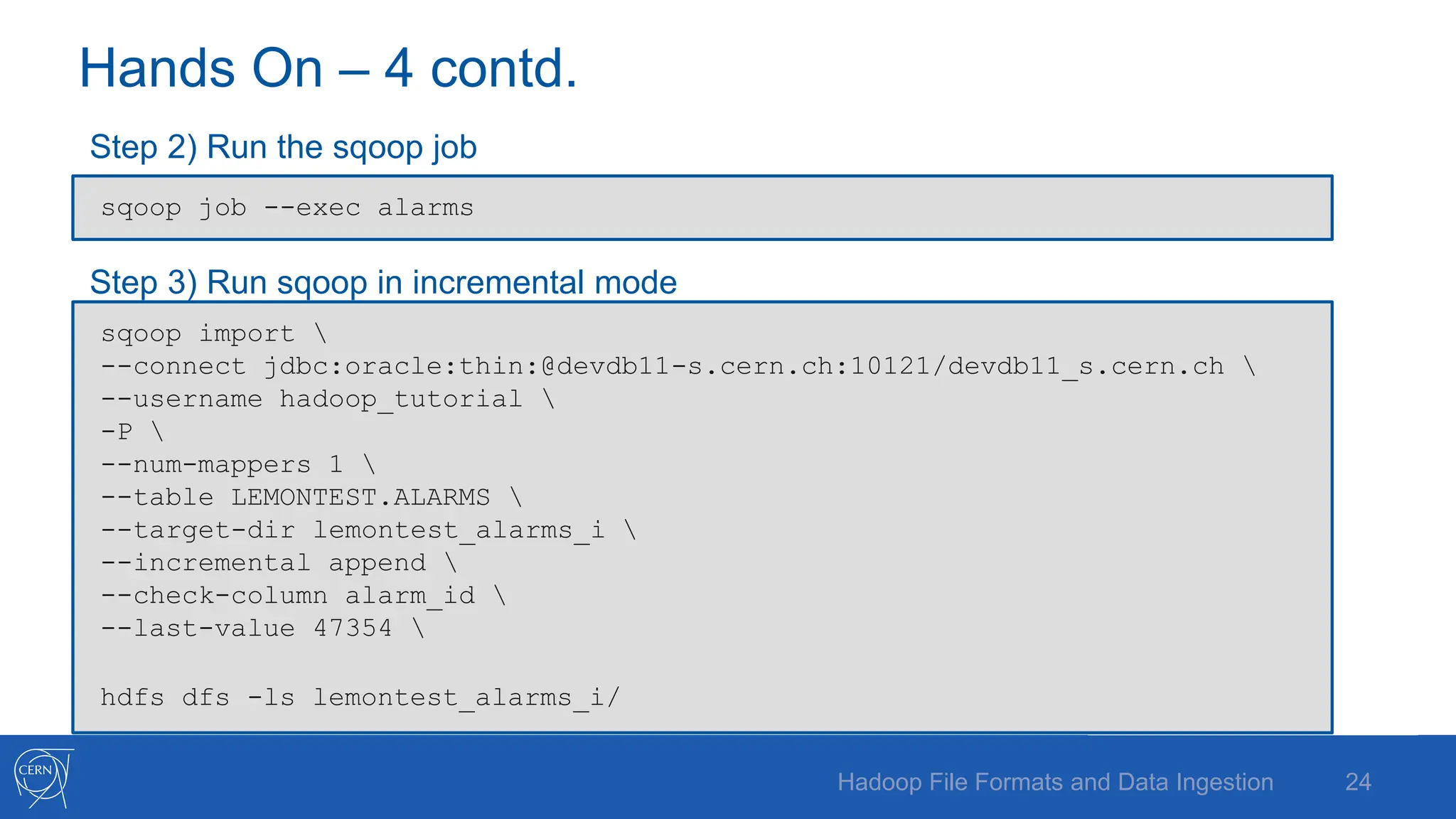
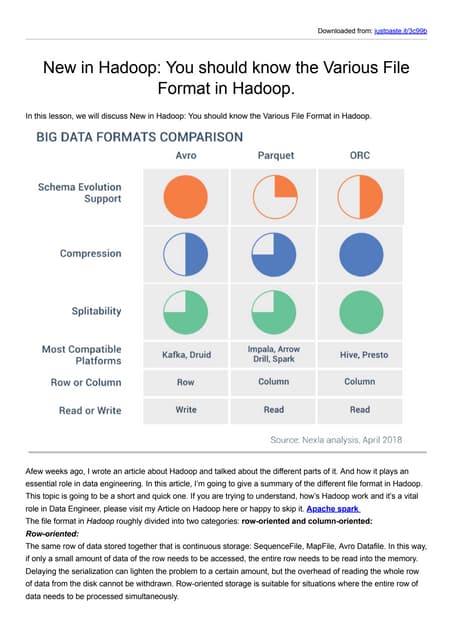
The document discusses various Hadoop file formats and the data ingestion processes essential for big data processing, emphasizing the significance of schema evolution, compression, and reading performance. Key formats such as Avro, Parquet, and ORC are highlighted, with details on their structures, advantages, and configurations. It also introduces tools like Flume for high-volume data ingestion and Sqoop for transferring structured data to Hadoop, including hands-on examples for practical application.





![Avro – File structure and example
Sample AVRO schema in JSON format Avro file structure
{
"type" : "record",
"name" : "tweets",
"fields" : [ {
"name" : "username",
"type" : "string",
}, {
"name" : "tweet",
"type" : "string",
}, {
"name" : "timestamp",
"type" : "long",
} ],
"doc:" : “schema for storing tweets"
}
Hadoop File Formats and Data Ingestion 6](https://image.slidesharecdn.com/hadoopfileformatsanddataingestion-240606030720-fd05eccb/75/Hadoop_File_Formats_and_Data_Ingestion-pptx-6-2048.jpg)